 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCLPIPS: A Personalized Metric for AI-Generated Image Similarity
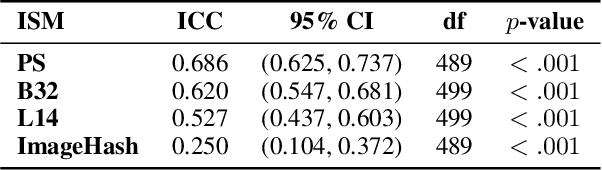
Mar 26, 2026Iterative prompt refinement is central to reproducing target images with text to image generative models. Previous studies have incorporated image similarity metrics (ISMs) as additional feedback to human users. Existing ISMs such as LPIPS and CLIP provide objective measures of image likeness but often fail to align with human judgments, particularly in context specific or user driven tasks. In this paper, we introduce Customized Learned Perceptual Image Patch Similarity (CLPIPS), a customized extension of LPIPS that adapts a metric's notion of similarity directly to human judgments. We aim to explore whether lightweight, human augmented fine tuning can meaningfully improve perceptual alignment, positioning similarity metrics as adaptive components for human in the loop workflows with text to image tools. We evaluate CLPIPS on a human subject dataset in which participants iteratively regenerate target images and rank generated outputs by perceived similarity. Using margin ranking loss on human ranked image pairs, we fine tune only the LPIPS layer combination weights and assess alignment via Spearman rank correlation and Intraclass Correlation Coefficient. Our results show that CLPIPS achieves stronger correlation and agreement with human judgments than baseline LPIPS. Rather than optimizing absolute metric performance, our work emphasizes improving alignment consistency between metric predictions and human ranks, demonstrating that even limited human specific fine tuning can meaningfully enhance perceptual alignment in human in the loop text to image workflows.
Prompt and Circumstances: Evaluating the Efficacy of Human Prompt Inference in AI-Generated Art
Jan 24, 2026The emerging field of AI-generated art has witnessed the rise of prompt marketplaces, where creators can purchase, sell, or share prompts to generate unique artworks. These marketplaces often assert ownership over prompts, claiming them as intellectual property. This paper investigates whether concealed prompts sold on prompt marketplaces can be considered bona fide intellectual property, given that humans and AI tools may be able to infer the prompts based on publicly advertised sample images accompanying each prompt on sale. Specifically, our study aims to assess (i) how accurately humans can infer the original prompt solely by examining an AI-generated image, with the goal of generating images similar to the original image, and (ii) the possibility of improving upon individual human and AI prompt inferences by crafting combined human and AI prompts with the help of a large language model. Although previous research has explored AI-driven prompt inference and protection strategies, our work is the first to incorporate a human subject study and examine collaborative human-AI prompt inference in depth. Our findings indicate that while prompts inferred by humans and prompts inferred through a combined human and AI effort can generate images with a moderate level of similarity, they are not as successful as using the original prompt. Moreover, combining human- and AI-inferred prompts using our suggested merging techniques did not improve performance over purely human-inferred prompts.
A Picture is Worth a Thousand Prompts? Efficacy of Iterative Human-Driven Prompt Refinement in Image Regeneration Tasks
Apr 29, 2025
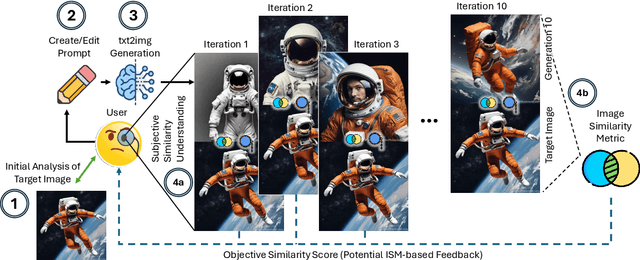

With AI-generated content becoming ubiquitous across the web, social media, and other digital platforms, it is vital to examine how such content are inspired and generated. The creation of AI-generated images often involves refining the input prompt iteratively to achieve desired visual outcomes. This study focuses on the relatively underexplored concept of image regeneration using AI, in which a human operator attempts to closely recreate a specific target image by iteratively refining their prompt. Image regeneration is distinct from normal image generation, which lacks any predefined visual reference. A separate challenge lies in determining whether existing image similarity metrics (ISMs) can provide reliable, objective feedback in iterative workflows, given that we do not fully understand if subjective human judgments of similarity align with these metrics. Consequently, we must first validate their alignment with human perception before assessing their potential as a feedback mechanism in the iterative prompt refinement process. To address these research gaps, we present a structured user study evaluating how iterative prompt refinement affects the similarity of regenerated images relative to their targets, while also examining whether ISMs capture the same improvements perceived by human observers. Our findings suggest that incremental prompt adjustments substantially improve alignment, verified through both subjective evaluations and quantitative measures, underscoring the broader potential of iterative workflows to enhance generative AI content creation across various application domains.
