 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePyTorch: An Imperative Style, High-Performance Deep Learning Library
Dec 03, 2019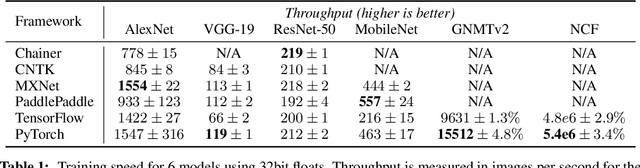

Deep learning frameworks have often focused on either usability or speed, but not both. PyTorch is a machine learning library that shows that these two goals are in fact compatible: it provides an imperative and Pythonic programming style that supports code as a model, makes debugging easy and is consistent with other popular scientific computing libraries, while remaining efficient and supporting hardware accelerators such as GPUs. In this paper, we detail the principles that drove the implementation of PyTorch and how they are reflected in its architecture. We emphasize that every aspect of PyTorch is a regular Python program under the full control of its user. We also explain how the careful and pragmatic implementation of the key components of its runtime enables them to work together to achieve compelling performance. We demonstrate the efficiency of individual subsystems, as well as the overall speed of PyTorch on several common benchmarks.
Training Millions of Personalized Dialogue Agents
Sep 06, 2018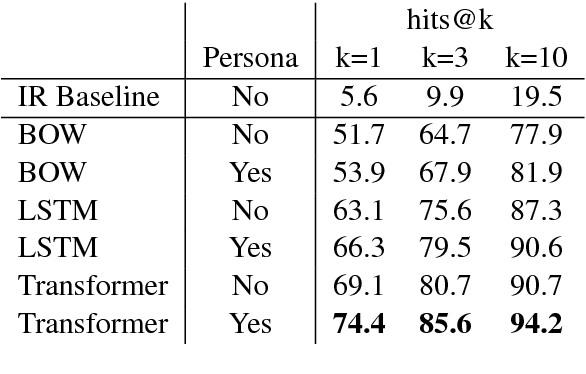
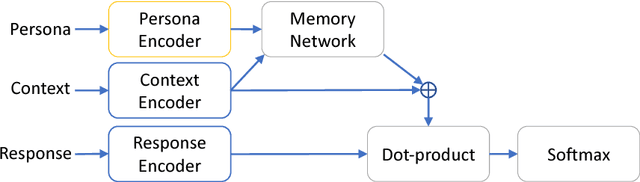
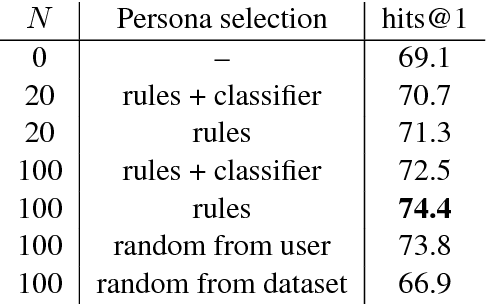
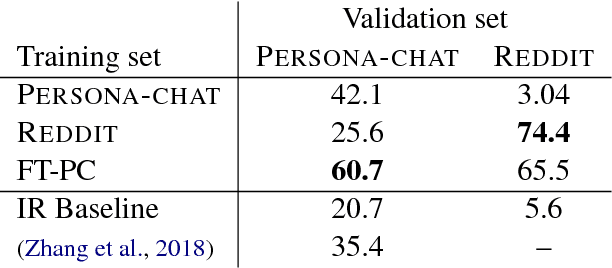
Current dialogue systems are not very engaging for users, especially when trained end-to-end without relying on proactive reengaging scripted strategies. Zhang et al. (2018) showed that the engagement level of end-to-end dialogue models increases when conditioning them on text personas providing some personalized back-story to the model. However, the dataset used in Zhang et al. (2018) is synthetic and of limited size as it contains around 1k different personas. In this paper we introduce a new dataset providing 5 million personas and 700 million persona-based dialogues. Our experiments show that, at this scale, training using personas still improves the performance of end-to-end systems. In addition, we show that other tasks benefit from the wide coverage of our dataset by fine-tuning our model on the data from Zhang et al. (2018) and achieving state-of-the-art results.
Weaver: Deep Co-Encoding of Questions and Documents for Machine Reading
Apr 27, 2018


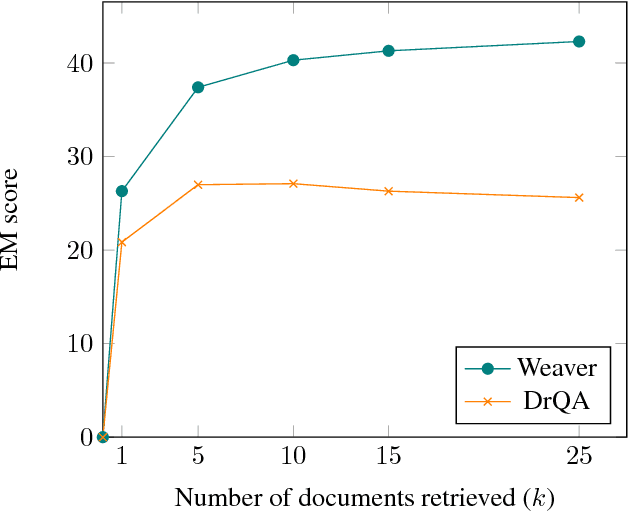
This paper aims at improving how machines can answer questions directly from text, with the focus of having models that can answer correctly multiple types of questions and from various types of texts, documents or even from large collections of them. To that end, we introduce the Weaver model that uses a new way to relate a question to a textual context by weaving layers of recurrent networks, with the goal of making as few assumptions as possible as to how the information from both question and context should be combined to form the answer. We show empirically on six datasets that Weaver performs well in multiple conditions. For instance, it produces solid results on the very popular SQuAD dataset (Rajpurkar et al., 2016), solves almost all bAbI tasks (Weston et al., 2015) and greatly outperforms state-of-the-art methods for open domain question answering from text (Chen et al., 2017).