 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAccommodating Audio Modality in CLIP for Multimodal Processing
Mar 12, 2023Multimodal processing has attracted much attention lately especially with the success of pre-training. However, the exploration has mainly focused on vision-language pre-training, as introducing more modalities can greatly complicate model design and optimization. In this paper, we extend the stateof-the-art Vision-Language model CLIP to accommodate the audio modality for Vision-Language-Audio multimodal processing. Specifically, we apply inter-modal and intra-modal contrastive learning to explore the correlation between audio and other modalities in addition to the inner characteristics of the audio modality. Moreover, we further design an audio type token to dynamically learn different audio information type for different scenarios, as both verbal and nonverbal heterogeneous information is conveyed in general audios. Our proposed CLIP4VLA model is validated in different downstream tasks including video retrieval and video captioning, and achieves the state-of-the-art performance on the benchmark datasets of MSR-VTT, VATEX, and Audiocaps.
Unifying Event Detection and Captioning as Sequence Generation via Pre-Training
Jul 18, 2022

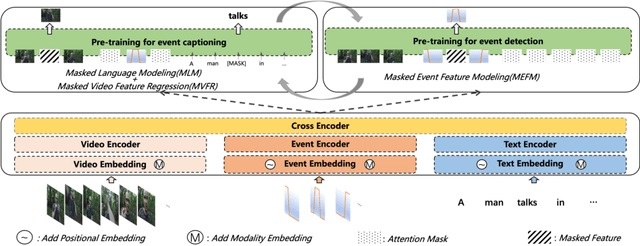
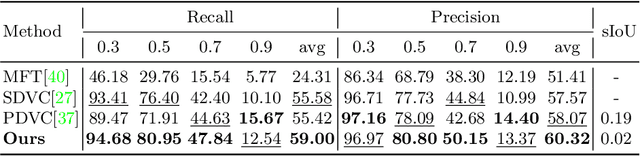
Dense video captioning aims to generate corresponding text descriptions for a series of events in the untrimmed video, which can be divided into two sub-tasks, event detection and event captioning. Unlike previous works that tackle the two sub-tasks separately, recent works have focused on enhancing the inter-task association between the two sub-tasks. However, designing inter-task interactions for event detection and captioning is not trivial due to the large differences in their task specific solutions. Besides, previous event detection methods normally ignore temporal dependencies between events, leading to event redundancy or inconsistency problems. To tackle above the two defects, in this paper, we define event detection as a sequence generation task and propose a unified pre-training and fine-tuning framework to naturally enhance the inter-task association between event detection and captioning. Since the model predicts each event with previous events as context, the inter-dependency between events is fully exploited and thus our model can detect more diverse and consistent events in the video. Experiments on the ActivityNet dataset show that our model outperforms the state-of-the-art methods, and can be further boosted when pre-trained on extra large-scale video-text data. Code is available at \url{https://github.com/QiQAng/UEDVC}.
Some theoretical results on discrete contour trees
Jun 24, 2022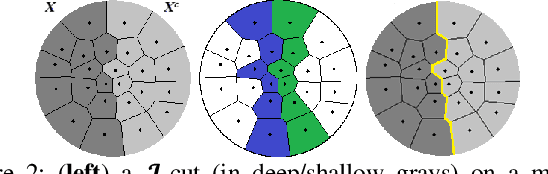

Contour trees have been developed to visualize or encode scalar data in imaging technologies and scientific simulations. Contours are defined on a continuous scalar field. For discrete data, a continuous function is first interpolated, where contours are then defined. In this paper we define a discrete contour tree, called the iso-tree, on a scalar graph, and discuss its properties. We show that the iso-tree model works for data of all dimensions, and develop an axiomatic system formalizing the discrete contour structures. We also report an isomorphism between iso-trees and augmented contour trees, showing that contour tree algorithms can be used to compute discrete contour trees, and vice versa.
