 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBayesian Optimization in Language Space: An Eval-Efficient AI Self-Improvement Framework
Nov 15, 2025Large Language Models (LLMs) have recently enabled self-improving AI, i.e., AI that iteratively generates, evaluates, and refines its own outcomes. Recent studies have shown that self-improving AI focusing on prompt optimization can outperform state-of-the-art reinforcement-learning fine-tuned LLMs. Here, their `performance' is typically measured by query efficiency - the number of LLM-generated solution samples required to meet a certain performance threshold. However, in many societal applications, the primary limitation is not generating new solutions but evaluating them. For instance, evaluating an ad's effectiveness requires significant human feedback, which is far more costly and time-consuming than generating a candidate ad. To optimize for the evaluation efficiency objective, a natural approach is to extend Bayesian Optimization (BO), a framework proven optimal for evaluation efficiency, to the language domain. However, the difficulty of directly estimating suitable acquisition functions in LLMs' minds makes this extension challenging. This paper overcomes this challenge by proving that the combination of the simple and widely used Best-of-N selection strategy and simple textual gradients (i.e., textual edits from a critic model) statistically emulates the behavior of the gradients on the canonical UCB acquisition function, which induces optimal exploration in terms of evaluation efficiency. Based on this result, we propose TextGrad-Best-of-N Bayesian Optimization (T-BoN BO), a simple and eval-efficient language-space Bayesian optimization framework for AI self-improvement. We also empirically validate T-BoN BO by applying it to automated ad alignment tasks for persona distribution, demonstrating its superior performance compared to popular state-of-the-art baselines.
Document Valuation in LLM Summaries: A Cluster Shapley Approach
May 28, 2025Large Language Models (LLMs) are increasingly used in systems that retrieve and summarize content from multiple sources, such as search engines and AI assistants. While these models enhance user experience by generating coherent summaries, they obscure the contributions of original content creators, raising concerns about credit attribution and compensation. We address the challenge of valuing individual documents used in LLM-generated summaries. We propose using Shapley values, a game-theoretic method that allocates credit based on each document's marginal contribution. Although theoretically appealing, Shapley values are expensive to compute at scale. We therefore propose Cluster Shapley, an efficient approximation algorithm that leverages semantic similarity between documents. By clustering documents using LLM-based embeddings and computing Shapley values at the cluster level, our method significantly reduces computation while maintaining attribution quality. We demonstrate our approach to a summarization task using Amazon product reviews. Cluster Shapley significantly reduces computational complexity while maintaining high accuracy, outperforming baseline methods such as Monte Carlo sampling and Kernel SHAP with a better efficient frontier. Our approach is agnostic to the exact LLM used, the summarization process used, and the evaluation procedure, which makes it broadly applicable to a variety of summarization settings.
Visual Polarization Measurement Using Counterfactual Image Generation
Mar 13, 2025Political polarization is a significant issue in American politics, influencing public discourse, policy, and consumer behavior. While studies on polarization in news media have extensively focused on verbal content, non-verbal elements, particularly visual content, have received less attention due to the complexity and high dimensionality of image data. Traditional descriptive approaches often rely on feature extraction from images, leading to biased polarization estimates due to information loss. In this paper, we introduce the Polarization Measurement using Counterfactual Image Generation (PMCIG) method, which combines economic theory with generative models and multi-modal deep learning to fully utilize the richness of image data and provide a theoretically grounded measure of polarization in visual content. Applying this framework to a decade-long dataset featuring 30 prominent politicians across 20 major news outlets, we identify significant polarization in visual content, with notable variations across outlets and politicians. At the news outlet level, we observe significant heterogeneity in visual slant. Outlets such as Daily Mail, Fox News, and Newsmax tend to favor Republican politicians in their visual content, while The Washington Post, USA Today, and The New York Times exhibit a slant in favor of Democratic politicians. At the politician level, our results reveal substantial variation in polarized coverage, with Donald Trump and Barack Obama among the most polarizing figures, while Joe Manchin and Susan Collins are among the least. Finally, we conduct a series of validation tests demonstrating the consistency of our proposed measures with external measures of media slant that rely on non-image-based sources.
