 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFew-shot Continual Relation Extraction via Open Information Extraction
Feb 23, 2025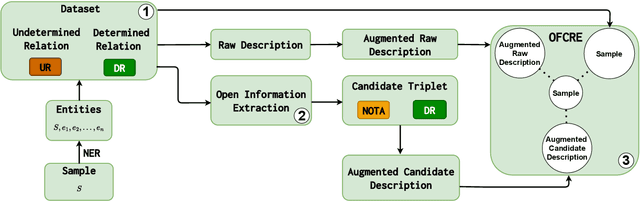
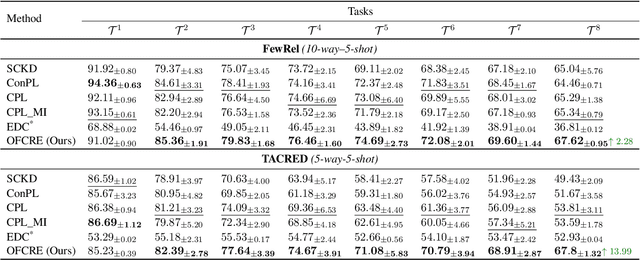
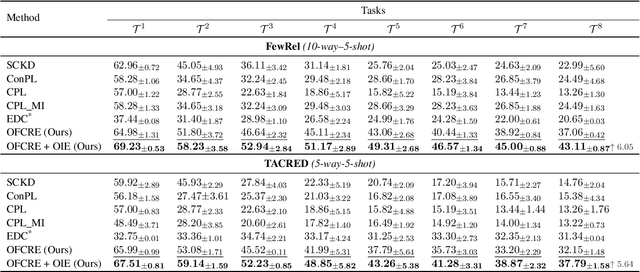
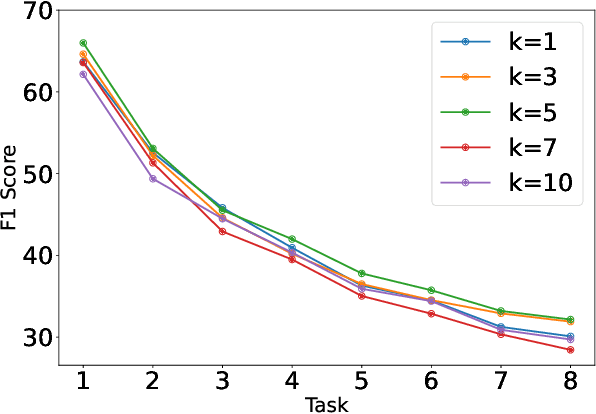
Typically, Few-shot Continual Relation Extraction (FCRE) models must balance retaining prior knowledge while adapting to new tasks with extremely limited data. However, real-world scenarios may also involve unseen or undetermined relations that existing methods still struggle to handle. To address these challenges, we propose a novel approach that leverages the Open Information Extraction concept of Knowledge Graph Construction (KGC). Our method not only exposes models to all possible pairs of relations, including determined and undetermined labels not available in the training set, but also enriches model knowledge with diverse relation descriptions, thereby enhancing knowledge retention and adaptability in this challenging scenario. In the perspective of KGC, this is the first work explored in the setting of Continual Learning, allowing efficient expansion of the graph as the data evolves. Experimental results demonstrate our superior performance compared to other state-of-the-art FCRE baselines, as well as the efficiency in handling dynamic graph construction in this setting.
Leveraging Hierarchical Taxonomies in Prompt-based Continual Learning
Oct 06, 2024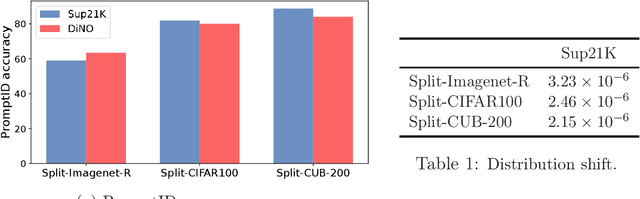
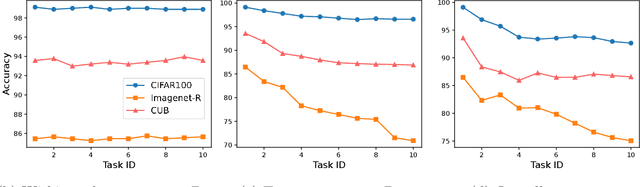
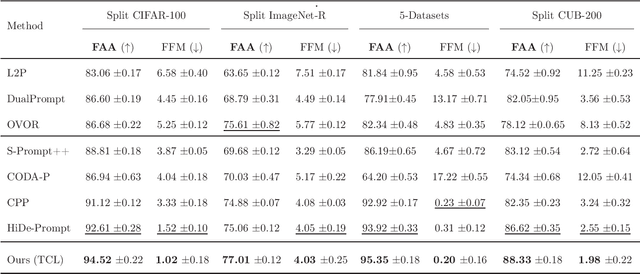
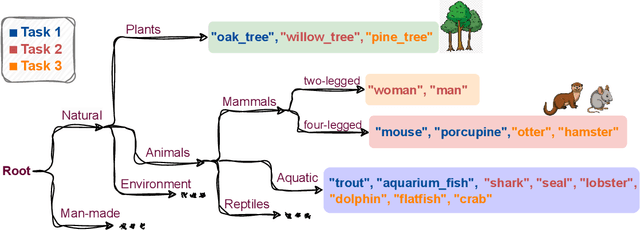
Drawing inspiration from human learning behaviors, this work proposes a novel approach to mitigate catastrophic forgetting in Prompt-based Continual Learning models by exploiting the relationships between continuously emerging class data. We find that applying human habits of organizing and connecting information can serve as an efficient strategy when training deep learning models. Specifically, by building a hierarchical tree structure based on the expanding set of labels, we gain fresh insights into the data, identifying groups of similar classes could easily cause confusion. Additionally, we delve deeper into the hidden connections between classes by exploring the original pretrained model's behavior through an optimal transport-based approach. From these insights, we propose a novel regularization loss function that encourages models to focus more on challenging knowledge areas, thereby enhancing overall performance. Experimentally, our method demonstrated significant superiority over the most robust state-of-the-art models on various benchmarks.