 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDAVE: A Deep Audio-Visual Embedding for Dynamic Saliency Prediction
Paper and Code
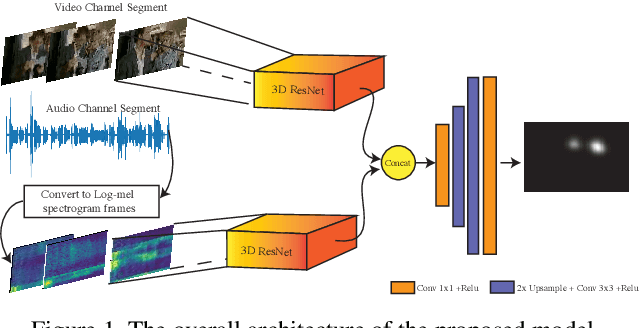
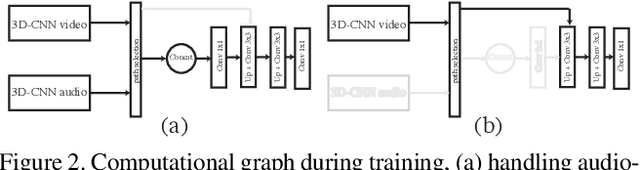
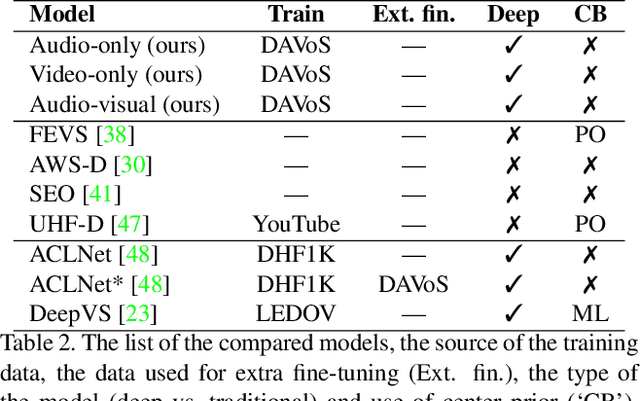
This paper presents a conceptually simple and effective Deep Audio-Visual Eembedding for dynamic saliency prediction dubbed ``DAVE". Several behavioral studies have shown a strong relation between auditory and visual cues for guiding gaze during scene free viewing. The existing video saliency models, however, only consider visual cues for predicting saliency over videos and neglect the auditory information that is ubiquitous in dynamic scenes. We propose a multimodal saliency model that utilizes audio and visual information for predicting saliency in videos. Our model consists of a two-stream encoder and a decoder. First, auditory and visual information are mapped into a feature space using 3D Convolutional Neural Networks (3D CNNs). Then, a decoder combines the features and maps them to a final saliency map. To train such model, data from various eye tracking datasets containing video and audio are pulled together. We further categorised videos into `social', `nature', and `miscellaneous' classes to analyze the models over different content types. Several analyses show that our audio-visual model outperforms video-based models significantly over all scores; overall and over individual categories. Contextual analysis of the model performance over the location of sound source reveals that the audio-visual model behaves similar to humans in attending to the location of sound source. Our endeavour demonstrates that audio is an important signal that can boost video saliency prediction and help getting closer to human performance.