 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeometric Image Correspondence Verification by Dense Pixel Matching
Apr 15, 2019

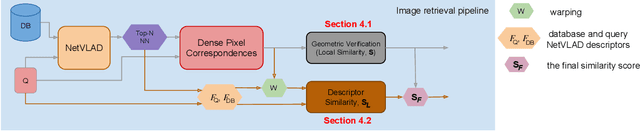
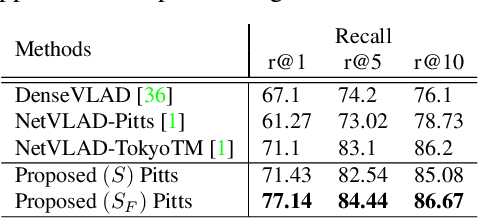
This paper addresses the problem of determining dense pixel correspondences between two images and its application to geometric correspondence verification in image retrieval. The main contribution is a geometric correspondence verification approach for re-ranking a shortlist of retrieved database images based on their dense pair-wise matching with the query image at a pixel level. We determine a set of cyclically consistent dense pixel matches between the pair of images and evaluate local similarity of matched pixels using neural network based image descriptors. Final re-ranking is based on a novel similarity function, which fuses the local similarity metric with a global similarity metric and a geometric consistency measure computed for the matched pixels. For dense matching our approach utilizes a modified version of a recently proposed dense geometric correspondence network (DGC-Net), which we also improve by optimizing the architecture. The proposed model and similarity metric compare favourably to the state-of-the-art image retrieval methods. In addition, we apply our method to the problem of long-term visual localization demonstrating promising results and generalization across datasets.
CubiCasa5K: A Dataset and an Improved Multi-Task Model for Floorplan Image Analysis
Apr 03, 2019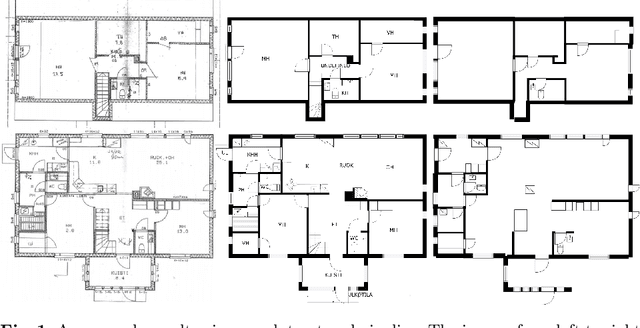

