Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnsupervised pretraining transfers well across languages
Paper and Code
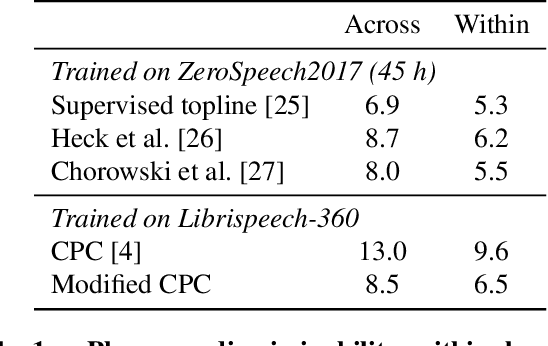
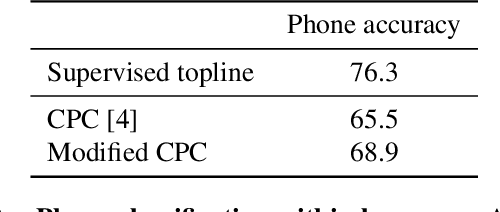
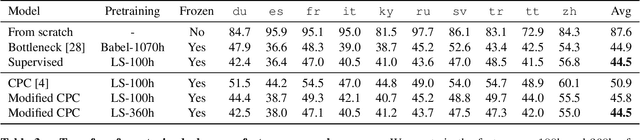
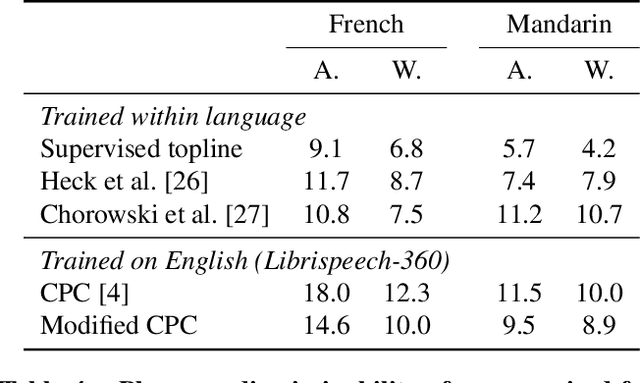
Cross-lingual and multi-lingual training of Automatic Speech Recognition (ASR) has been extensively investigated in the supervised setting. This assumes the existence of a parallel corpus of speech and orthographic transcriptions. Recently, contrastive predictive coding (CPC) algorithms have been proposed to pretrain ASR systems with unlabelled data. In this work, we investigate whether unsupervised pretraining transfers well across languages. We show that a slight modification of the CPC pretraining extracts features that transfer well to other languages, being on par or even outperforming supervised pretraining. This shows the potential of unsupervised methods for languages with few linguistic resources.
* ICASSP 2020 * 6 pages. Accepted at ICASSP 2020. However the 2 pages of
supplementary materials will appear only in the arxiv version
View paper on