 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Theoretical Investigation of Graph Degree as an Unsupervised Normality Measure
Paper and Code
Feb 05, 2018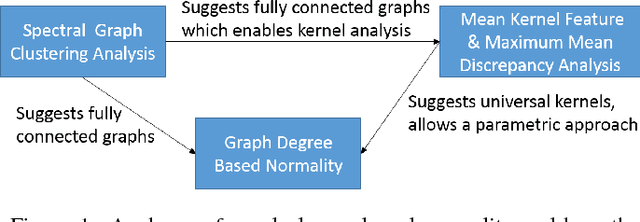
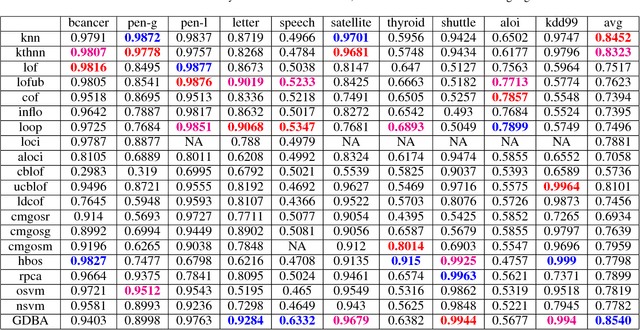


For a graph representation of a dataset, a straightforward normality measure for a sample can be its graph degree. Considering a weighted graph, degree of a sample is the sum of the corresponding row's values in a similarity matrix. The measure is intuitive given the abnormal samples are usually rare and they are dissimilar to the rest of the data. In order to have an in-depth theoretical understanding, in this manuscript, we investigate the graph degree in spectral graph clustering based and kernel based point of views and draw connections to a recent kernel method for the two sample problem. We show that our analyses guide us to choose fully-connected graphs whose edge weights are calculated via universal kernels. We show that a simple graph degree based unsupervised anomaly detection method with the above properties, achieves higher accuracy compared to other unsupervised anomaly detection methods on average over 10 widely used datasets. We also provide an extensive analysis on the effect of the kernel parameter on the method's accuracy.