Progressive Learning for Image Retrieval with Hybrid-Modality Queries
Apr 24, 2022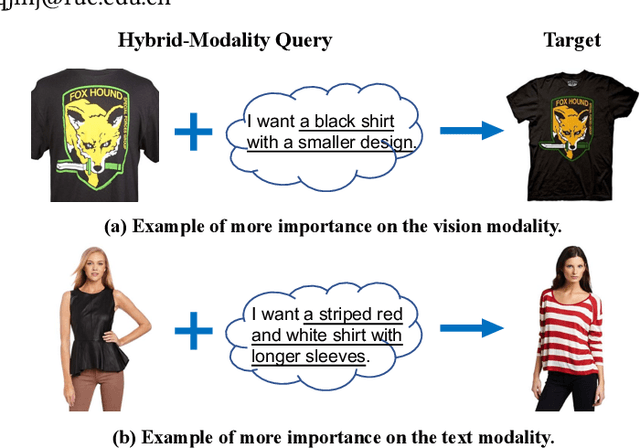
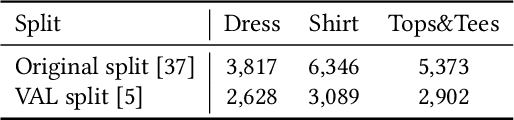
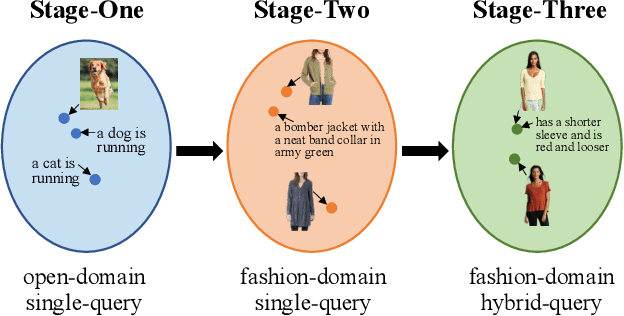
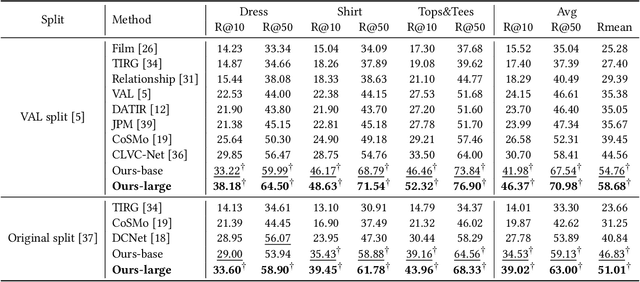
Image retrieval with hybrid-modality queries, also known as composing text and image for image retrieval (CTI-IR), is a retrieval task where the search intention is expressed in a more complex query format, involving both vision and text modalities. For example, a target product image is searched using a reference product image along with text about changing certain attributes of the reference image as the query. It is a more challenging image retrieval task that requires both semantic space learning and cross-modal fusion. Previous approaches that attempt to deal with both aspects achieve unsatisfactory performance. In this paper, we decompose the CTI-IR task into a three-stage learning problem to progressively learn the complex knowledge for image retrieval with hybrid-modality queries. We first leverage the semantic embedding space for open-domain image-text retrieval, and then transfer the learned knowledge to the fashion-domain with fashion-related pre-training tasks. Finally, we enhance the pre-trained model from single-query to hybrid-modality query for the CTI-IR task. Furthermore, as the contribution of individual modality in the hybrid-modality query varies for different retrieval scenarios, we propose a self-supervised adaptive weighting strategy to dynamically determine the importance of image and text in the hybrid-modality query for better retrieval. Extensive experiments show that our proposed model significantly outperforms state-of-the-art methods in the mean of Recall@K by 24.9% and 9.5% on the Fashion-IQ and Shoes benchmark datasets respectively.
