 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Interactive Language Modeling
Dec 14, 2021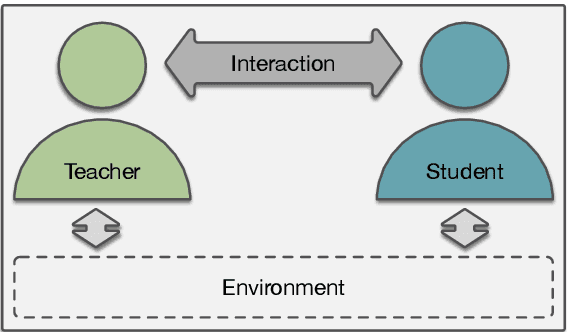
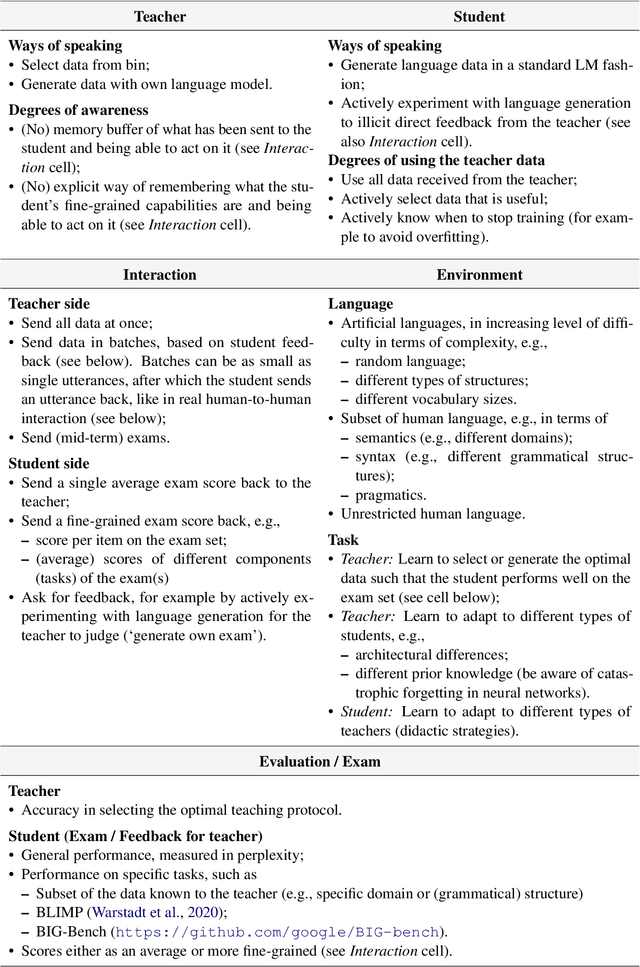
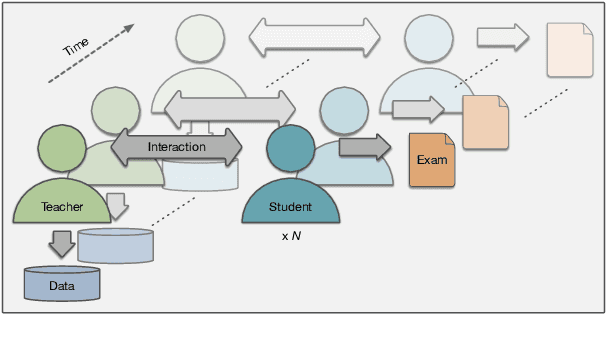
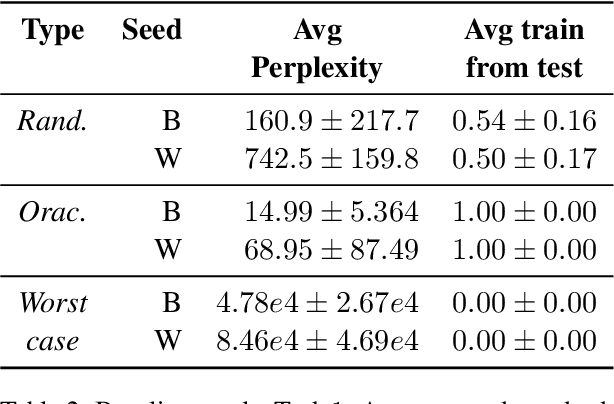
Interaction between caregivers and children plays a critical role in human language acquisition and development. Given this observation, it is remarkable that explicit interaction plays little to no role in artificial language modeling -- which also targets the acquisition of human language, yet by artificial models. Moreover, an interactive approach to language modeling has the potential to make language models substantially more versatile and to considerably impact downstream applications. Motivated by these considerations, we pioneer the space of interactive language modeling. As a first contribution we present a road map in which we detail the steps that need to be taken towards interactive language modeling. We then lead by example and take the first steps on this road map, showing the initial feasibility of our approach. As such, this work aims to be the start of a larger research agenda on interactive language modeling.