Gradients can train reward models: An Empirical Risk Minimization Approach for Offline Inverse RL and Dynamic Discrete Choice Model
Feb 19, 2025We study the problem of estimating Dynamic Discrete Choice (DDC) models, also known as offline Maximum Entropy-Regularized Inverse Reinforcement Learning (offline MaxEnt-IRL) in machine learning. The objective is to recover reward or $Q^*$ functions that govern agent behavior from offline behavior data. In this paper, we propose a globally convergent gradient-based method for solving these problems without the restrictive assumption of linearly parameterized rewards. The novelty of our approach lies in introducing the Empirical Risk Minimization (ERM) based IRL/DDC framework, which circumvents the need for explicit state transition probability estimation in the Bellman equation. Furthermore, our method is compatible with non-parametric estimation techniques such as neural networks. Therefore, the proposed method has the potential to be scaled to high-dimensional, infinite state spaces. A key theoretical insight underlying our approach is that the Bellman residual satisfies the Polyak-Lojasiewicz (PL) condition -- a property that, while weaker than strong convexity, is sufficient to ensure fast global convergence guarantees. Through a series of synthetic experiments, we demonstrate that our approach consistently outperforms benchmark methods and state-of-the-art alternatives.
LOLA: LLM-Assisted Online Learning Algorithm for Content Experiments
Jun 03, 2024



In the rapidly evolving digital content landscape, media firms and news publishers require automated and efficient methods to enhance user engagement. This paper introduces the LLM-Assisted Online Learning Algorithm (LOLA), a novel framework that integrates Large Language Models (LLMs) with adaptive experimentation to optimize content delivery. Leveraging a large-scale dataset from Upworthy, which includes 17,681 headline A/B tests aimed at evaluating the performance of various headlines associated with the same article content, we first investigate three broad pure-LLM approaches: prompt-based methods, embedding-based classification models, and fine-tuned open-source LLMs. Our findings indicate that prompt-based approaches perform poorly, achieving no more than 65% accuracy in identifying the catchier headline among two options. In contrast, OpenAI-embedding-based classification models and fine-tuned Llama-3-8b models achieve comparable accuracy, around 82-84%, though still falling short of the performance of experimentation with sufficient traffic. We then introduce LOLA, which combines the best pure-LLM approach with the Upper Confidence Bound algorithm to adaptively allocate traffic and maximize clicks. Our numerical experiments on Upworthy data show that LOLA outperforms the standard A/B testing method (the current status quo at Upworthy), pure bandit algorithms, and pure-LLM approaches, particularly in scenarios with limited experimental traffic or numerous arms. Our approach is both scalable and broadly applicable to content experiments across a variety of digital settings where firms seek to optimize user engagement, including digital advertising and social media recommendations.
Choice Models and Permutation Invariance
Jul 13, 2023



Choice Modeling is at the core of many economics, operations, and marketing problems. In this paper, we propose a fundamental characterization of choice functions that encompasses a wide variety of extant choice models. We demonstrate how nonparametric estimators like neural nets can easily approximate such functionals and overcome the curse of dimensionality that is inherent in the non-parametric estimation of choice functions. We demonstrate through extensive simulations that our proposed functionals can flexibly capture underlying consumer behavior in a completely data-driven fashion and outperform traditional parametric models. As demand settings often exhibit endogenous features, we extend our framework to incorporate estimation under endogenous features. Further, we also describe a formal inference procedure to construct valid confidence intervals on objects of interest like price elasticity. Finally, to assess the practical applicability of our estimator, we utilize a real-world dataset from S. Berry, Levinsohn, and Pakes (1995). Our empirical analysis confirms that the estimator generates realistic and comparable own- and cross-price elasticities that are consistent with the observations reported in the existing literature.