Promptly Yours? A Human Subject Study on Prompt Inference in AI-Generated Art
Oct 10, 2024
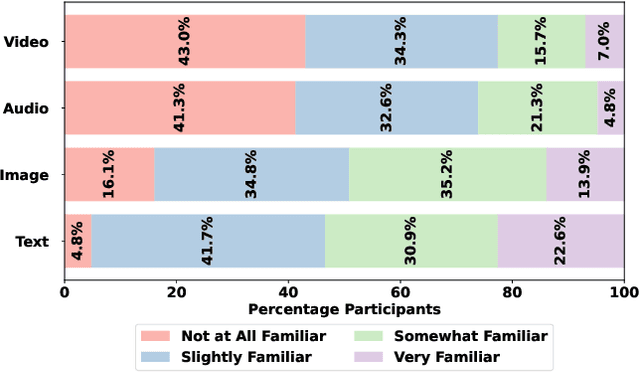
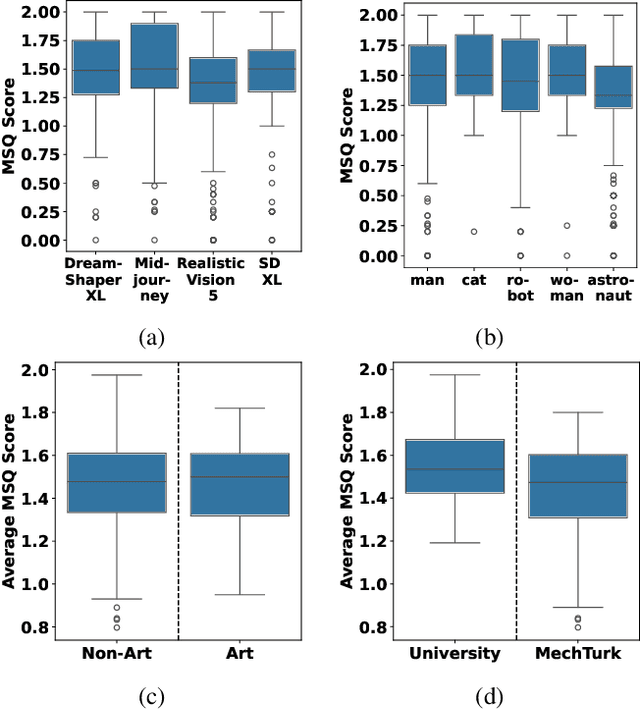

The emerging field of AI-generated art has witnessed the rise of prompt marketplaces, where creators can purchase, sell, or share prompts for generating unique artworks. These marketplaces often assert ownership over prompts, claiming them as intellectual property. This paper investigates whether concealed prompts sold on prompt marketplaces can be considered as secure intellectual property, given that humans and AI tools may be able to approximately infer the prompts based on publicly advertised sample images accompanying each prompt on sale. Specifically, our survey aims to assess (i) how accurately can humans infer the original prompt solely by examining an AI-generated image, with the goal of generating images similar to the original image, and (ii) the possibility of improving upon individual human and AI prompt inferences by crafting human-AI combined prompts with the help of a large language model. Although previous research has explored the use of AI and machine learning to infer (and also protect against) prompt inference, we are the first to include humans in the loop. Our findings indicate that while humans and human-AI collaborations can infer prompts and generate similar images with high accuracy, they are not as successful as using the original prompt.
