 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRedundancy-Free View Alignment for Multimodal Human Activity Recognition with Arbitrarily Missing Views
Feb 09, 2026Multimodal multiview learning seeks to integrate information from diverse sources to enhance task performance. Existing approaches often struggle with flexible view configurations, including arbitrary view combinations, numbers of views, and heterogeneous modalities. Focusing on the context of human activity recognition, we propose RALIS, a model that combines multiview contrastive learning with a mixture-of-experts module to support arbitrary view availability during both training and inference. Instead of trying to reconstruct missing views, an adjusted center contrastive loss is used for self-supervised representation learning and view alignment, mitigating the impact of missing views on multiview fusion. This loss formulation allows for the integration of view weights to account for view quality. Additionally, it reduces computational complexity from $O(V^2)$ to $O(V)$, where $V$ is the number of views. To address residual discrepancies not captured by contrastive learning, we employ a mixture-of-experts module with a specialized load balancing strategy, tasked with adapting to arbitrary view combinations. We highlight the geometric relationship among components in our model and how they combine well in the latent space. RALIS is validated on four datasets encompassing inertial and human pose modalities, with the number of views ranging from three to nine, demonstrating its performance and flexibility.
SoK: Behind the Accuracy of Complex Human Activity Recognition Using Deep Learning
Apr 25, 2024Human Activity Recognition (HAR) is a well-studied field with research dating back to the 1980s. Over time, HAR technologies have evolved significantly from manual feature extraction, rule-based algorithms, and simple machine learning models to powerful deep learning models, from one sensor type to a diverse array of sensing modalities. The scope has also expanded from recognising a limited set of activities to encompassing a larger variety of both simple and complex activities. However, there still exist many challenges that hinder advancement in complex activity recognition using modern deep learning methods. In this paper, we comprehensively systematise factors leading to inaccuracy in complex HAR, such as data variety and model capacity. Among many sensor types, we give more attention to wearable and camera due to their prevalence. Through this Systematisation of Knowledge (SoK) paper, readers can gain a solid understanding of the development history and existing challenges of HAR, different categorisations of activities, obstacles in deep learning-based complex HAR that impact accuracy, and potential research directions.
FlexEdit: Flexible and Controllable Diffusion-based Object-centric Image Editing
Mar 28, 2024


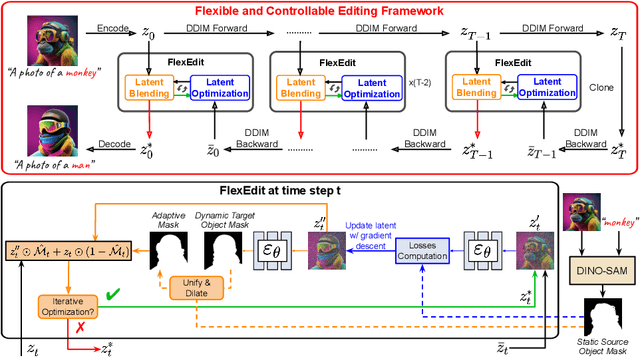
Our work addresses limitations seen in previous approaches for object-centric editing problems, such as unrealistic results due to shape discrepancies and limited control in object replacement or insertion. To this end, we introduce FlexEdit, a flexible and controllable editing framework for objects where we iteratively adjust latents at each denoising step using our FlexEdit block. Initially, we optimize latents at test time to align with specified object constraints. Then, our framework employs an adaptive mask, automatically extracted during denoising, to protect the background while seamlessly blending new content into the target image. We demonstrate the versatility of FlexEdit in various object editing tasks and curate an evaluation test suite with samples from both real and synthetic images, along with novel evaluation metrics designed for object-centric editing. We conduct extensive experiments on different editing scenarios, demonstrating the superiority of our editing framework over recent advanced text-guided image editing methods. Our project page is published at https://flex-edit.github.io/.
Virtual Fusion with Contrastive Learning for Single Sensor-based Activity Recognition
Dec 01, 2023



Various types of sensors can be used for Human Activity Recognition (HAR), and each of them has different strengths and weaknesses. Sometimes a single sensor cannot fully observe the user's motions from its perspective, which causes wrong predictions. While sensor fusion provides more information for HAR, it comes with many inherent drawbacks like user privacy and acceptance, costly set-up, operation, and maintenance. To deal with this problem, we propose Virtual Fusion - a new method that takes advantage of unlabeled data from multiple time-synchronized sensors during training, but only needs one sensor for inference. Contrastive learning is adopted to exploit the correlation among sensors. Virtual Fusion gives significantly better accuracy than training with the same single sensor, and in some cases, it even surpasses actual fusion using multiple sensors at test time. We also extend this method to a more general version called Actual Fusion within Virtual Fusion (AFVF), which uses a subset of training sensors during inference. Our method achieves state-of-the-art accuracy and F1-score on UCI-HAR and PAMAP2 benchmark datasets. Implementation is available upon request.