 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenLit: Reformulating Single-Image Relighting as Video Generation
Paper and Code
Dec 15, 2024
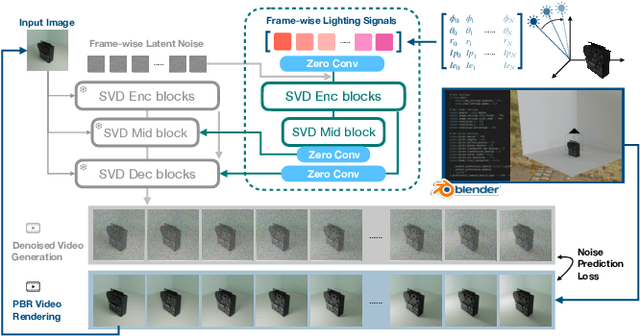
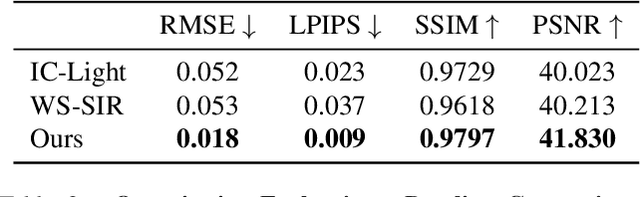

Manipulating the illumination within a single image represents a fundamental challenge in computer vision and graphics. This problem has been traditionally addressed using inverse rendering techniques, which require explicit 3D asset reconstruction and costly ray tracing simulations. Meanwhile, recent advancements in visual foundation models suggest that a new paradigm could soon be practical and possible -- one that replaces explicit physical models with networks that are trained on massive amounts of image and video data. In this paper, we explore the potential of exploiting video diffusion models, and in particular Stable Video Diffusion (SVD), in understanding the physical world to perform relighting tasks given a single image. Specifically, we introduce GenLit, a framework that distills the ability of a graphics engine to perform light manipulation into a video generation model, enabling users to directly insert and manipulate a point light in the 3D world within a given image and generate the results directly as a video sequence. We find that a model fine-tuned on only a small synthetic dataset (270 objects) is able to generalize to real images, enabling single-image relighting with realistic ray tracing effects and cast shadows. These results reveal the ability of video foundation models to capture rich information about lighting, material, and shape. Our findings suggest that such models, with minimal training, can be used for physically-based rendering without explicit physically asset reconstruction and complex ray tracing. This further suggests the potential of such models for controllable and physically accurate image synthesis tasks.