 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePersonaLens: A Benchmark for Personalization Evaluation in Conversational AI Assistants
Jun 11, 2025Large language models (LLMs) have advanced conversational AI assistants. However, systematically evaluating how well these assistants apply personalization--adapting to individual user preferences while completing tasks--remains challenging. Existing personalization benchmarks focus on chit-chat, non-conversational tasks, or narrow domains, failing to capture the complexities of personalized task-oriented assistance. To address this, we introduce PersonaLens, a comprehensive benchmark for evaluating personalization in task-oriented AI assistants. Our benchmark features diverse user profiles equipped with rich preferences and interaction histories, along with two specialized LLM-based agents: a user agent that engages in realistic task-oriented dialogues with AI assistants, and a judge agent that employs the LLM-as-a-Judge paradigm to assess personalization, response quality, and task success. Through extensive experiments with current LLM assistants across diverse tasks, we reveal significant variability in their personalization capabilities, providing crucial insights for advancing conversational AI systems.
Hyperbolic Residual Quantization: Discrete Representations for Data with Latent Hierarchies
May 18, 2025Hierarchical data arise in countless domains, from biological taxonomies and organizational charts to legal codes and knowledge graphs. Residual Quantization (RQ) is widely used to generate discrete, multitoken representations for such data by iteratively quantizing residuals in a multilevel codebook. However, its reliance on Euclidean geometry can introduce fundamental mismatches that hinder modeling of hierarchical branching, necessary for faithful representation of hierarchical data. In this work, we propose Hyperbolic Residual Quantization (HRQ), which embeds data natively in a hyperbolic manifold and performs residual quantization using hyperbolic operations and distance metrics. By adapting the embedding network, residual computation, and distance metric to hyperbolic geometry, HRQ imparts an inductive bias that aligns naturally with hierarchical branching. We claim that HRQ in comparison to RQ can generate more useful for downstream tasks discrete hierarchical representations for data with latent hierarchies. We evaluate HRQ on two tasks: supervised hierarchy modeling using WordNet hypernym trees, where the model is supervised to learn the latent hierarchy - and hierarchy discovery, where, while latent hierarchy exists in the data, the model is not directly trained or evaluated on a task related to the hierarchy. Across both scenarios, HRQ hierarchical tokens yield better performance on downstream tasks compared to Euclidean RQ with gains of up to $20\%$ for the hierarchy modeling task. Our results demonstrate that integrating hyperbolic geometry into discrete representation learning substantially enhances the ability to capture latent hierarchies.
Source Identification: A Self-Supervision Task for Dense Prediction
Jul 05, 2023



The paradigm of self-supervision focuses on representation learning from raw data without the need of labor-consuming annotations, which is the main bottleneck of current data-driven methods. Self-supervision tasks are often used to pre-train a neural network with a large amount of unlabeled data and extract generic features of the dataset. The learned model is likely to contain useful information which can be transferred to the downstream main task and improve performance compared to random parameter initialization. In this paper, we propose a new self-supervision task called source identification (SI), which is inspired by the classic blind source separation problem. Synthetic images are generated by fusing multiple source images and the network's task is to reconstruct the original images, given the fused images. A proper understanding of the image content is required to successfully solve the task. We validate our method on two medical image segmentation tasks: brain tumor segmentation and white matter hyperintensities segmentation. The results show that the proposed SI task outperforms traditional self-supervision tasks for dense predictions including inpainting, pixel shuffling, intensity shift, and super-resolution. Among variations of the SI task fusing images of different types, fusing images from different patients performs best.
Unsupervised Sentence-embeddings by Manifold Approximation and Projection
Feb 07, 2021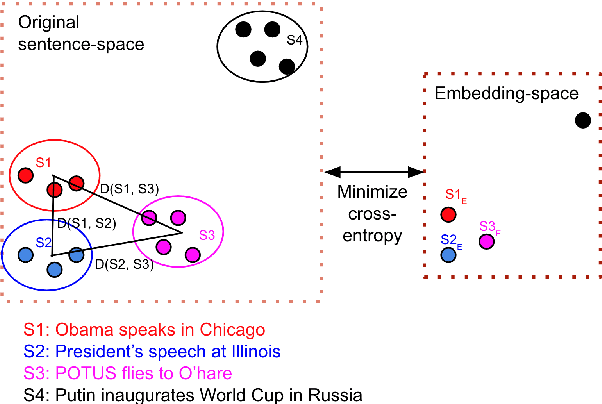


