 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTextless Speech Emotion Conversion using Decomposed and Discrete Representations
Nov 14, 2021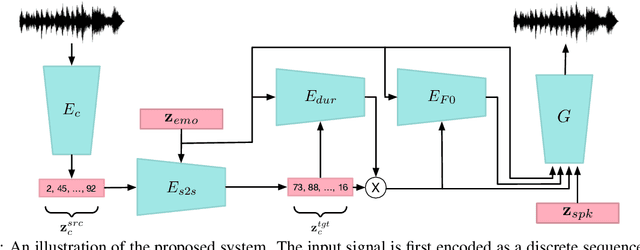
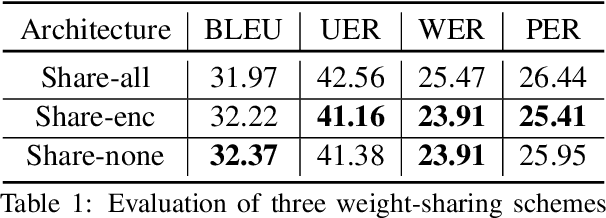
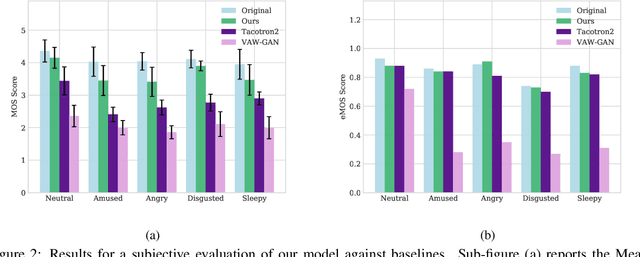
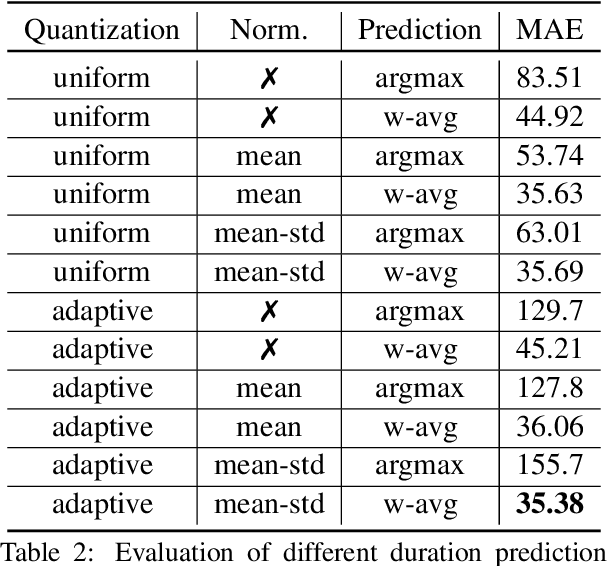
Speech emotion conversion is the task of modifying the perceived emotion of a speech utterance while preserving the lexical content and speaker identity. In this study, we cast the problem of emotion conversion as a spoken language translation task. We decompose speech into discrete and disentangled learned representations, consisting of content units, F0, speaker, and emotion. First, we modify the speech content by translating the content units to a target emotion, and then predict the prosodic features based on these units. Finally, the speech waveform is generated by feeding the predicted representations into a neural vocoder. Such a paradigm allows us to go beyond spectral and parametric changes of the signal, and model non-verbal vocalizations, such as laughter insertion, yawning removal, etc. We demonstrate objectively and subjectively that the proposed method is superior to the baselines in terms of perceived emotion and audio quality. We rigorously evaluate all components of such a complex system and conclude with an extensive model analysis and ablation study to better emphasize the architectural choices, strengths and weaknesses of the proposed method. Samples and code will be publicly available under the following link: https://speechbot.github.io/emotion.
