 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRadAdapt: Radiology Report Summarization via Lightweight Domain Adaptation of Large Language Models
Paper and Code
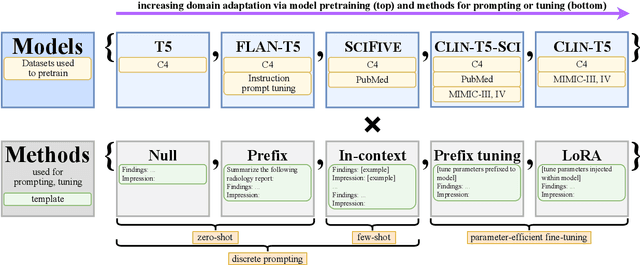
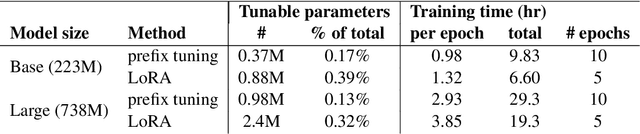
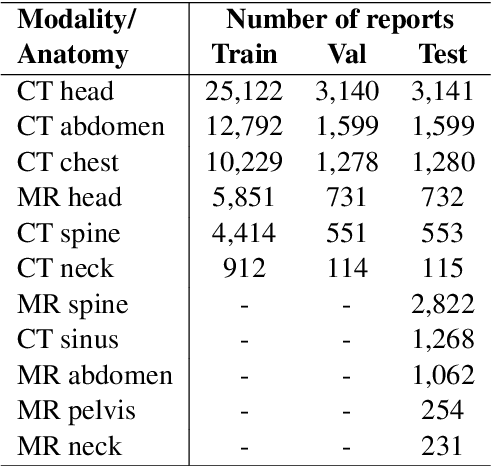

We systematically investigate lightweight strategies to adapt large language models (LLMs) for the task of radiology report summarization (RRS). Specifically, we focus on domain adaptation via pretraining (on natural language, biomedical text, and clinical text) and via prompting (zero-shot, in-context learning) or parameter-efficient fine-tuning (prefix tuning, LoRA). Our results on the MIMIC-III dataset consistently demonstrate best performance by maximally adapting to the task via pretraining on clinical text and parameter-efficient fine-tuning on RRS examples. Importantly, this method fine-tunes a mere 0.32% of parameters throughout the model, in contrast to end-to-end fine-tuning (100% of parameters). Additionally, we study the effect of in-context examples and out-of-distribution (OOD) training before concluding with a radiologist reader study and qualitative analysis. Our findings highlight the importance of domain adaptation in RRS and provide valuable insights toward developing effective natural language processing solutions for clinical tasks.