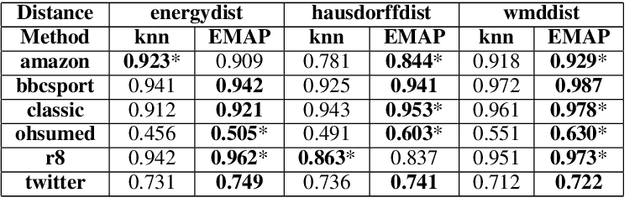
The concept of unsupervised universal sentence encoders has gained traction recently, wherein pre-trained models generate effective task-agnostic fixed-dimensional representations for phrases, sentences and paragraphs. Such methods are of varying complexity, from simple weighted-averages of word vectors to complex language-models based on bidirectional transformers. In this work we propose a novel technique to generate sentence-embeddings in an unsupervised fashion by projecting the sentences onto a fixed-dimensional manifold with the objective of preserving local neighbourhoods in the original space. To delineate such neighbourhoods we experiment with several set-distance metrics, including the recently proposed Word Mover's distance, while the fixed-dimensional projection is achieved by employing a scalable and efficient manifold approximation method rooted in topological data analysis. We test our approach, which we term EMAP or Embeddings by Manifold Approximation and Projection, on six publicly available text-classification datasets of varying size and complexity. Empirical results show that our method consistently performs similar to or better than several alternative state-of-the-art approaches.
Revisiting Edge Detection in Convolutional Neural Networks
Dec 25, 2020
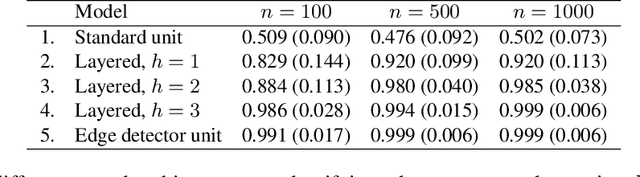


The ability to detect edges is a fundamental attribute necessary to truly capture visual concepts. In this paper, we prove that edges cannot be represented properly in the first convolutional layer of a neural network, and further show that they are poorly captured in popular neural network architectures such as VGG-16 and ResNet. The neural networks are found to rely on color information, which might vary in unexpected ways outside of the datasets used for their evaluation. To improve their robustness, we propose edge-detection units and show that they reduce performance loss and generate qualitatively different representations. By comparing various models, we show that the robustness of edge detection is an important factor contributing to the robustness of models against color noise.
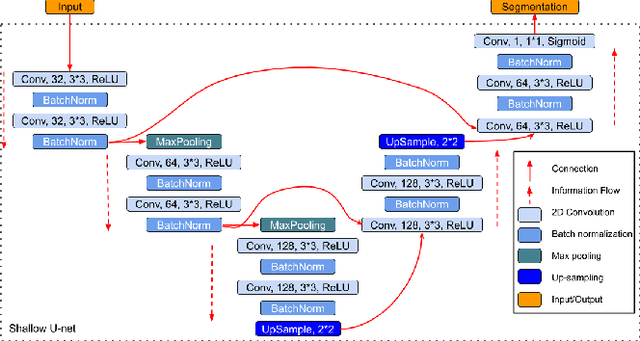
Region-of-interest guided Supervoxel Inpainting for Self-supervision
Jun 26, 2020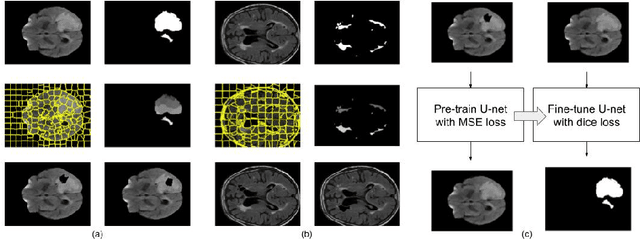
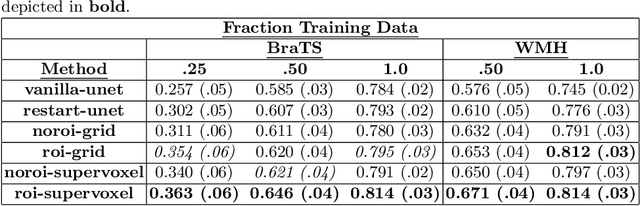
Self-supervised learning has proven to be invaluable in making best use of all of the available data in biomedical image segmentation. One particularly simple and effective mechanism to achieve self-supervision is inpainting, the task of predicting arbitrary missing areas based on the rest of an image. In this work, we focus on image inpainting as the self-supervised proxy task, and propose two novel structural changes to further enhance the performance of a deep neural network. We guide the process of generating images to inpaint by using supervoxel-based masking instead of random masking, and also by focusing on the area to be segmented in the primary task, which we term as the region-of-interest. We postulate that these additions force the network to learn semantics that are more attuned to the primary task, and test our hypotheses on two applications: brain tumour and white matter hyperintensities segmentation. We empirically show that our proposed approach consistently outperforms both supervised CNNs, without any self-supervision, and conventional inpainting-based self-supervision methods on both large and small training set sizes.
Spectral Data Augmentation Techniques to quantify Lung Pathology from CT-images
Apr 24, 2020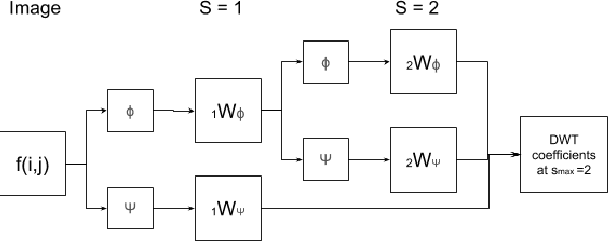
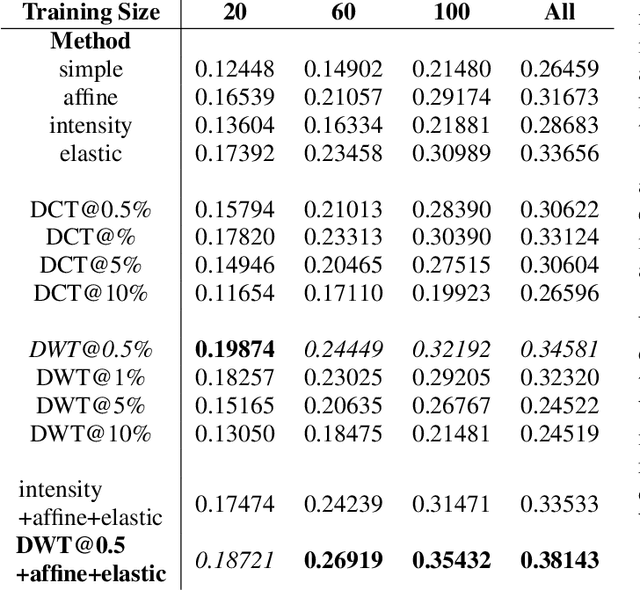