Spiking Neural Networks in Vertical Federated Learning: Performance Trade-offs
Jul 24, 2024Federated machine learning enables model training across multiple clients while maintaining data privacy. Vertical Federated Learning (VFL) specifically deals with instances where the clients have different feature sets of the same samples. As federated learning models aim to improve efficiency and adaptability, innovative neural network architectures like Spiking Neural Networks (SNNs) are being leveraged to enable fast and accurate processing at the edge. SNNs, known for their efficiency over Artificial Neural Networks (ANNs), have not been analyzed for their applicability in VFL, thus far. In this paper, we investigate the benefits and trade-offs of using SNN models in a vertical federated learning setting. We implement two different federated learning architectures -- with model splitting and without model splitting -- that have different privacy and performance implications. We evaluate the setup using CIFAR-10 and CIFAR-100 benchmark datasets along with SNN implementations of VGG9 and ResNET classification models. Comparative evaluations demonstrate that the accuracy of SNN models is comparable to that of traditional ANNs for VFL applications, albeit significantly more energy efficient.
We Have a Package for You! A Comprehensive Analysis of Package Hallucinations by Code Generating LLMs
Jun 12, 2024


The reliance of popular programming languages such as Python and JavaScript on centralized package repositories and open-source software, combined with the emergence of code-generating Large Language Models (LLMs), has created a new type of threat to the software supply chain: package hallucinations. These hallucinations, which arise from fact-conflicting errors when generating code using LLMs, represent a novel form of package confusion attack that poses a critical threat to the integrity of the software supply chain. This paper conducts a rigorous and comprehensive evaluation of package hallucinations across different programming languages, settings, and parameters, exploring how different configurations of LLMs affect the likelihood of generating erroneous package recommendations and identifying the root causes of this phenomena. Using 16 different popular code generation models, across two programming languages and two unique prompt datasets, we collect 576,000 code samples which we analyze for package hallucinations. Our findings reveal that 19.7% of generated packages across all the tested LLMs are hallucinated, including a staggering 205,474 unique examples of hallucinated package names, further underscoring the severity and pervasiveness of this threat. We also implemented and evaluated mitigation strategies based on Retrieval Augmented Generation (RAG), self-detected feedback, and supervised fine-tuning. These techniques demonstrably reduced package hallucinations, with hallucination rates for one model dropping below 3%. While the mitigation efforts were effective in reducing hallucination rates, our study reveals that package hallucinations are a systemic and persistent phenomenon that pose a significant challenge for code generating LLMs.
Towards a Game-theoretic Understanding of Explanation-based Membership Inference Attacks
Apr 10, 2024
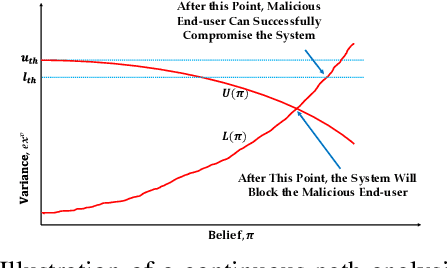
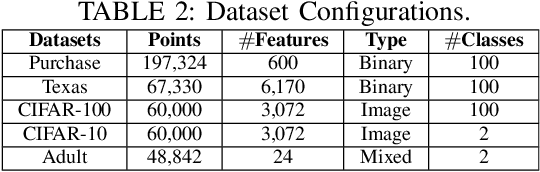
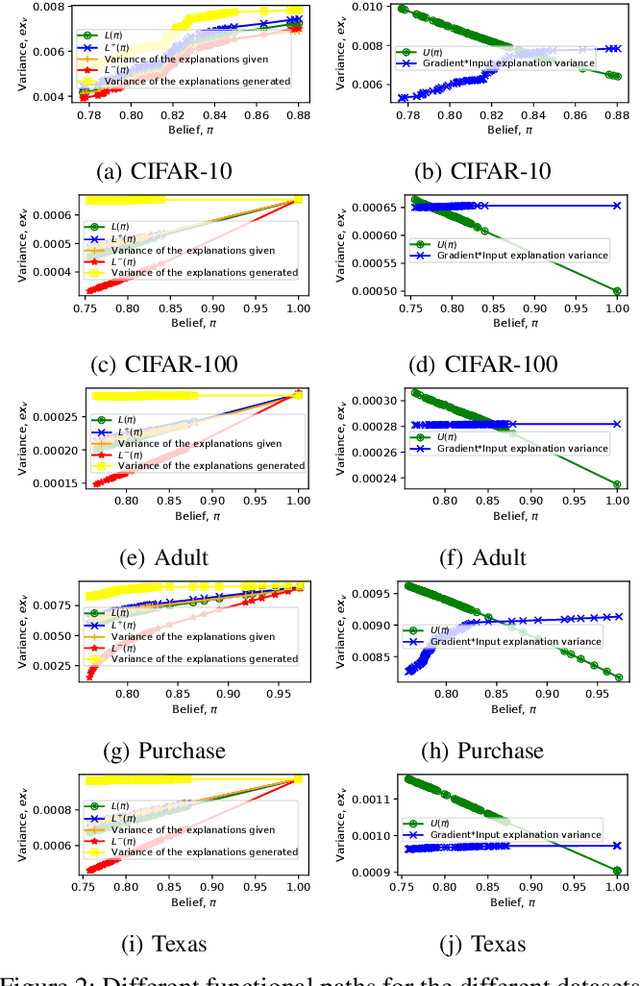