Generative Spoken Language Modeling from Raw Audio
Feb 01, 2021



Generative spoken language modeling involves learning jointly the acoustic and linguistic characteristics of a language from raw audio only (without text or labels). We introduce metrics to automatically evaluate the generated output in terms of acoustic and linguistic quality in two associated end-to-end tasks, respectively: speech resynthesis (repeating the speech input using the system's own voice), and speech generation (producing novel speech outputs conditional on a spoken prompt, or unconditionally), and validate these metrics with human judgment. We test baseline systems consisting of a discrete speech encoder (returning discrete, low bitrate, pseudo-text units), a generative language model (trained on pseudo-text units), and a speech decoder (generating a waveform from pseudo-text). By comparing three state-of-the-art unsupervised speech encoders (Contrastive Predictive Coding (CPC), wav2vec 2.0, HuBERT), and varying the number of discrete units (50, 100, 200), we investigate how the generative performance depends on the quality of the learned units as measured by unsupervised metrics (zero-shot probe tasks). We will open source our evaluation stack and baseline models.
The Zero Resource Speech Benchmark 2021: Metrics and baselines for unsupervised spoken language modeling
Dec 01, 2020


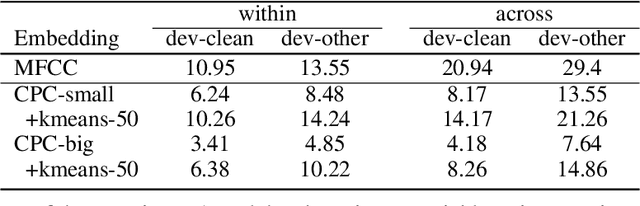
We introduce a new unsupervised task, spoken language modeling: the learning of linguistic representations from raw audio signals without any labels, along with the Zero Resource Speech Benchmark 2021: a suite of 4 black-box, zero-shot metrics probing for the quality of the learned models at 4 linguistic levels: phonetics, lexicon, syntax and semantics. We present the results and analyses of a composite baseline made of the concatenation of three unsupervised systems: self-supervised contrastive representation learning (CPC), clustering (k-means) and language modeling (LSTM or BERT). The language models learn on the basis of the pseudo-text derived from clustering the learned representations. This simple pipeline shows better than chance performance on all four metrics, demonstrating the feasibility of spoken language modeling from raw speech. It also yields worse performance compared to text-based 'topline' systems trained on the same data, delineating the space to be explored by more sophisticated end-to-end models.