Product-oriented Machine Translation with Cross-modal Cross-lingual Pre-training
Aug 25, 2021
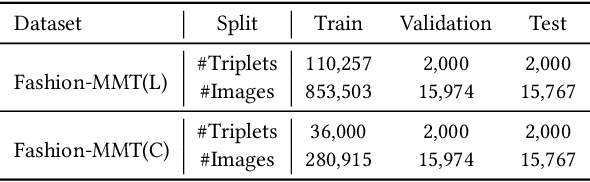

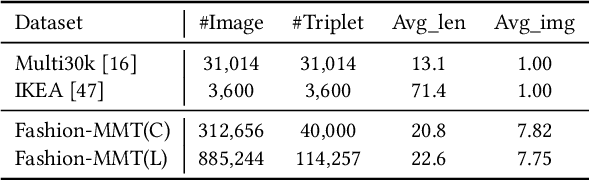
Translating e-commercial product descriptions, a.k.a product-oriented machine translation (PMT), is essential to serve e-shoppers all over the world. However, due to the domain specialty, the PMT task is more challenging than traditional machine translation problems. Firstly, there are many specialized jargons in the product description, which are ambiguous to translate without the product image. Secondly, product descriptions are related to the image in more complicated ways than standard image descriptions, involving various visual aspects such as objects, shapes, colors or even subjective styles. Moreover, existing PMT datasets are small in scale to support the research. In this paper, we first construct a large-scale bilingual product description dataset called Fashion-MMT, which contains over 114k noisy and 40k manually cleaned description translations with multiple product images. To effectively learn semantic alignments among product images and bilingual texts in translation, we design a unified product-oriented cross-modal cross-lingual model (\upoc~) for pre-training and fine-tuning. Experiments on the Fashion-MMT and Multi30k datasets show that our model significantly outperforms the state-of-the-art models even pre-trained on the same dataset. It is also shown to benefit more from large-scale noisy data to improve the translation quality. We will release the dataset and codes at https://github.com/syuqings/Fashion-MMT.
Team RUC_AIM3 Technical Report at ActivityNet 2021: Entities Object Localization
Jun 11, 2021
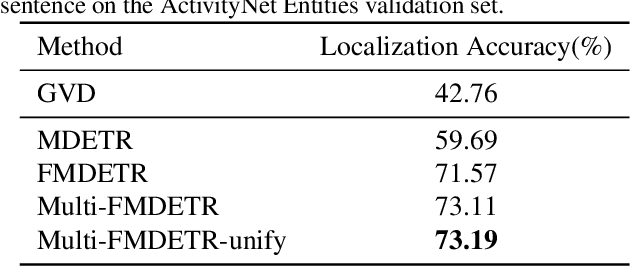

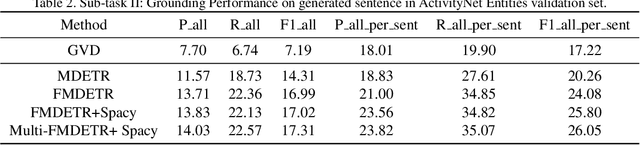
Entities Object Localization (EOL) aims to evaluate how grounded or faithful a description is, which consists of caption generation and object grounding. Previous works tackle this problem by jointly training the two modules in a framework, which limits the complexity of each module. Therefore, in this work, we propose to divide these two modules into two stages and improve them respectively to boost the whole system performance. For the caption generation, we propose a Unified Multi-modal Pre-training Model (UMPM) to generate event descriptions with rich objects for better localization. For the object grounding, we fine-tune the state-of-the-art detection model MDETR and design a post processing method to make the grounding results more faithful. Our overall system achieves the state-of-the-art performances on both sub-tasks in Entities Object Localization challenge at Activitynet 2021, with 72.57 localization accuracy on the testing set of sub-task I and 0.2477 F1_all_per_sent on the hidden testing set of sub-task II.