Model explanations improve the transparency of black-box machine learning (ML) models and their decisions; however, they can also be exploited to carry out privacy threats such as membership inference attacks (MIA). Existing works have only analyzed MIA in a single "what if" interaction scenario between an adversary and the target ML model; thus, it does not discern the factors impacting the capabilities of an adversary in launching MIA in repeated interaction settings. Additionally, these works rely on assumptions about the adversary's knowledge of the target model's structure and, thus, do not guarantee the optimality of the predefined threshold required to distinguish the members from non-members. In this paper, we delve into the domain of explanation-based threshold attacks, where the adversary endeavors to carry out MIA attacks by leveraging the variance of explanations through iterative interactions with the system comprising of the target ML model and its corresponding explanation method. We model such interactions by employing a continuous-time stochastic signaling game framework. In our framework, an adversary plays a stopping game, interacting with the system (having imperfect information about the type of an adversary, i.e., honest or malicious) to obtain explanation variance information and computing an optimal threshold to determine the membership of a datapoint accurately. First, we propose a sound mathematical formulation to prove that such an optimal threshold exists, which can be used to launch MIA. Then, we characterize the conditions under which a unique Markov perfect equilibrium (or steady state) exists in this dynamic system. By means of a comprehensive set of simulations of the proposed game model, we assess different factors that can impact the capability of an adversary to launch MIA in such repeated interaction settings.
OverHear: Headphone based Multi-sensor Keystroke Inference
Nov 04, 2023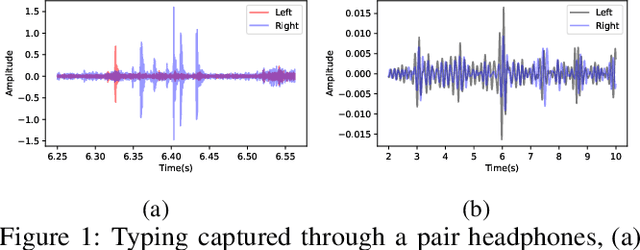
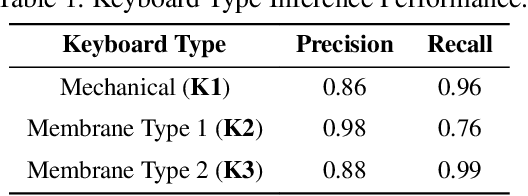
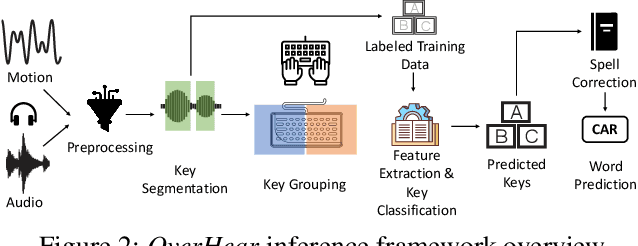
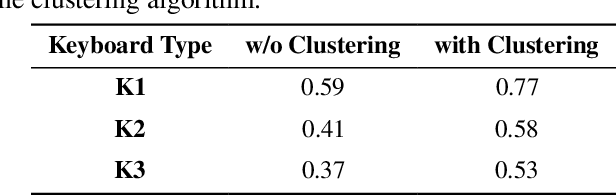
Headphones, traditionally limited to audio playback, have evolved to integrate sensors like high-definition microphones and accelerometers. While these advancements enhance user experience, they also introduce potential eavesdropping vulnerabilities, with keystroke inference being our concern in this work. To validate this threat, we developed OverHear, a keystroke inference framework that leverages both acoustic and accelerometer data from headphones. The accelerometer data, while not sufficiently detailed for individual keystroke identification, aids in clustering key presses by hand position. Concurrently, the acoustic data undergoes analysis to extract Mel Frequency Cepstral Coefficients (MFCC), aiding in distinguishing between different keystrokes. These features feed into machine learning models for keystroke prediction, with results further refined via dictionary-based word prediction methods. In our experimental setup, we tested various keyboard types under different environmental conditions. We were able to achieve top-5 key prediction accuracy of around 80% for mechanical keyboards and around 60% for membrane keyboards with top-100 word prediction accuracies over 70% for all keyboard types. The results highlight the effectiveness and limitations of our approach in the context of real-world scenarios.
