 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrime and Reach: Synthesising Body Motion for Gaze-Primed Object Reach
Dec 18, 2025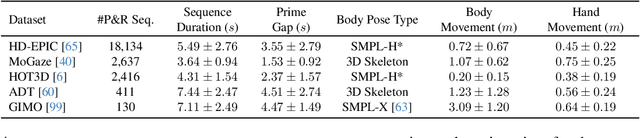



Human motion generation is a challenging task that aims to create realistic motion imitating natural human behaviour. We focus on the well-studied behaviour of priming an object/location for pick up or put down -- that is, the spotting of an object/location from a distance, known as gaze priming, followed by the motion of approaching and reaching the target location. To that end, we curate, for the first time, 23.7K gaze-primed human motion sequences for reaching target object locations from five publicly available datasets, i.e., HD-EPIC, MoGaze, HOT3D, ADT, and GIMO. We pre-train a text-conditioned diffusion-based motion generation model, then fine-tune it conditioned on goal pose or location, on our curated sequences. Importantly, we evaluate the ability of the generated motion to imitate natural human movement through several metrics, including the 'Reach Success' and a newly introduced 'Prime Success' metric. On the largest dataset, HD-EPIC, our model achieves 60% prime success and 89% reach success when conditioned on the goal object location.
HD-EPIC: A Highly-Detailed Egocentric Video Dataset
Feb 06, 2025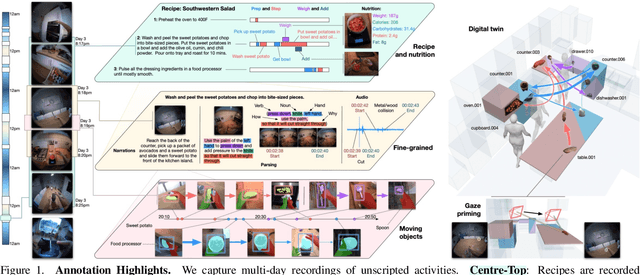
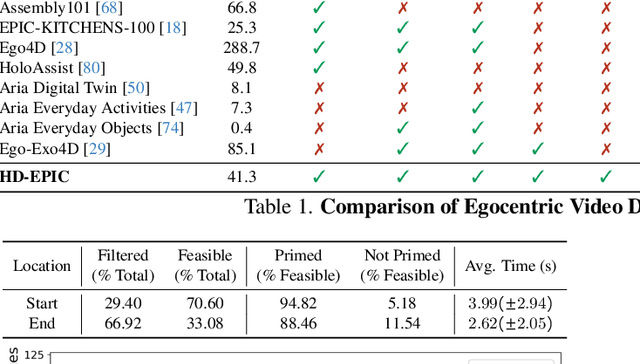

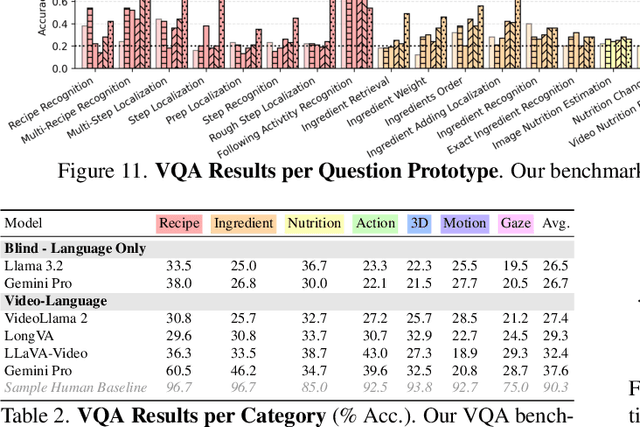
We present a validation dataset of newly-collected kitchen-based egocentric videos, manually annotated with highly detailed and interconnected ground-truth labels covering: recipe steps, fine-grained actions, ingredients with nutritional values, moving objects, and audio annotations. Importantly, all annotations are grounded in 3D through digital twinning of the scene, fixtures, object locations, and primed with gaze. Footage is collected from unscripted recordings in diverse home environments, making HDEPIC the first dataset collected in-the-wild but with detailed annotations matching those in controlled lab environments. We show the potential of our highly-detailed annotations through a challenging VQA benchmark of 26K questions assessing the capability to recognise recipes, ingredients, nutrition, fine-grained actions, 3D perception, object motion, and gaze direction. The powerful long-context Gemini Pro only achieves 38.5% on this benchmark, showcasing its difficulty and highlighting shortcomings in current VLMs. We additionally assess action recognition, sound recognition, and long-term video-object segmentation on HD-EPIC. HD-EPIC is 41 hours of video in 9 kitchens with digital twins of 413 kitchen fixtures, capturing 69 recipes, 59K fine-grained actions, 51K audio events, 20K object movements and 37K object masks lifted to 3D. On average, we have 263 annotations per minute of our unscripted videos.
TIM: A Time Interval Machine for Audio-Visual Action Recognition
Apr 09, 2024