Towards Diverse Paragraph Captioning for Untrimmed Videos
May 30, 2021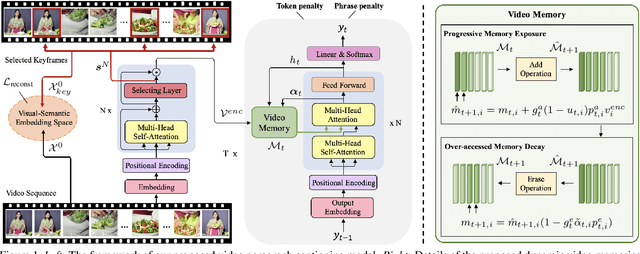
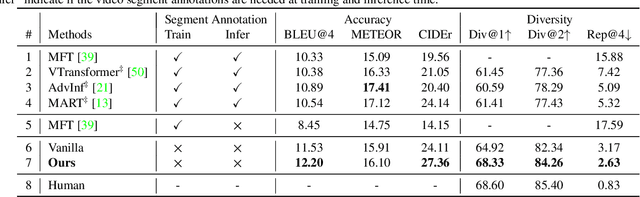
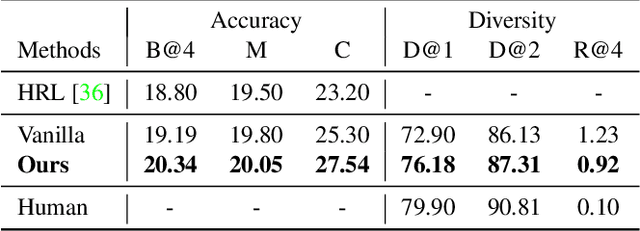
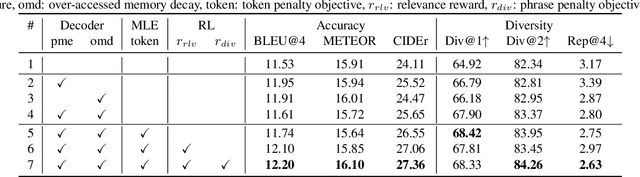
Video paragraph captioning aims to describe multiple events in untrimmed videos with descriptive paragraphs. Existing approaches mainly solve the problem in two steps: event detection and then event captioning. Such two-step manner makes the quality of generated paragraphs highly dependent on the accuracy of event proposal detection which is already a challenging task. In this paper, we propose a paragraph captioning model which eschews the problematic event detection stage and directly generates paragraphs for untrimmed videos. To describe coherent and diverse events, we propose to enhance the conventional temporal attention with dynamic video memories, which progressively exposes new video features and suppresses over-accessed video contents to control visual focuses of the model. In addition, a diversity-driven training strategy is proposed to improve diversity of paragraph on the language perspective. Considering that untrimmed videos generally contain massive but redundant frames, we further augment the video encoder with keyframe awareness to improve efficiency. Experimental results on the ActivityNet and Charades datasets show that our proposed model significantly outperforms the state-of-the-art performance on both accuracy and diversity metrics without using any event boundary annotations. Code will be released at https://github.com/syuqings/video-paragraph.
WenLan: Bridging Vision and Language by Large-Scale Multi-Modal Pre-Training
Mar 19, 2021
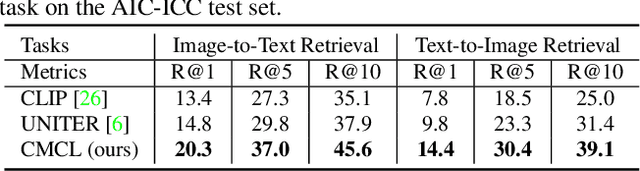
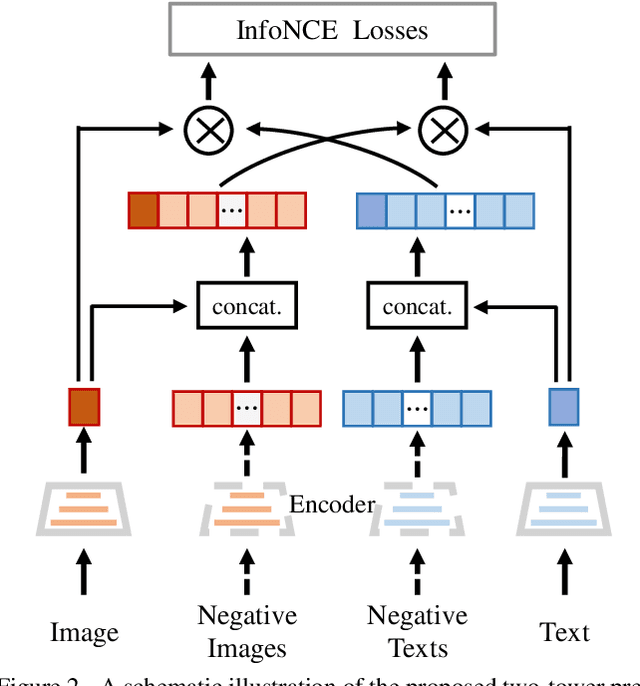
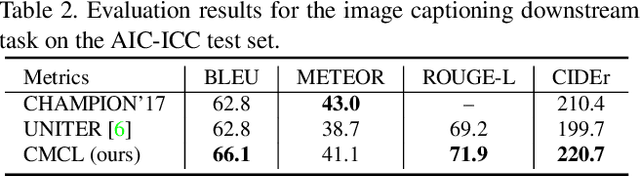
Multi-modal pre-training models have been intensively explored to bridge vision and language in recent years. However, most of them explicitly model the cross-modal interaction between image-text pairs, by assuming that there exists strong semantic correlation between the text and image modalities. Since this strong assumption is often invalid in real-world scenarios, we choose to implicitly model the cross-modal correlation for large-scale multi-modal pre-training, which is the focus of the Chinese project `WenLan' led by our team. Specifically, with the weak correlation assumption over image-text pairs, we propose a two-tower pre-training model