 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrompt and Circumstances: Evaluating the Efficacy of Human Prompt Inference in AI-Generated Art
Jan 24, 2026The emerging field of AI-generated art has witnessed the rise of prompt marketplaces, where creators can purchase, sell, or share prompts to generate unique artworks. These marketplaces often assert ownership over prompts, claiming them as intellectual property. This paper investigates whether concealed prompts sold on prompt marketplaces can be considered bona fide intellectual property, given that humans and AI tools may be able to infer the prompts based on publicly advertised sample images accompanying each prompt on sale. Specifically, our study aims to assess (i) how accurately humans can infer the original prompt solely by examining an AI-generated image, with the goal of generating images similar to the original image, and (ii) the possibility of improving upon individual human and AI prompt inferences by crafting combined human and AI prompts with the help of a large language model. Although previous research has explored AI-driven prompt inference and protection strategies, our work is the first to incorporate a human subject study and examine collaborative human-AI prompt inference in depth. Our findings indicate that while prompts inferred by humans and prompts inferred through a combined human and AI effort can generate images with a moderate level of similarity, they are not as successful as using the original prompt. Moreover, combining human- and AI-inferred prompts using our suggested merging techniques did not improve performance over purely human-inferred prompts.
Promptly Yours? A Human Subject Study on Prompt Inference in AI-Generated Art
Oct 10, 2024
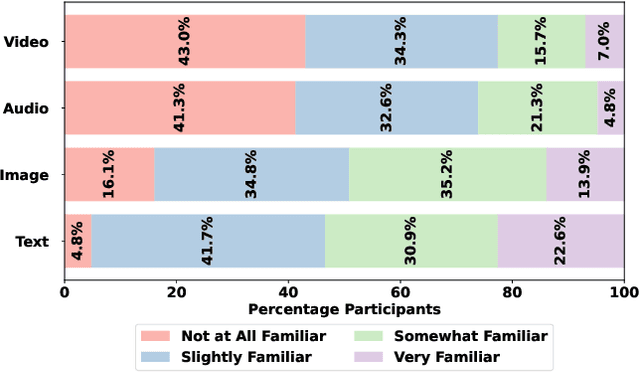
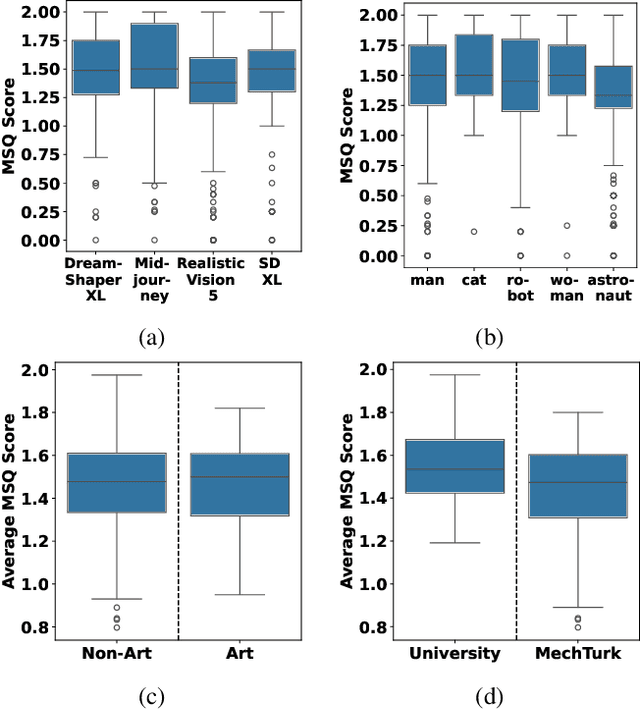

The emerging field of AI-generated art has witnessed the rise of prompt marketplaces, where creators can purchase, sell, or share prompts for generating unique artworks. These marketplaces often assert ownership over prompts, claiming them as intellectual property. This paper investigates whether concealed prompts sold on prompt marketplaces can be considered as secure intellectual property, given that humans and AI tools may be able to approximately infer the prompts based on publicly advertised sample images accompanying each prompt on sale. Specifically, our survey aims to assess (i) how accurately can humans infer the original prompt solely by examining an AI-generated image, with the goal of generating images similar to the original image, and (ii) the possibility of improving upon individual human and AI prompt inferences by crafting human-AI combined prompts with the help of a large language model. Although previous research has explored the use of AI and machine learning to infer (and also protect against) prompt inference, we are the first to include humans in the loop. Our findings indicate that while humans and human-AI collaborations can infer prompts and generate similar images with high accuracy, they are not as successful as using the original prompt.
We Have a Package for You! A Comprehensive Analysis of Package Hallucinations by Code Generating LLMs
Jun 12, 2024
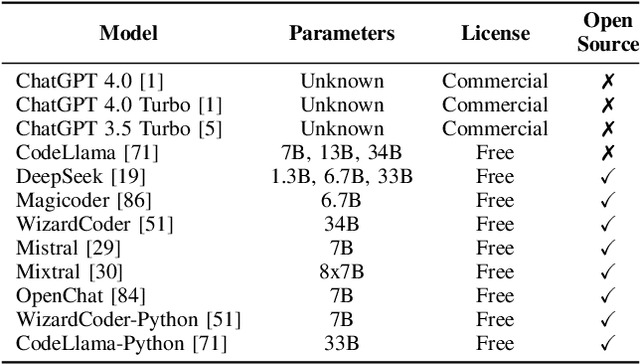


The reliance of popular programming languages such as Python and JavaScript on centralized package repositories and open-source software, combined with the emergence of code-generating Large Language Models (LLMs), has created a new type of threat to the software supply chain: package hallucinations. These hallucinations, which arise from fact-conflicting errors when generating code using LLMs, represent a novel form of package confusion attack that poses a critical threat to the integrity of the software supply chain. This paper conducts a rigorous and comprehensive evaluation of package hallucinations across different programming languages, settings, and parameters, exploring how different configurations of LLMs affect the likelihood of generating erroneous package recommendations and identifying the root causes of this phenomena. Using 16 different popular code generation models, across two programming languages and two unique prompt datasets, we collect 576,000 code samples which we analyze for package hallucinations. Our findings reveal that 19.7% of generated packages across all the tested LLMs are hallucinated, including a staggering 205,474 unique examples of hallucinated package names, further underscoring the severity and pervasiveness of this threat. We also implemented and evaluated mitigation strategies based on Retrieval Augmented Generation (RAG), self-detected feedback, and supervised fine-tuning. These techniques demonstrably reduced package hallucinations, with hallucination rates for one model dropping below 3%. While the mitigation efforts were effective in reducing hallucination rates, our study reveals that package hallucinations are a systemic and persistent phenomenon that pose a significant challenge for code generating LLMs.