 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSoK: Timeline based event reconstruction for digital forensics: Terminology, methodology, and current challenges
Apr 25, 2025
Event reconstruction is a technique that examiners can use to attempt to infer past activities by analyzing digital artifacts. Despite its significance, the field suffers from fragmented research, with studies often focusing narrowly on aspects like timeline creation or tampering detection. This paper addresses the lack of a unified perspective by proposing a comprehensive framework for timeline-based event reconstruction, adapted from traditional forensic science models. We begin by harmonizing existing terminology and presenting a cohesive diagram that clarifies the relationships between key elements of the reconstruction process. Through a comprehensive literature survey, we classify and organize the main challenges, extending the discussion beyond common issues like data volume. Lastly, we highlight recent advancements and propose directions for future research, including specific research gaps. By providing a structured approach, key findings, and a clearer understanding of the underlying challenges, this work aims to strengthen the foundation of digital forensics.
SoK: Exploring the Potential of Large Language Models for Improving Digital Forensic Investigation Efficiency
Feb 29, 2024The growing number of cases requiring digital forensic analysis raises concerns about law enforcement's ability to conduct investigations promptly. Consequently, this systemisation of knowledge paper delves into the potential and effectiveness of integrating Large Language Models (LLMs) into digital forensic investigation to address these challenges. A thorough literature review is undertaken, encompassing existing digital forensic models, tools, LLMs, deep learning techniques, and the utilisation of LLMs in investigations. The review identifies current challenges within existing digital forensic processes and explores both the obstacles and possibilities of incorporating LLMs. In conclusion, the study asserts that the adoption of LLMs in digital forensics, with appropriate constraints, holds the potential to enhance investigation efficiency, improve traceability, and alleviate technical and judicial barriers faced by law enforcement entities.
Identifying document similarity using a fast estimation of the Levenshtein Distance based on compression and signatures
Jul 21, 2023Identifying document similarity has many applications, e.g., source code analysis or plagiarism detection. However, identifying similarities is not trivial and can be time complex. For instance, the Levenshtein Distance is a common metric to define the similarity between two documents but has quadratic runtime which makes it impractical for large documents where large starts with a few hundred kilobytes. In this paper, we present a novel concept that allows estimating the Levenshtein Distance: the algorithm first compresses documents to signatures (similar to hash values) using a user-defined compression ratio. Signatures can then be compared against each other (some constrains apply) where the outcome is the estimated Levenshtein Distance. Our evaluation shows promising results in terms of runtime efficiency and accuracy. In addition, we introduce a significance score allowing examiners to set a threshold and identify related documents.
ChatGPT for Digital Forensic Investigation: The Good, The Bad, and The Unknown
Jul 10, 2023

The disruptive application of ChatGPT (GPT-3.5, GPT-4) to a variety of domains has become a topic of much discussion in the scientific community and society at large. Large Language Models (LLMs), e.g., BERT, Bard, Generative Pre-trained Transformers (GPTs), LLaMA, etc., have the ability to take instructions, or prompts, from users and generate answers and solutions based on very large volumes of text-based training data. This paper assesses the impact and potential impact of ChatGPT on the field of digital forensics, specifically looking at its latest pre-trained LLM, GPT-4. A series of experiments are conducted to assess its capability across several digital forensic use cases including artefact understanding, evidence searching, code generation, anomaly detection, incident response, and education. Across these topics, its strengths and risks are outlined and a number of general conclusions are drawn. Overall this paper concludes that while there are some potential low-risk applications of ChatGPT within digital forensics, many are either unsuitable at present, since the evidence would need to be uploaded to the service, or they require sufficient knowledge of the topic being asked of the tool to identify incorrect assumptions, inaccuracies, and mistakes. However, to an appropriately knowledgeable user, it could act as a useful supporting tool in some circumstances.
AI Forensics: Did the Artificial Intelligence System Do It? Why?
May 27, 2020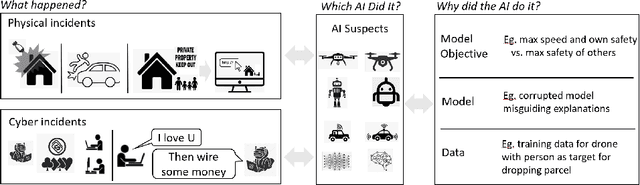

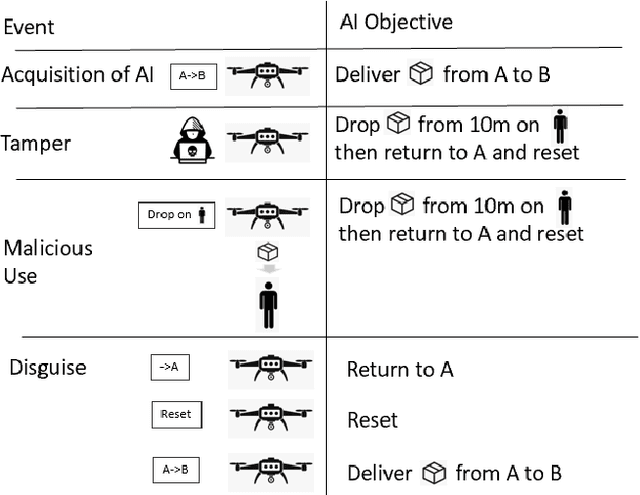

In an increasingly autonomous manner AI systems make decisions impacting our daily life. Their actions might cause accidents, harm or, more generally, violate regulations -- either intentionally or not. Thus, AI systems might be considered suspects for various events. Therefore, it is essential to relate particular events to an AI, its owner and its creator. Given a multitude of AI systems from multiple manufactures, potentially, altered by their owner or changing through self-learning, this seems non-trivial. This paper discusses how to identify AI systems responsible for incidents as well as their motives that might be "malicious by design". In addition to a conceptualization, we conduct two case studies based on reinforcement learning and convolutional neural networks to illustrate our proposed methods and challenges. Our cases illustrate that "catching AI systems" seems often far from trivial and requires extensive expertise in machine learning. Legislative measures that enforce mandatory information to be collected during operation of AI systems as well as means to uniquely identify systems might facilitate the problem.