Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVoxSRC 2020: The Second VoxCeleb Speaker Recognition Challenge
Paper and Code
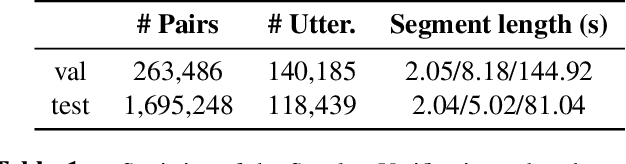
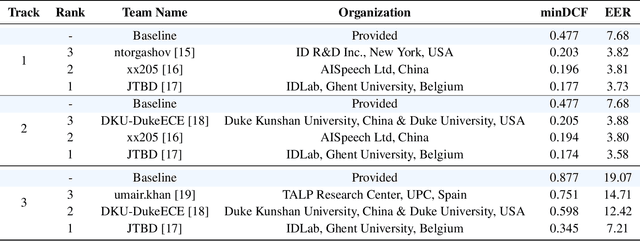

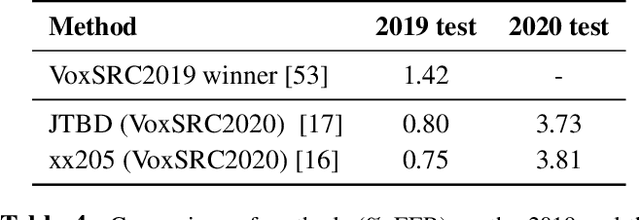
We held the second installment of the VoxCeleb Speaker Recognition Challenge in conjunction with Interspeech 2020. The goal of this challenge was to assess how well current speaker recognition technology is able to diarise and recognize speakers in unconstrained or `in the wild' data. It consisted of: (i) a publicly available speaker recognition and diarisation dataset from YouTube videos together with ground truth annotation and standardised evaluation software; and (ii) a virtual public challenge and workshop held at Interspeech 2020. This paper outlines the challenge, and describes the baselines, methods used, and results. We conclude with a discussion of the progress over the first installment of the challenge.
View paper on