 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Recursive Partitioning Approach for Dynamic Discrete Choice Modeling in High Dimensional Settings
Aug 02, 2022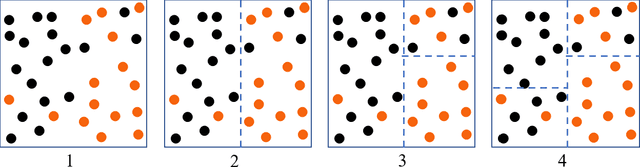
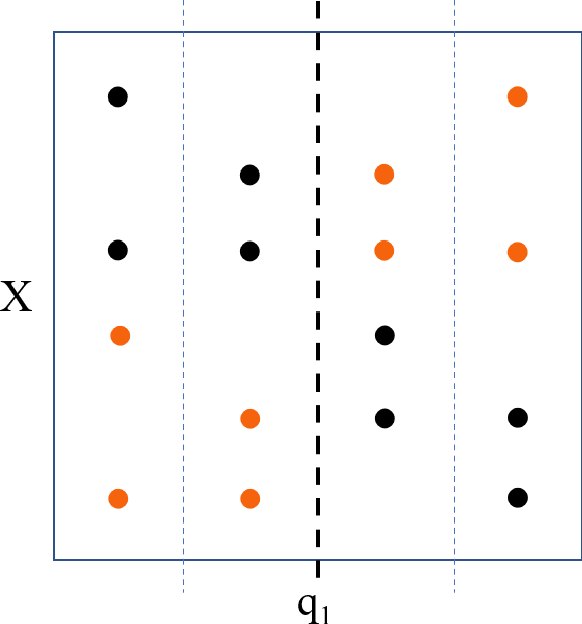
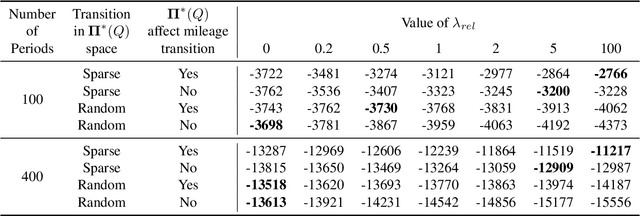
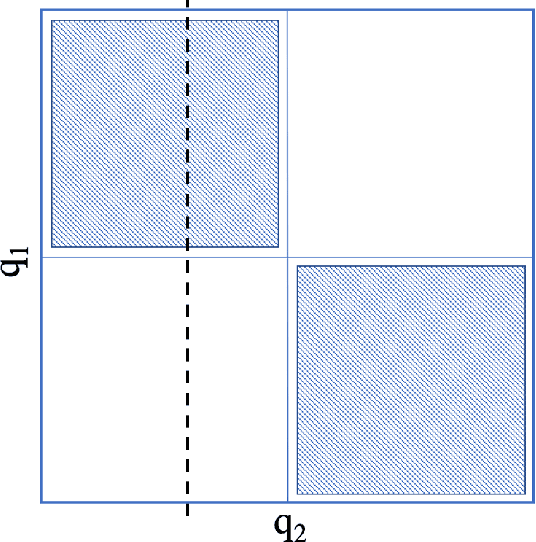
Dynamic discrete choice models are widely employed to answer substantive and policy questions in settings where individuals' current choices have future implications. However, estimation of these models is often computationally intensive and/or infeasible in high-dimensional settings. Indeed, even specifying the structure for how the utilities/state transitions enter the agent's decision is challenging in high-dimensional settings when we have no guiding theory. In this paper, we present a semi-parametric formulation of dynamic discrete choice models that incorporates a high-dimensional set of state variables, in addition to the standard variables used in a parametric utility function. The high-dimensional variable can include all the variables that are not the main variables of interest but may potentially affect people's choices and must be included in the estimation procedure, i.e., control variables. We present a data-driven recursive partitioning algorithm that reduces the dimensionality of the high-dimensional state space by taking the variation in choices and state transition into account. Researchers can then use the method of their choice to estimate the problem using the discretized state space from the first stage. Our approach can reduce the estimation bias and make estimation feasible at the same time. We present Monte Carlo simulations to demonstrate the performance of our method compared to standard estimation methods where we ignore the high-dimensional explanatory variable set.
