 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUncertainty Management in the Construction of Knowledge Graphs: a Survey
Paper and Code

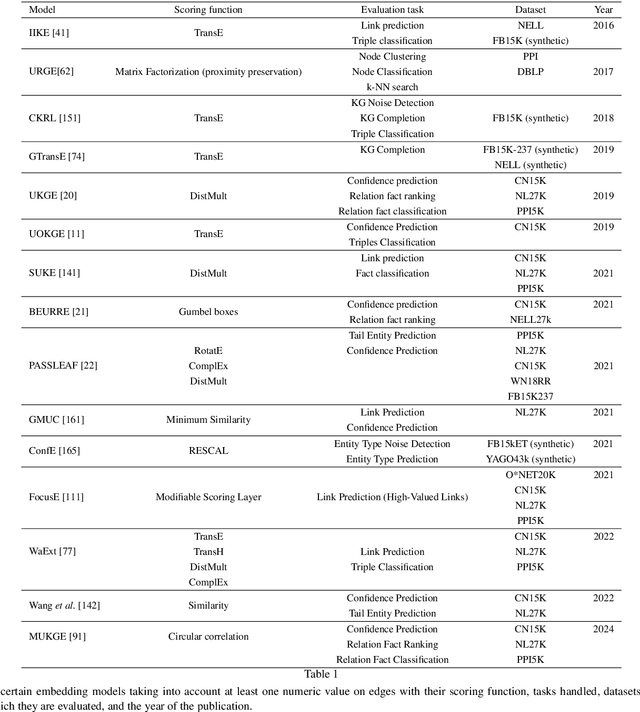
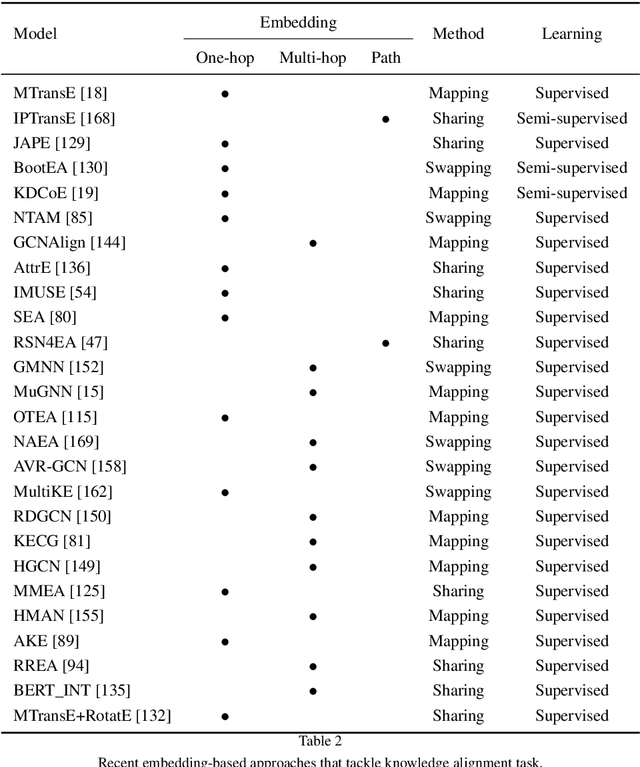
Knowledge Graphs (KGs) are a major asset for companies thanks to their great flexibility in data representation and their numerous applications, e.g., vocabulary sharing, Q/A or recommendation systems. To build a KG it is a common practice to rely on automatic methods for extracting knowledge from various heterogeneous sources. But in a noisy and uncertain world, knowledge may not be reliable and conflicts between data sources may occur. Integrating unreliable data would directly impact the use of the KG, therefore such conflicts must be resolved. This could be done manually by selecting the best data to integrate. This first approach is highly accurate, but costly and time-consuming. That is why recent efforts focus on automatic approaches, which represents a challenging task since it requires handling the uncertainty of extracted knowledge throughout its integration into the KG. We survey state-of-the-art approaches in this direction and present constructions of both open and enterprise KGs and how their quality is maintained. We then describe different knowledge extraction methods, introducing additional uncertainty. We also discuss downstream tasks after knowledge acquisition, including KG completion using embedding models, knowledge alignment, and knowledge fusion in order to address the problem of knowledge uncertainty in KG construction. We conclude with a discussion on the remaining challenges and perspectives when constructing a KG taking into account uncertainty.