Data augmentation is of paramount importance in biomedical image processing tasks, characterized by inadequate amounts of labelled data, to best use all of the data that is present. In-use techniques range from intensity transformations and elastic deformations, to linearly combining existing data points to make new ones. In this work, we propose the use of spectral techniques for data augmentation, using the discrete cosine and wavelet transforms. We empirically evaluate our approaches on a CT texture analysis task to detect abnormal lung-tissue in patients with cystic fibrosis. Empirical experiments show that the proposed spectral methods perform favourably as compared to the existing methods. When used in combination with existing methods, our proposed approach can increase the relative minor class segmentation performance by 44.1% over a simple replication baseline.
Unsupervised Image Segmentation using the Deffuant-Weisbuch Model from Social Dynamics
Jun 02, 2016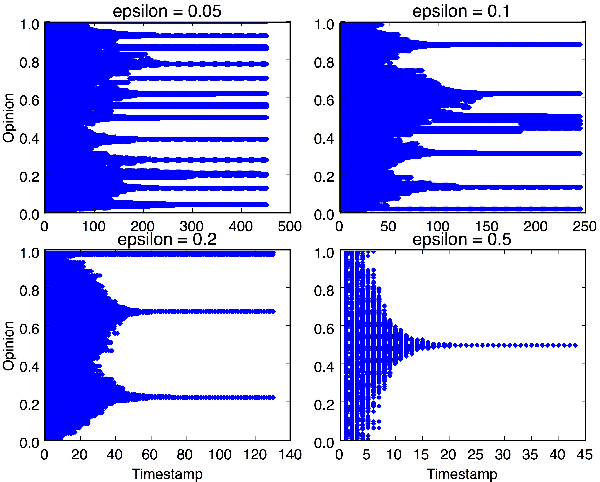


Unsupervised image segmentation algorithms aim at identifying disjoint homogeneous regions in an image, and have been subject to considerable attention in the machine vision community. In this paper, a popular theoretical model with it's origins in statistical physics and social dynamics, known as the Deffuant-Weisbuch model, is applied to the image segmentation problem. The Deffuant-Weisbuch model has been found to be useful in modelling the evolution of a closed system of interacting agents characterised by their opinions or beliefs, leading to the formation of clusters of agents who share a similar opinion or belief at steady state. In the context of image segmentation, this paper considers a pixel as an agent and it's colour property as it's opinion, with opinion updates as per the Deffuant-Weisbuch model. Apart from applying the basic model to image segmentation, this paper incorporates adjacency and neighbourhood information in the model, which factors in the local similarity and smoothness properties of images. Convergence is reached when the number of unique pixel opinions, i.e., the number of colour centres, matches the pre-specified number of clusters. Experiments are performed on a set of images from the Berkeley Image Segmentation Dataset and the results are analysed both qualitatively and quantitatively, which indicate that this simple and intuitive method is promising for image segmentation. To the best of the knowledge of the author, this is the first work where a theoretical model from statistical physics and social dynamics has been successfully applied to image processing.