Design and Evaluation of Personalized Free Trials
Jun 24, 2020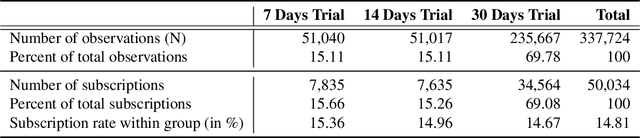
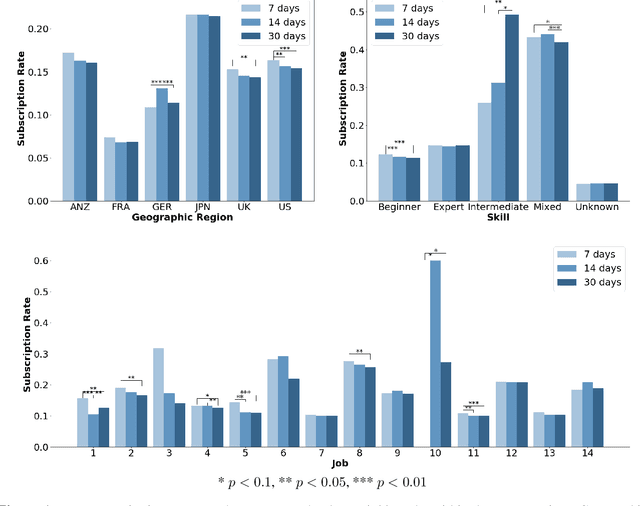
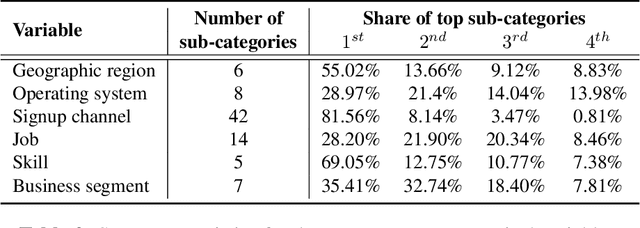
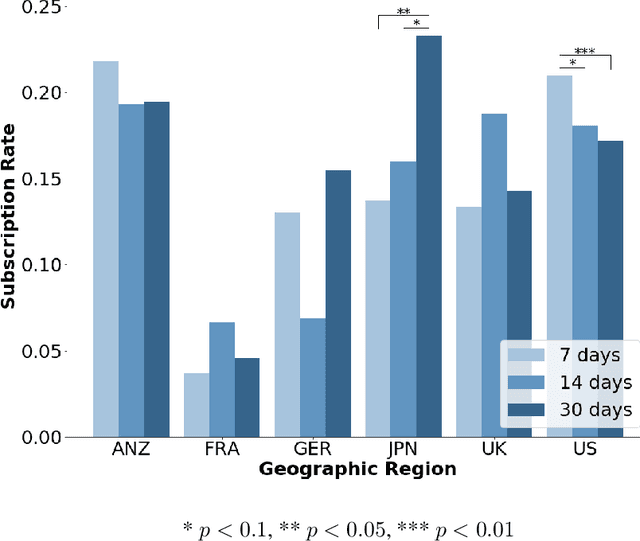
Free trial promotions, where users are given a limited time to try the product for free, are a commonly used customer acquisition strategy in the Software as a Service (SaaS) industry. We examine how trial length affect users' responsiveness, and seek to quantify the gains from personalizing the length of the free trial promotions. Our data come from a large-scale field experiment conducted by a leading SaaS firm, where new users were randomly assigned to 7, 14, or 30 days of free trial. First, we show that the 7-day trial to all consumers is the best uniform policy, with a 5.59% increase in subscriptions. Next, we develop a three-pronged framework for personalized policy design and evaluation. Using our framework, we develop seven personalized targeting policies based on linear regression, lasso, CART, random forest, XGBoost, causal tree, and causal forest, and evaluate their performances using the Inverse Propensity Score (IPS) estimator. We find that the personalized policy based on lasso performs the best, followed by the one based on XGBoost. In contrast, policies based on causal tree and causal forest perform poorly. We then link a method's effectiveness in designing policy with its ability to personalize the treatment sufficiently without over-fitting (i.e., capture spurious heterogeneity). Next, we segment consumers based on their optimal trial length and derive some substantive insights on the drivers of user behavior in this context. Finally, we show that policies designed to maximize short-run conversions also perform well on long-run outcomes such as consumer loyalty and profitability.