A Recursive Partitioning Approach for Dynamic Discrete Choice Modeling in High Dimensional Settings
Aug 02, 2022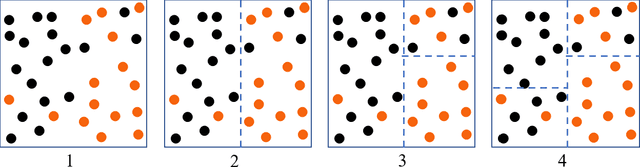
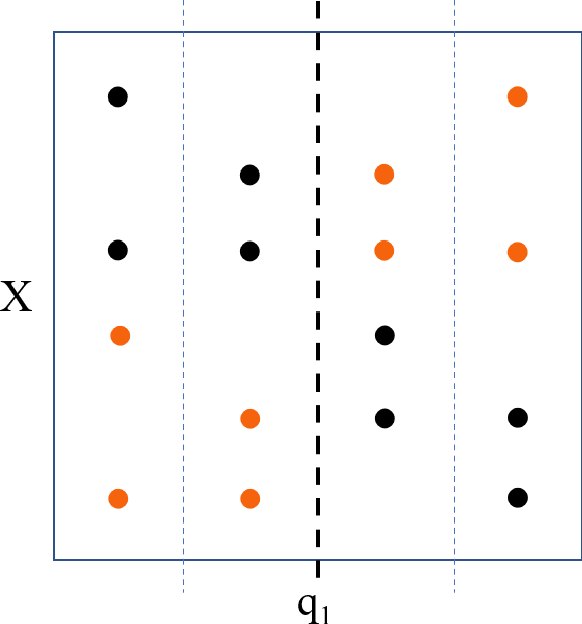
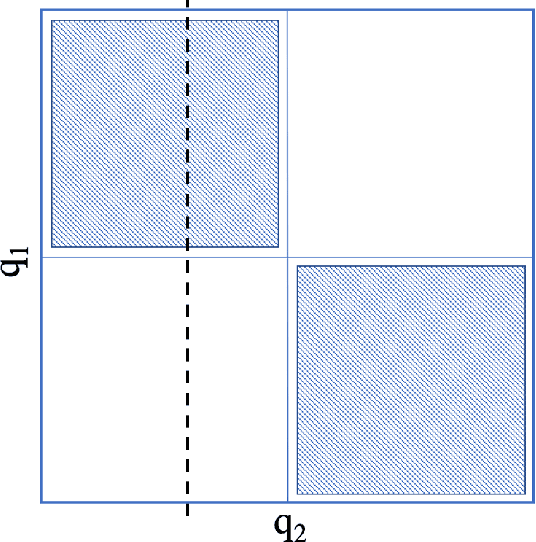
Dynamic discrete choice models are widely employed to answer substantive and policy questions in settings where individuals' current choices have future implications. However, estimation of these models is often computationally intensive and/or infeasible in high-dimensional settings. Indeed, even specifying the structure for how the utilities/state transitions enter the agent's decision is challenging in high-dimensional settings when we have no guiding theory. In this paper, we present a semi-parametric formulation of dynamic discrete choice models that incorporates a high-dimensional set of state variables, in addition to the standard variables used in a parametric utility function. The high-dimensional variable can include all the variables that are not the main variables of interest but may potentially affect people's choices and must be included in the estimation procedure, i.e., control variables. We present a data-driven recursive partitioning algorithm that reduces the dimensionality of the high-dimensional state space by taking the variation in choices and state transition into account. Researchers can then use the method of their choice to estimate the problem using the discretized state space from the first stage. Our approach can reduce the estimation bias and make estimation feasible at the same time. We present Monte Carlo simulations to demonstrate the performance of our method compared to standard estimation methods where we ignore the high-dimensional explanatory variable set.