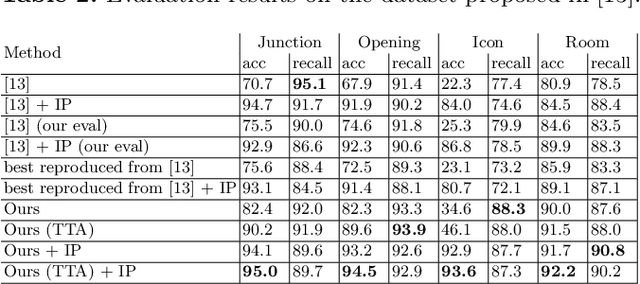
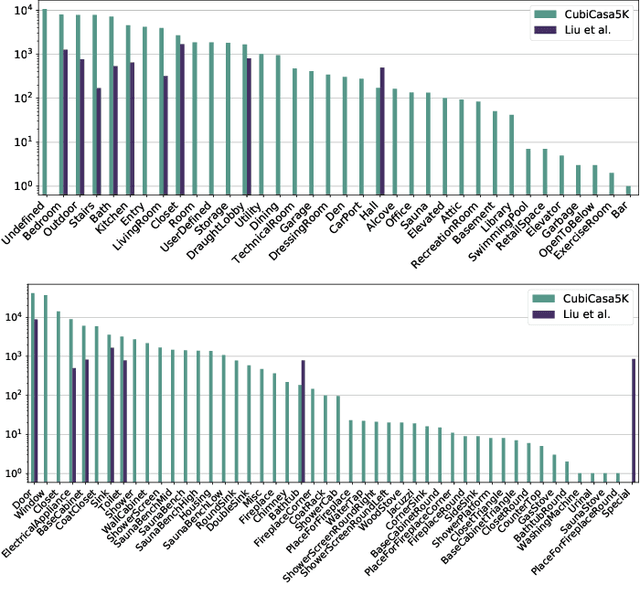
Better understanding and modelling of building interiors and the emergence of more impressive AR/VR technology has brought up the need for automatic parsing of floorplan images. However, there is a clear lack of representative datasets to investigate the problem further. To address this shortcoming, this paper presents a novel image dataset called CubiCasa5K, a large-scale floorplan image dataset containing 5000 samples annotated into over 80 floorplan object categories. The dataset annotations are performed in a dense and versatile manner by using polygons for separating the different objects. Diverging from the classical approaches based on strong heuristics and low-level pixel operations, we present a method relying on an improved multi-task convolutional neural network. By releasing the novel dataset and our implementations, this study significantly boosts the research on automatic floorplan image analysis as it provides a richer set of tools for investigating the problem in a more comprehensive manner.
Scene Coordinate Regression with Angle-Based Reprojection Loss for Camera Relocalization
Sep 30, 2018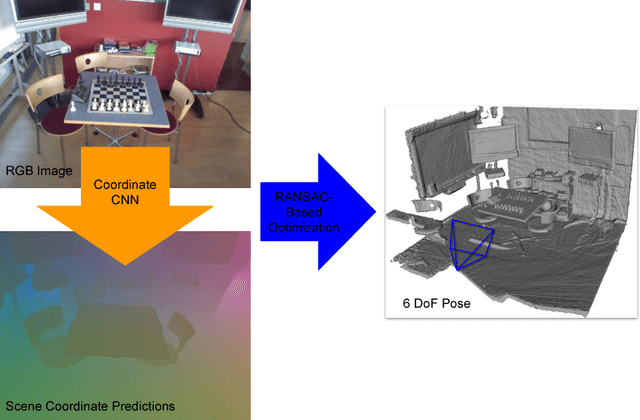


Image-based camera relocalization is an important problem in computer vision and robotics. Recent works utilize convolutional neural networks (CNNs) to regress for pixels in a query image their corresponding 3D world coordinates in the scene. The final pose is then solved via a RANSAC-based optimization scheme using the predicted coordinates. Usually, the CNN is trained with ground truth scene coordinates, but it has also been shown that the network can discover 3D scene geometry automatically by minimizing single-view reprojection loss. However, due to the deficiencies of the reprojection loss, the network needs to be carefully initialized. In this paper, we present a new angle-based reprojection loss, which resolves the issues of the original reprojection loss. With this new loss function, the network can be trained without careful initialization, and the system achieves more accurate results. The new loss also enables us to utilize available multi-view constraints, which further improve performance.
Full-Frame Scene Coordinate Regression for Image-Based Localization
Jun 25, 2018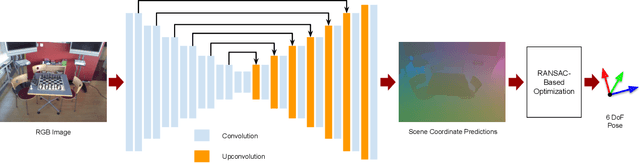

