 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSurvey on Question Answering over Visually Rich Documents: Methods, Challenges, and Trends
Jan 04, 2025Using Large Language Models (LLMs) for Visually-rich Document Understanding (VrDU) has significantly improved performance on tasks requiring both comprehension and generation, such as question answering, albeit introducing new challenges. This survey explains how VrDU models enhanced by LLMs function, covering methods for integrating VrD features into LLMs and highlighting key challenges.
TelcoLM: collecting data, adapting, and benchmarking language models for the telecommunication domain
Dec 20, 2024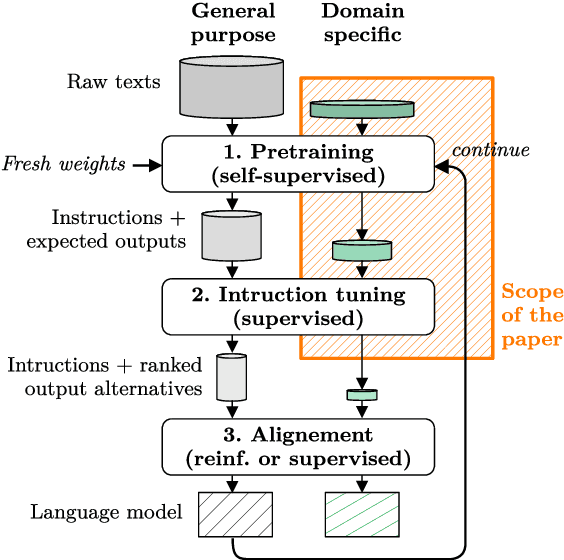

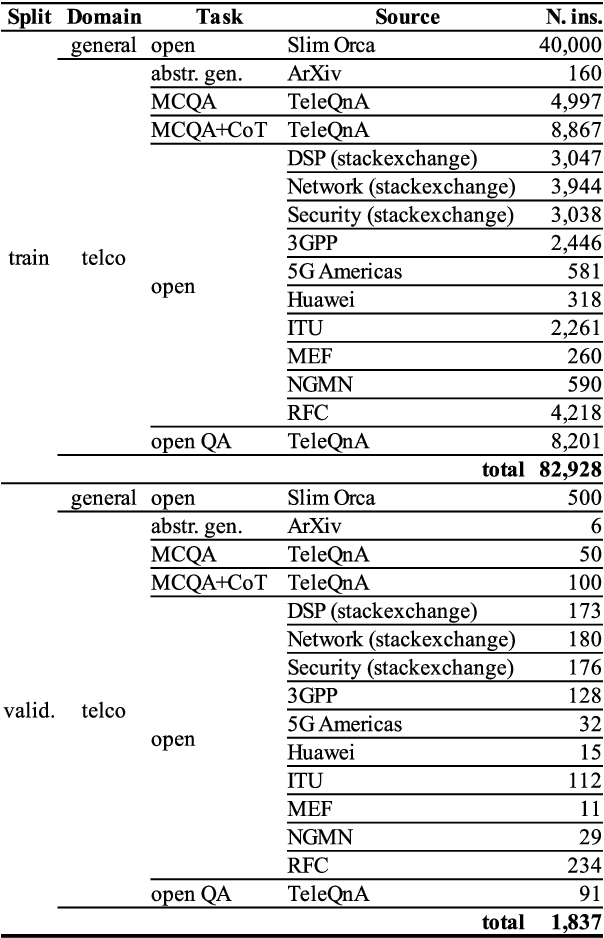

Despite outstanding processes in many tasks, Large Language Models (LLMs) still lack accuracy when dealing with highly technical domains. Especially, telecommunications (telco) is a particularly challenging domain due the large amount of lexical, semantic and conceptual peculiarities. Yet, this domain holds many valuable use cases, directly linked to industrial needs. Hence, this paper studies how LLMs can be adapted to the telco domain. It reports our effort to (i) collect a massive corpus of domain-specific data (800M tokens, 80K instructions), (ii) perform adaptation using various methodologies, and (iii) benchmark them against larger generalist models in downstream tasks that require extensive knowledge of telecommunications. Our experiments on Llama-2-7b show that domain-adapted models can challenge the large generalist models. They also suggest that adaptation can be restricted to a unique instruction-tuning step, dicarding the need for any fine-tuning on raw texts beforehand.