Text-Free Prosody-Aware Generative Spoken Language Modeling
Sep 07, 2021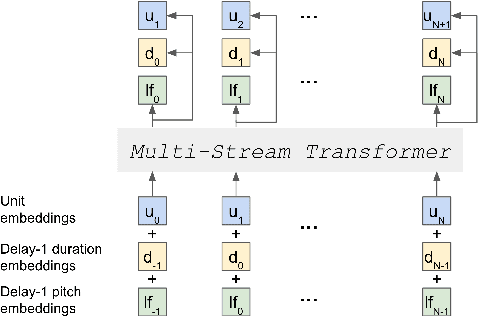
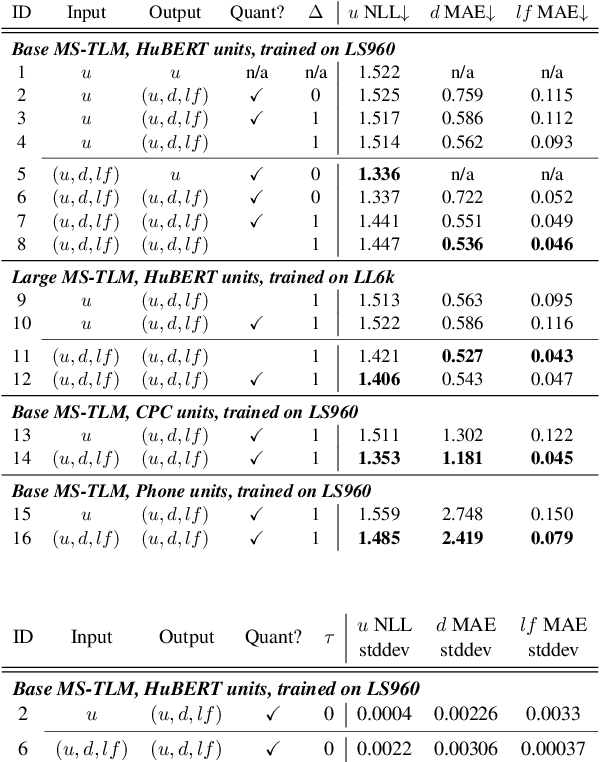
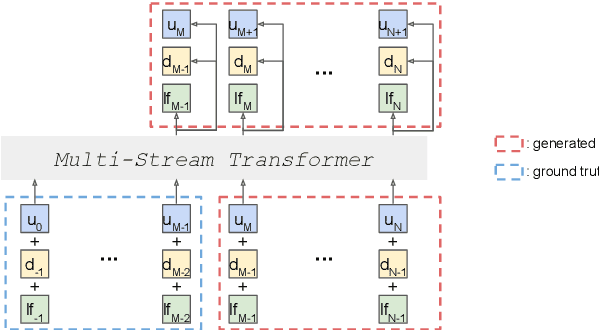
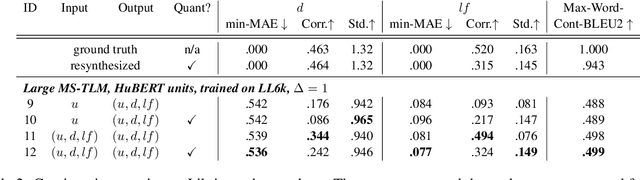
Speech pre-training has primarily demonstrated efficacy on classification tasks, while its capability of generating novel speech, similar to how GPT-2 can generate coherent paragraphs, has barely been explored. Generative Spoken Language Modeling (GSLM) (Lakhotia et al., 2021) is the only prior work addressing the generative aspects of speech pre-training, which replaces text with discovered phone-like units for language modeling and shows the ability to generate meaningful novel sentences. Unfortunately, despite eliminating the need of text, the units used in GSLM discard most of the prosodic information. Hence, GSLM fails to leverage prosody for better comprehension, and does not generate expressive speech. In this work, we present a prosody-aware generative spoken language model (pGSLM). It is composed of a multi-stream transformer language model (MS-TLM) of speech, represented as discovered unit and prosodic feature streams, and an adapted HiFi-GAN model converting MS-TLM outputs to waveforms. We devise a series of metrics for prosody modeling and generation, and re-use metrics from GSLM for content modeling. Experimental results show that the pGSLM can utilize prosody to improve both prosody and content modeling, and also generate natural, meaningful, and coherent speech given a spoken prompt. Audio samples can be found at https://speechbot.github.io/pgslm.
Generative Spoken Language Modeling from Raw Audio
Feb 01, 2021



Generative spoken language modeling involves learning jointly the acoustic and linguistic characteristics of a language from raw audio only (without text or labels). We introduce metrics to automatically evaluate the generated output in terms of acoustic and linguistic quality in two associated end-to-end tasks, respectively: speech resynthesis (repeating the speech input using the system's own voice), and speech generation (producing novel speech outputs conditional on a spoken prompt, or unconditionally), and validate these metrics with human judgment. We test baseline systems consisting of a discrete speech encoder (returning discrete, low bitrate, pseudo-text units), a generative language model (trained on pseudo-text units), and a speech decoder (generating a waveform from pseudo-text). By comparing three state-of-the-art unsupervised speech encoders (Contrastive Predictive Coding (CPC), wav2vec 2.0, HuBERT), and varying the number of discrete units (50, 100, 200), we investigate how the generative performance depends on the quality of the learned units as measured by unsupervised metrics (zero-shot probe tasks). We will open source our evaluation stack and baseline models.