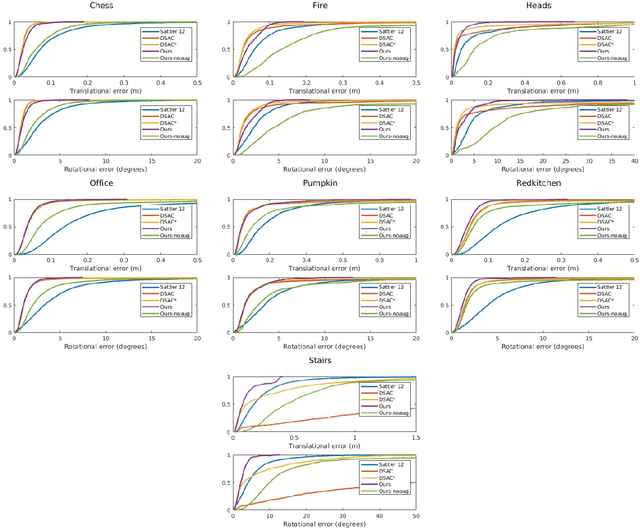
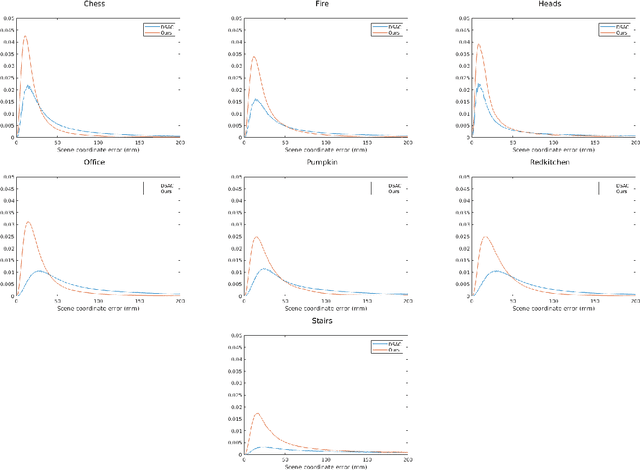
Image-based localization, or camera relocalization, is a fundamental problem in computer vision and robotics, and it refers to estimating camera pose from an image. Recent state-of-the-art approaches use learning based methods, such as Random Forests (RFs) and Convolutional Neural Networks (CNNs), to regress for each pixel in the image its corresponding position in the scene's world coordinate frame, and solve the final pose via a RANSAC-based optimization scheme using the predicted correspondences. In this paper, instead of in a patch-based manner, we propose to perform the scene coordinate regression in a full-frame manner to make the computation efficient at test time and, more importantly, to add more global context to the regression process to improve the robustness. To do so, we adopt a fully convolutional encoder-decoder neural network architecture which accepts a whole image as input and produces scene coordinate predictions for all pixels in the image. However, using more global context is prone to overfitting. To alleviate this issue, we propose to use data augmentation to generate more data for training. In addition to the data augmentation in 2D image space, we also augment the data in 3D space. We evaluate our approach on the publicly available 7-Scenes dataset, and experiments show that it has better scene coordinate predictions and achieves state-of-the-art results in localization with improved robustness on the hardest frames (e.g., frames with repeated structures).
Image-based Localization using Hourglass Networks
Aug 24, 2017



In this paper, we propose an encoder-decoder convolutional neural network (CNN) architecture for estimating camera pose (orientation and location) from a single RGB-image. The architecture has a hourglass shape consisting of a chain of convolution and up-convolution layers followed by a regression part. The up-convolution layers are introduced to preserve the fine-grained information of the input image. Following the common practice, we train our model in end-to-end manner utilizing transfer learning from large scale classification data. The experiments demonstrate the performance of the approach on data exhibiting different lighting conditions, reflections, and motion blur. The results indicate a clear improvement over the previous state-of-the-art even when compared to methods that utilize sequence of test frames instead of a single frame.
Relative Camera Pose Estimation Using Convolutional Neural Networks
Jul 28, 2017
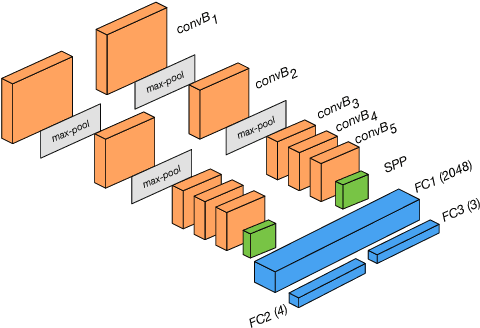


This paper presents a convolutional neural network based approach for estimating the relative pose between two cameras. The proposed network takes RGB images from both cameras as input and directly produces the relative rotation and translation as output. The system is trained in an end-to-end manner utilising transfer learning from a large scale classification dataset. The introduced approach is compared with widely used local feature based methods (SURF, ORB) and the results indicate a clear improvement over the baseline. In addition, a variant of the proposed architecture containing a spatial pyramid pooling (SPP) layer is evaluated and shown to further improve the performance.