A Game-theoretic Understanding of Repeated Explanations in ML Models
Feb 05, 2022
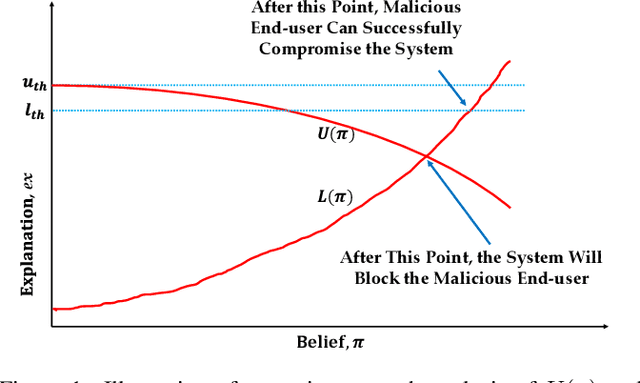
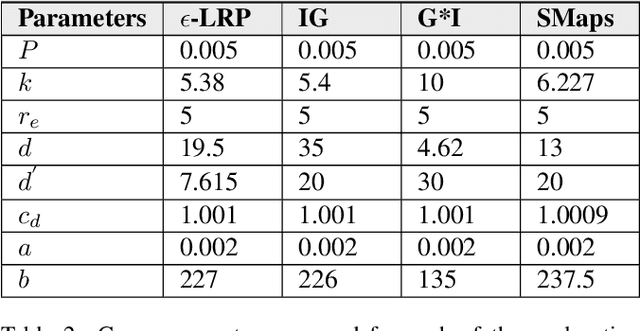
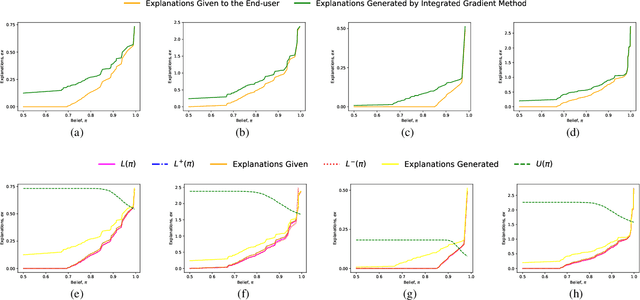
This paper formally models the strategic repeated interactions between a system, comprising of a machine learning (ML) model and associated explanation method, and an end-user who is seeking a prediction/label and its explanation for a query/input, by means of game theory. In this game, a malicious end-user must strategically decide when to stop querying and attempt to compromise the system, while the system must strategically decide how much information (in the form of noisy explanations) it should share with the end-user and when to stop sharing, all without knowing the type (honest/malicious) of the end-user. This paper formally models this trade-off using a continuous-time stochastic Signaling game framework and characterizes the Markov perfect equilibrium state within such a framework.
Zoom on the Keystrokes: Exploiting Video Calls for Keystroke Inference Attacks
Oct 22, 2020Due to recent world events, video calls have become the new norm for both personal and professional remote communication. However, if a participant in a video call is not careful, he/she can reveal his/her private information to others in the call. In this paper, we design and evaluate an attack framework to infer one type of such private information from the video stream of a call -- keystrokes, i.e., text typed during the call. We evaluate our video-based keystroke inference framework using different experimental settings and parameters, including different webcams, video resolutions, keyboards, clothing, and backgrounds. Our relatively high keystroke inference accuracies under commonly occurring and realistic settings highlight the need for awareness and countermeasures against such attacks. Consequently, we also propose and evaluate effective mitigation techniques that can automatically protect users when they type during a video call.