Uncertainty Management in the Construction of Knowledge Graphs: a Survey
May 27, 2024
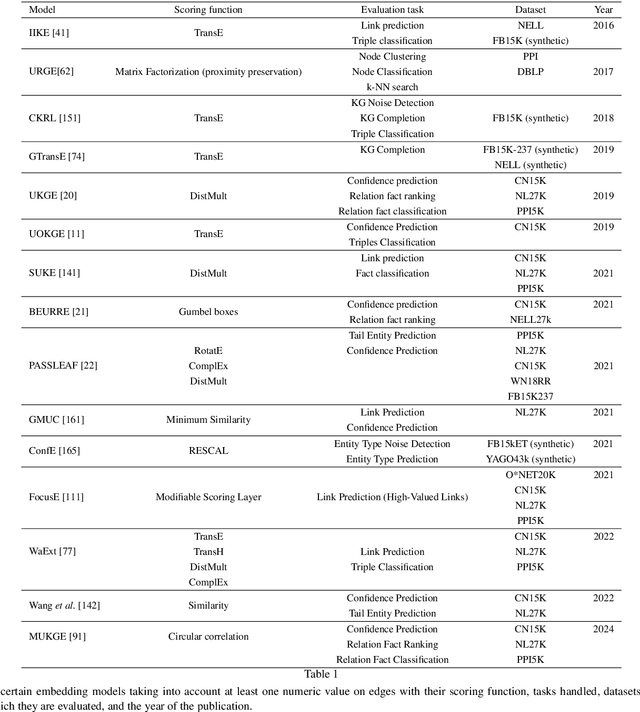
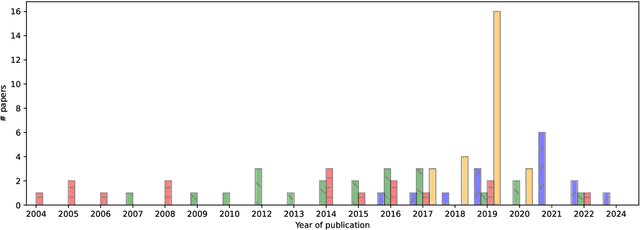
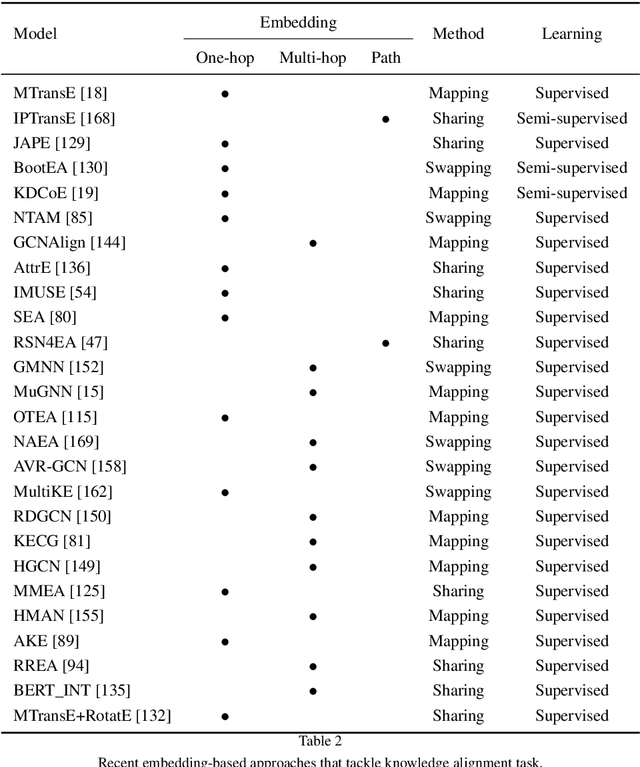
Knowledge Graphs (KGs) are a major asset for companies thanks to their great flexibility in data representation and their numerous applications, e.g., vocabulary sharing, Q/A or recommendation systems. To build a KG it is a common practice to rely on automatic methods for extracting knowledge from various heterogeneous sources. But in a noisy and uncertain world, knowledge may not be reliable and conflicts between data sources may occur. Integrating unreliable data would directly impact the use of the KG, therefore such conflicts must be resolved. This could be done manually by selecting the best data to integrate. This first approach is highly accurate, but costly and time-consuming. That is why recent efforts focus on automatic approaches, which represents a challenging task since it requires handling the uncertainty of extracted knowledge throughout its integration into the KG. We survey state-of-the-art approaches in this direction and present constructions of both open and enterprise KGs and how their quality is maintained. We then describe different knowledge extraction methods, introducing additional uncertainty. We also discuss downstream tasks after knowledge acquisition, including KG completion using embedding models, knowledge alignment, and knowledge fusion in order to address the problem of knowledge uncertainty in KG construction. We conclude with a discussion on the remaining challenges and perspectives when constructing a KG taking into account uncertainty.