Libri-Light: A Benchmark for ASR with Limited or No Supervision
Dec 17, 2019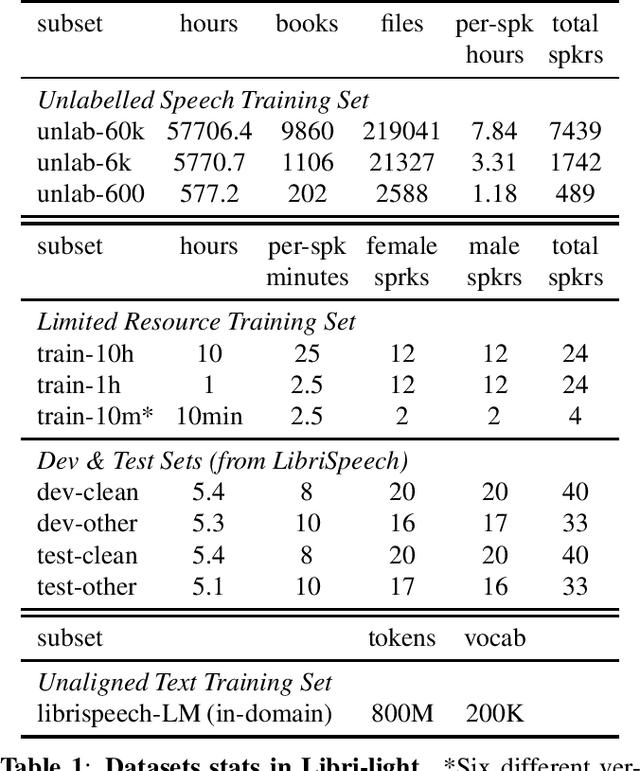
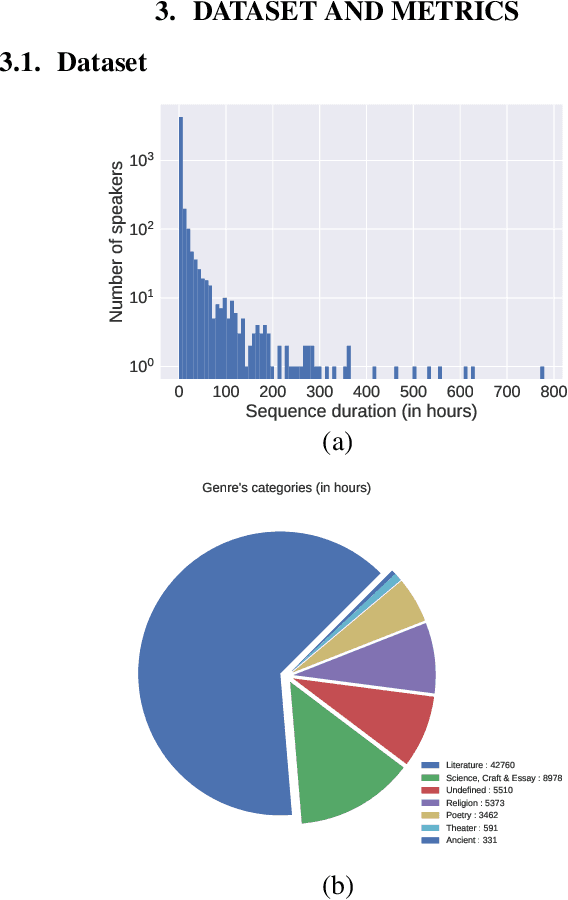
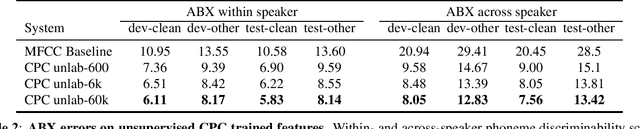
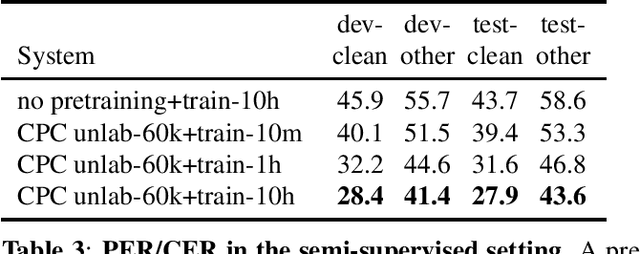
We introduce a new collection of spoken English audio suitable for training speech recognition systems under limited or no supervision. It is derived from open-source audio books from the LibriVox project. It contains over 60K hours of audio, which is, to our knowledge, the largest freely-available corpus of speech. The audio has been segmented using voice activity detection and is tagged with SNR, speaker ID and genre descriptions. Additionally, we provide baseline systems and evaluation metrics working under three settings: (1) the zero resource/unsupervised setting (ABX), (2) the semi-supervised setting (PER, CER) and (3) the distant supervision setting (WER). Settings (2) and (3) use limited textual resources (10 minutes to 10 hours) aligned with the speech. Setting (3) uses large amounts of unaligned text. They are evaluated on the standard LibriSpeech dev and test sets for comparison with the supervised state-of-the-art.