Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Faiss library
Paper and Code

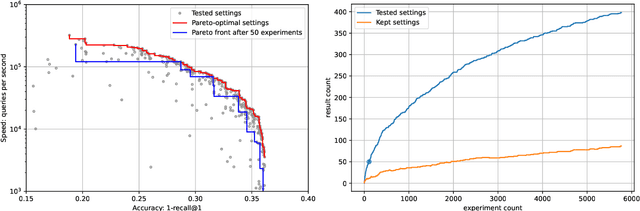

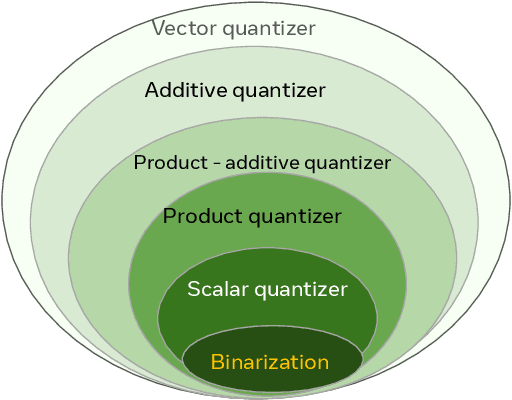
Vector databases manage large collections of embedding vectors. As AI applications are growing rapidly, so are the number of embeddings that need to be stored and indexed. The Faiss library is dedicated to vector similarity search, a core functionality of vector databases. Faiss is a toolkit of indexing methods and related primitives used to search, cluster, compress and transform vectors. This paper first describes the tradeoff space of vector search, then the design principles of Faiss in terms of structure, approach to optimization and interfacing. We benchmark key features of the library and discuss a few selected applications to highlight its broad applicability.
View paper on