 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeI M Avatar: Implicit Morphable Head Avatars from Videos
Paper and Code
Dec 15, 2021
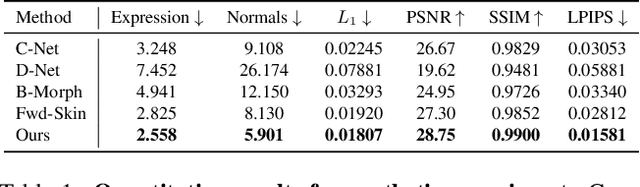
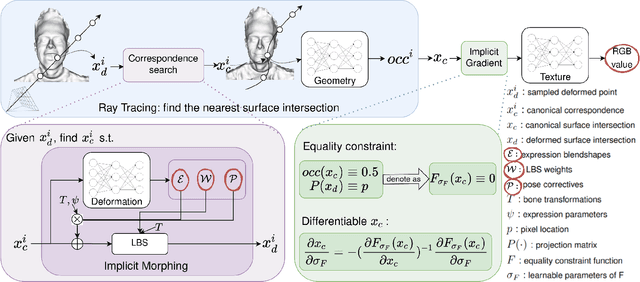
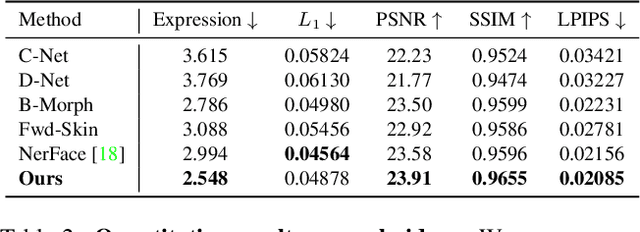
Traditional morphable face models provide fine-grained control over expression but cannot easily capture geometric and appearance details. Neural volumetric representations approach photo-realism but are hard to animate and do not generalize well to unseen expressions. To tackle this problem, we propose IMavatar (Implicit Morphable avatar), a novel method for learning implicit head avatars from monocular videos. Inspired by the fine-grained control mechanisms afforded by conventional 3DMMs, we represent the expression- and pose-related deformations via learned blendshapes and skinning fields. These attributes are pose-independent and can be used to morph the canonical geometry and texture fields given novel expression and pose parameters. We employ ray tracing and iterative root-finding to locate the canonical surface intersection for each pixel. A key contribution is our novel analytical gradient formulation that enables end-to-end training of IMavatars from videos. We show quantitatively and qualitatively that our method improves geometry and covers a more complete expression space compared to state-of-the-art methods.