Diverse actions give rise to rich audio-visual signals in long videos. Recent works showcase that the two modalities of audio and video exhibit different temporal extents of events and distinct labels. We address the interplay between the two modalities in long videos by explicitly modelling the temporal extents of audio and visual events. We propose the Time Interval Machine (TIM) where a modality-specific time interval poses as a query to a transformer encoder that ingests a long video input. The encoder then attends to the specified interval, as well as the surrounding context in both modalities, in order to recognise the ongoing action. We test TIM on three long audio-visual video datasets: EPIC-KITCHENS, Perception Test, and AVE, reporting state-of-the-art (SOTA) for recognition. On EPIC-KITCHENS, we beat previous SOTA that utilises LLMs and significantly larger pre-training by 2.9% top-1 action recognition accuracy. Additionally, we show that TIM can be adapted for action detection, using dense multi-scale interval queries, outperforming SOTA on EPIC-KITCHENS-100 for most metrics, and showing strong performance on the Perception Test. Our ablations show the critical role of integrating the two modalities and modelling their time intervals in achieving this performance. Code and models at: https://github.com/JacobChalk/TIM
Spatial Cognition from Egocentric Video: Out of Sight, Not Out of Mind
Apr 07, 2024



As humans move around, performing their daily tasks, they are able to recall where they have positioned objects in their environment, even if these objects are currently out of sight. In this paper, we aim to mimic this spatial cognition ability. We thus formulate the task of Out of Sight, Not Out of Mind - 3D tracking active objects using observations captured through an egocentric camera. We introduce Lift, Match and Keep (LMK), a method which lifts partial 2D observations to 3D world coordinates, matches them over time using visual appearance, 3D location and interactions to form object tracks, and keeps these object tracks even when they go out-of-view of the camera - hence keeping in mind what is out of sight. We test LMK on 100 long videos from EPIC-KITCHENS. Our results demonstrate that spatial cognition is critical for correctly locating objects over short and long time scales. E.g., for one long egocentric video, we estimate the 3D location of 50 active objects. Of these, 60% can be correctly positioned in 3D after 2 minutes of leaving the camera view.
Epic-Sounds: A Large-scale Dataset of Actions That Sound
Feb 01, 2023



We introduce EPIC-SOUNDS, a large-scale dataset of audio annotations capturing temporal extents and class labels within the audio stream of the egocentric videos. We propose an annotation pipeline where annotators temporally label distinguishable audio segments and describe the action that could have caused this sound. We identify actions that can be discriminated purely from audio, through grouping these free-form descriptions of audio into classes. For actions that involve objects colliding, we collect human annotations of the materials of these objects (e.g. a glass object being placed on a wooden surface), which we verify from visual labels, discarding ambiguities. Overall, EPIC-SOUNDS includes 78.4k categorised segments of audible events and actions, distributed across 44 classes as well as 39.2k non-categorised segments. We train and evaluate two state-of-the-art audio recognition models on our dataset, highlighting the importance of audio-only labels and the limitations of current models to recognise actions that sound.