 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving the Performance of Radiology Report De-identification with Large-Scale Training and Benchmarking Against Cloud Vendor Methods
Nov 06, 2025


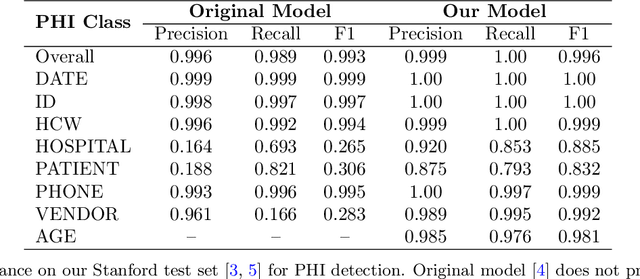
Objective: To enhance automated de-identification of radiology reports by scaling transformer-based models through extensive training datasets and benchmarking performance against commercial cloud vendor systems for protected health information (PHI) detection. Materials and Methods: In this retrospective study, we built upon a state-of-the-art, transformer-based, PHI de-identification pipeline by fine-tuning on two large annotated radiology corpora from Stanford University, encompassing chest X-ray, chest CT, abdomen/pelvis CT, and brain MR reports and introducing an additional PHI category (AGE) into the architecture. Model performance was evaluated on test sets from Stanford and the University of Pennsylvania (Penn) for token-level PHI detection. We further assessed (1) the stability of synthetic PHI generation using a "hide-in-plain-sight" method and (2) performance against commercial systems. Precision, recall, and F1 scores were computed across all PHI categories. Results: Our model achieved overall F1 scores of 0.973 on the Penn dataset and 0.996 on the Stanford dataset, outperforming or maintaining the previous state-of-the-art model performance. Synthetic PHI evaluation showed consistent detectability (overall F1: 0.959 [0.958-0.960]) across 50 independently de-identified Penn datasets. Our model outperformed all vendor systems on synthetic Penn reports (overall F1: 0.960 vs. 0.632-0.754). Discussion: Large-scale, multimodal training improved cross-institutional generalization and robustness. Synthetic PHI generation preserved data utility while ensuring privacy. Conclusion: A transformer-based de-identification model trained on diverse radiology datasets outperforms prior academic and commercial systems in PHI detection and establishes a new benchmark for secure clinical text processing.
Exploring the Versatility of Zero-Shot CLIP for Interstitial Lung Disease Classification
Jun 01, 2023



Interstitial lung diseases (ILD) present diagnostic challenges due to their varied manifestations and overlapping imaging features. To address this, we propose a machine learning approach that utilizes CLIP, a multimodal (image and text) self-supervised model, for ILD classification. We extensively integrate zero-shot CLIP throughout our workflow, starting from the initial extraction of image patches from volumetric CT scans and proceeding to ILD classification using "patch montages". Furthermore, we investigate how domain adaptive pretraining (DAPT) CLIP with task-specific images (CT "patch montages" extracted with ILD-specific prompts for CLIP) and/or text (lung-specific sections of radiology reports) affects downstream ILD classification performance. By leveraging CLIP-extracted "patch montages" and DAPT, we achieve strong zero-shot ILD classification results, including an AUROC of 0.893, without the need for any labeled training data. This work highlights the versatility and potential of multimodal models like CLIP for medical image classification tasks where labeled data is scarce.
RadAdapt: Radiology Report Summarization via Lightweight Domain Adaptation of Large Language Models
May 02, 2023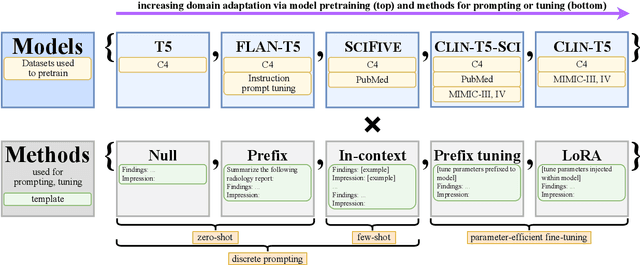
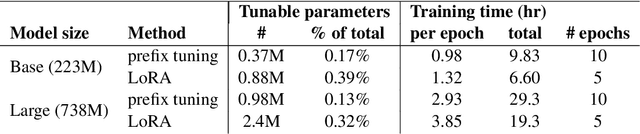
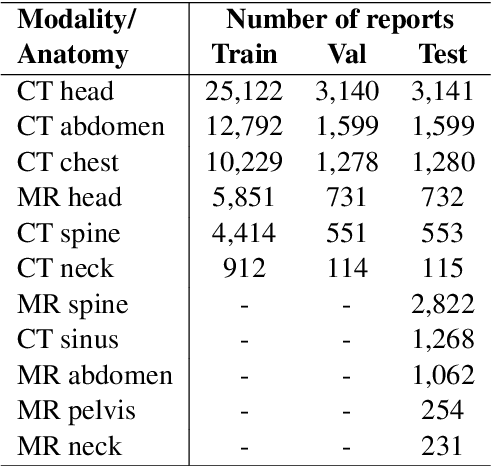

We systematically investigate lightweight strategies to adapt large language models (LLMs) for the task of radiology report summarization (RRS). Specifically, we focus on domain adaptation via pretraining (on natural language, biomedical text, and clinical text) and via prompting (zero-shot, in-context learning) or parameter-efficient fine-tuning (prefix tuning, LoRA). Our results on the MIMIC-III dataset consistently demonstrate best performance by maximally adapting to the task via pretraining on clinical text and parameter-efficient fine-tuning on RRS examples. Importantly, this method fine-tunes a mere 0.32% of parameters throughout the model, in contrast to end-to-end fine-tuning (100% of parameters). Additionally, we study the effect of in-context examples and out-of-distribution (OOD) training before concluding with a radiologist reader study and qualitative analysis. Our findings highlight the importance of domain adaptation in RRS and provide valuable insights toward developing effective natural language processing solutions for clinical tasks.
Automated Drug-Related Information Extraction from French Clinical Documents: ReLyfe Approach
Nov 29, 2021
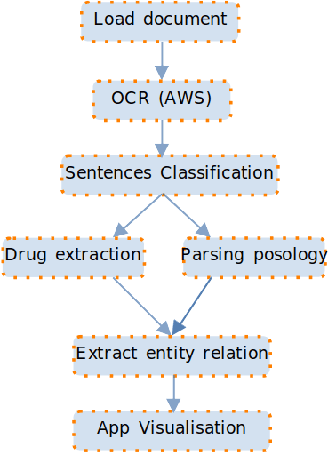


Structuring medical data in France remains a challenge mainly because of the lack of medical data due to privacy concerns and the lack of methods and approaches on processing the French language. One of these challenges is structuring drug-related information in French clinical documents. To our knowledge, over the last decade, there are less than five relevant papers that study French prescriptions. This paper proposes a new approach for extracting drug-related information from French clinical scanned documents while preserving patients' privacy. In addition, we deployed our method in a health data management platform where it is used to structure drug medical data and help patients organize their drug schedules. It can be implemented on any web or mobile platform. This work closes the gap between theoretical and practical work by creating an application adapted to real production problems. It is a combination of a rule-based phase and a Deep Learning approach. Finally, numerical results show the outperformance and relevance of the proposed methodology.
* It is published in "GLOBAL HEALTH 2021: The Tenth International Conference on Global Health Challenges" , Pages: 24 to 29, Location: Barcelona, Spain , Publication date: October 3, 2021 , URL paper: https://thinkmind.org/index.php?view=article&articleid=global_health_2021_2_30_70030