A complete formalized knowledge representation model for advanced digital forensics timeline analysis
Feb 21, 2019
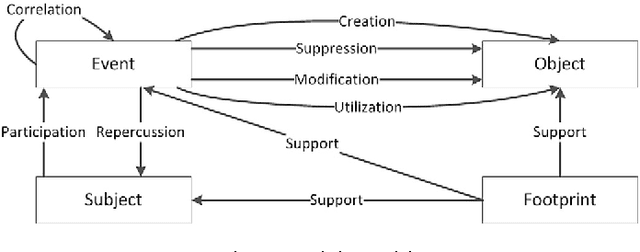
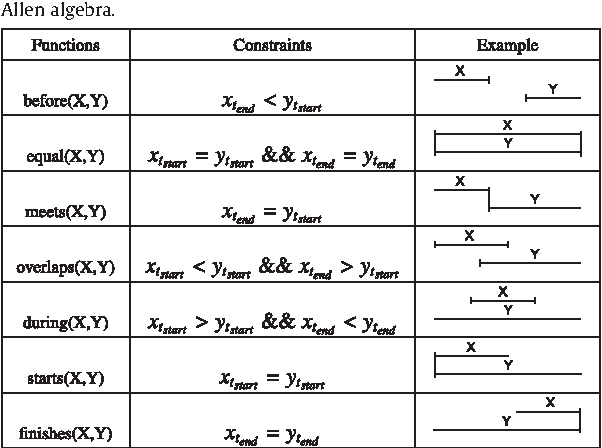
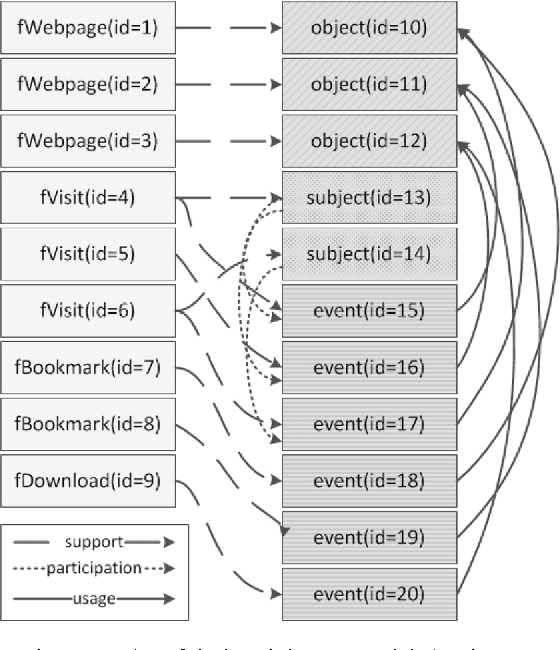
Having a clear view of events that occurred over time is a difficult objective to achieve in digital investigations (DI). Event reconstruction, which allows investigators to understand the timeline of a crime, is one of the most important step of a DI process. This complex task requires exploration of a large amount of events due to the pervasiveness of new technologies nowadays. Any evidence produced at the end of the investigative process must also meet the requirements of the courts, such as reproducibility, verifiability, validation, etc. For this purpose, we propose a new methodology, supported by theoretical concepts, that can assist investigators through the whole process including the construction and the interpretation of the events describing the case. The proposed approach is based on a model which integrates knowledge of experts from the fields of digital forensics and software development to allow a semantically rich representation of events related to the incident. The main purpose of this model is to allow the analysis of these events in an automatic and efficient way. This paper describes the approach and then focuses on the main conceptual and formal aspects: a formal incident modelization and operators for timeline reconstruction and analysis.