Design and Evaluation of Personalized Free Trials
Jun 24, 2020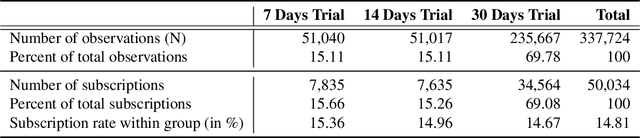
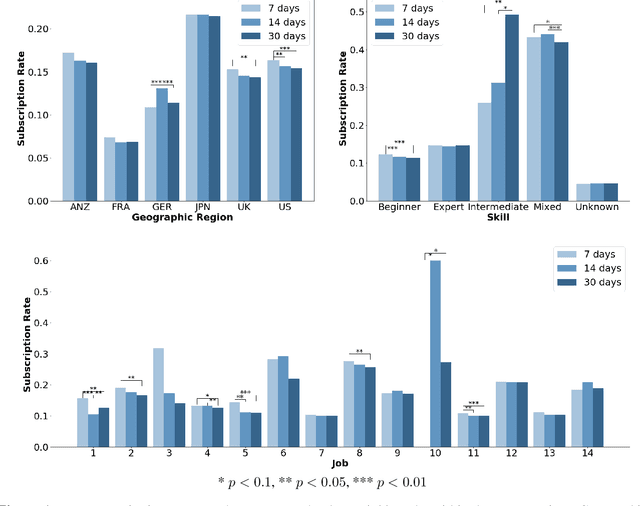
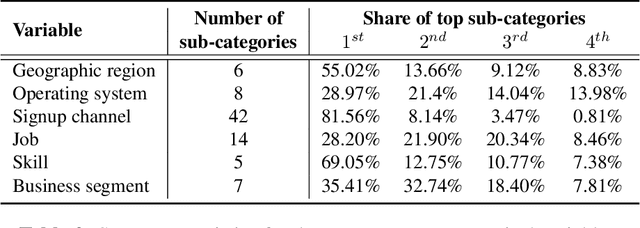
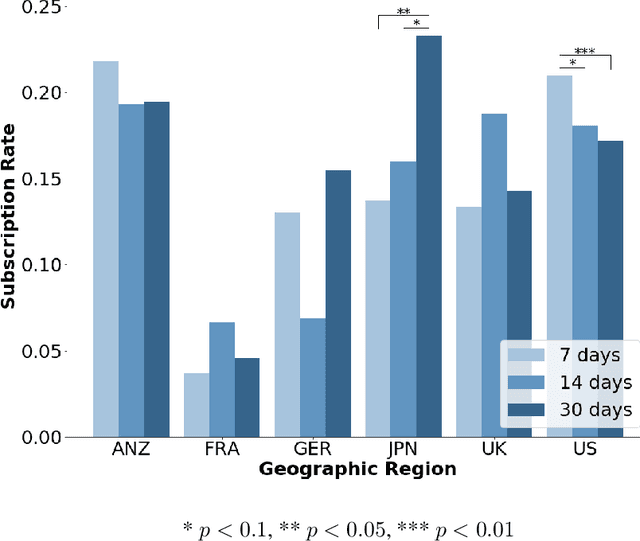
Free trial promotions, where users are given a limited time to try the product for free, are a commonly used customer acquisition strategy in the Software as a Service (SaaS) industry. We examine how trial length affect users' responsiveness, and seek to quantify the gains from personalizing the length of the free trial promotions. Our data come from a large-scale field experiment conducted by a leading SaaS firm, where new users were randomly assigned to 7, 14, or 30 days of free trial. First, we show that the 7-day trial to all consumers is the best uniform policy, with a 5.59% increase in subscriptions. Next, we develop a three-pronged framework for personalized policy design and evaluation. Using our framework, we develop seven personalized targeting policies based on linear regression, lasso, CART, random forest, XGBoost, causal tree, and causal forest, and evaluate their performances using the Inverse Propensity Score (IPS) estimator. We find that the personalized policy based on lasso performs the best, followed by the one based on XGBoost. In contrast, policies based on causal tree and causal forest perform poorly. We then link a method's effectiveness in designing policy with its ability to personalize the treatment sufficiently without over-fitting (i.e., capture spurious heterogeneity). Next, we segment consumers based on their optimal trial length and derive some substantive insights on the drivers of user behavior in this context. Finally, we show that policies designed to maximize short-run conversions also perform well on long-run outcomes such as consumer loyalty and profitability.