called BriVL within the cross-modal contrastive learning framework. Unlike OpenAI CLIP that adopts a simple contrastive learning method, we devise a more advanced algorithm by adapting the latest method MoCo into the cross-modal scenario. By building a large queue-based dictionary, our BriVL can incorporate more negative samples in limited GPU resources. We further construct a large Chinese multi-source image-text dataset called RUC-CAS-WenLan for pre-training our BriVL model. Extensive experiments demonstrate that the pre-trained BriVL model outperforms both UNITER and OpenAI CLIP on various downstream tasks.
Team RUC_AIM3 Technical Report at Activitynet 2020 Task 2: Exploring Sequential Events Detection for Dense Video Captioning
Jun 14, 2020

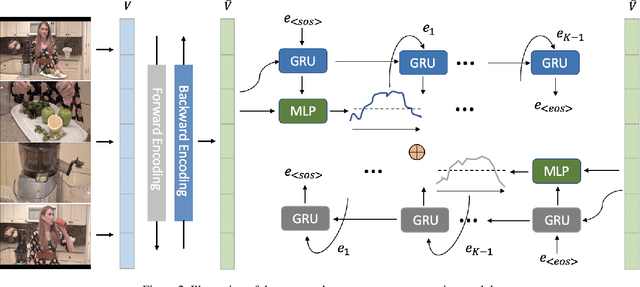
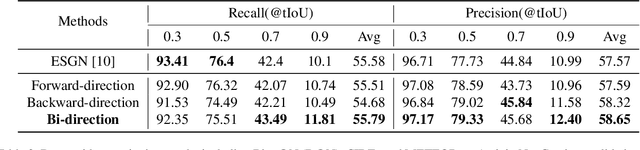
Detecting meaningful events in an untrimmed video is essential for dense video captioning. In this work, we propose a novel and simple model for event sequence generation and explore temporal relationships of the event sequence in the video. The proposed model omits inefficient two-stage proposal generation and directly generates event boundaries conditioned on bi-directional temporal dependency in one pass. Experimental results show that the proposed event sequence generation model can generate more accurate and diverse events within a small number of proposals. For the event captioning, we follow our previous work to employ the intra-event captioning models into our pipeline system. The overall system achieves state-of-the-art performance on the dense-captioning events in video task with 9.894 METEOR score on the challenge testing set.
Integrating Temporal and Spatial Attentions for VATEX Video Captioning Challenge 2019
Oct 15, 2019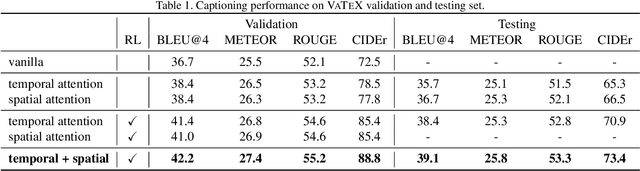
This notebook paper presents our model in the VATEX video captioning challenge. In order to capture multi-level aspects in the video, we propose to integrate both temporal and spatial attentions for video captioning. The temporal attentive module focuses on global action movements while spatial attentive module enables to describe more fine-grained objects. Considering these two types of attentive modules are complementary, we thus fuse them via a late fusion strategy. The proposed model significantly outperforms baselines and achieves 73.4 CIDEr score on the testing set which ranks the second place at the VATEX video captioning challenge leaderboard 2019.