 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWeaver: Deep Co-Encoding of Questions and Documents for Machine Reading
Paper and Code



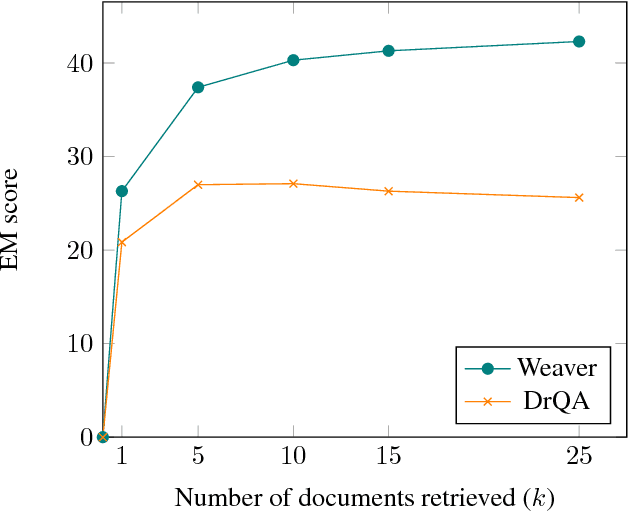
This paper aims at improving how machines can answer questions directly from text, with the focus of having models that can answer correctly multiple types of questions and from various types of texts, documents or even from large collections of them. To that end, we introduce the Weaver model that uses a new way to relate a question to a textual context by weaving layers of recurrent networks, with the goal of making as few assumptions as possible as to how the information from both question and context should be combined to form the answer. We show empirically on six datasets that Weaver performs well in multiple conditions. For instance, it produces solid results on the very popular SQuAD dataset (Rajpurkar et al., 2016), solves almost all bAbI tasks (Weston et al., 2015) and greatly outperforms state-of-the-art methods for open domain question answering from text (Chen et al., 2017).