 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThermalTap: Passive Application Fingerprinting in VR Headsets via Thermal Side Channels
May 13, 2026Standalone virtual reality (VR) headsets process highly sensitive personal, professional, and health-related data, yet their susceptibility to non-contact physical side channels remains largely unexplored. Existing side-channel attacks typically require malicious software execution or physical access to peripherals, making them conspicuous and potentially patchable. This paper introduces ThermalTap, the first passive, non-contact side-channel attack that fingerprints VR applications solely from the long-wave infrared (LWIR) radiation emitted by the headset chassis. By treating a headset's thermal signature as a high-fidelity proxy for internal computational workloads, ThermalTap enables remote application inference at meter-scale distances without any device interaction. To achieve robust performance in real-world settings, the system combines a commodity thermal camera with a multi-modal sensor suite (capturing ambient temperature, humidity, and airflow) to normalize environmental noise. We evaluate ThermalTap using six applications across three commercial standalone headsets. In indoor settings, ThermalTap identifies applications with over 90% accuracy using only 10 seconds of thermal camera data. Under outdoor conditions, with longer session-level observations, several applications remain identifiable despite environmental variability, with the strongest outdoor application reaching 81% accuracy. Our findings establish thermal radiation as a fundamental and unavoidable privacy risk for immersive systems, exposing a critical security gap that bypasses current software-level protections and physical access controls.
Prompt and Circumstances: Evaluating the Efficacy of Human Prompt Inference in AI-Generated Art
Jan 24, 2026The emerging field of AI-generated art has witnessed the rise of prompt marketplaces, where creators can purchase, sell, or share prompts to generate unique artworks. These marketplaces often assert ownership over prompts, claiming them as intellectual property. This paper investigates whether concealed prompts sold on prompt marketplaces can be considered bona fide intellectual property, given that humans and AI tools may be able to infer the prompts based on publicly advertised sample images accompanying each prompt on sale. Specifically, our study aims to assess (i) how accurately humans can infer the original prompt solely by examining an AI-generated image, with the goal of generating images similar to the original image, and (ii) the possibility of improving upon individual human and AI prompt inferences by crafting combined human and AI prompts with the help of a large language model. Although previous research has explored AI-driven prompt inference and protection strategies, our work is the first to incorporate a human subject study and examine collaborative human-AI prompt inference in depth. Our findings indicate that while prompts inferred by humans and prompts inferred through a combined human and AI effort can generate images with a moderate level of similarity, they are not as successful as using the original prompt. Moreover, combining human- and AI-inferred prompts using our suggested merging techniques did not improve performance over purely human-inferred prompts.
A Picture is Worth a Thousand Prompts? Efficacy of Iterative Human-Driven Prompt Refinement in Image Regeneration Tasks
Apr 29, 2025
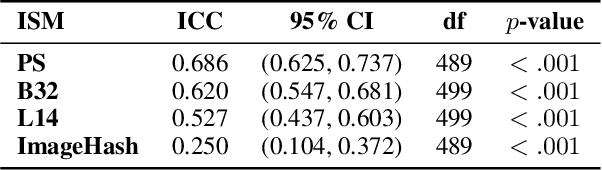
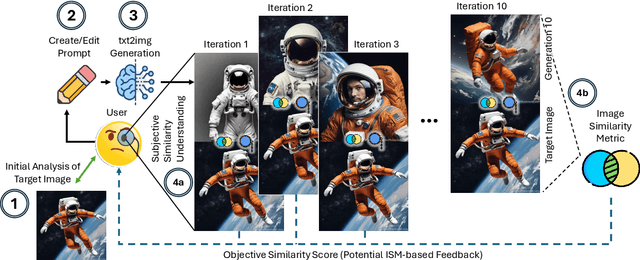

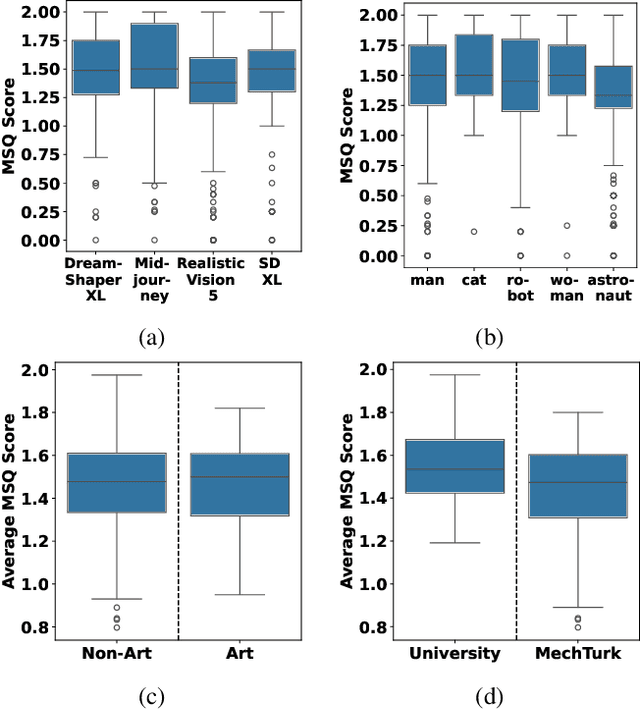
With AI-generated content becoming ubiquitous across the web, social media, and other digital platforms, it is vital to examine how such content are inspired and generated. The creation of AI-generated images often involves refining the input prompt iteratively to achieve desired visual outcomes. This study focuses on the relatively underexplored concept of image regeneration using AI, in which a human operator attempts to closely recreate a specific target image by iteratively refining their prompt. Image regeneration is distinct from normal image generation, which lacks any predefined visual reference. A separate challenge lies in determining whether existing image similarity metrics (ISMs) can provide reliable, objective feedback in iterative workflows, given that we do not fully understand if subjective human judgments of similarity align with these metrics. Consequently, we must first validate their alignment with human perception before assessing their potential as a feedback mechanism in the iterative prompt refinement process. To address these research gaps, we present a structured user study evaluating how iterative prompt refinement affects the similarity of regenerated images relative to their targets, while also examining whether ISMs capture the same improvements perceived by human observers. Our findings suggest that incremental prompt adjustments substantially improve alignment, verified through both subjective evaluations and quantitative measures, underscoring the broader potential of iterative workflows to enhance generative AI content creation across various application domains.
Promptly Yours? A Human Subject Study on Prompt Inference in AI-Generated Art
Oct 10, 2024

The emerging field of AI-generated art has witnessed the rise of prompt marketplaces, where creators can purchase, sell, or share prompts for generating unique artworks. These marketplaces often assert ownership over prompts, claiming them as intellectual property. This paper investigates whether concealed prompts sold on prompt marketplaces can be considered as secure intellectual property, given that humans and AI tools may be able to approximately infer the prompts based on publicly advertised sample images accompanying each prompt on sale. Specifically, our survey aims to assess (i) how accurately can humans infer the original prompt solely by examining an AI-generated image, with the goal of generating images similar to the original image, and (ii) the possibility of improving upon individual human and AI prompt inferences by crafting human-AI combined prompts with the help of a large language model. Although previous research has explored the use of AI and machine learning to infer (and also protect against) prompt inference, we are the first to include humans in the loop. Our findings indicate that while humans and human-AI collaborations can infer prompts and generate similar images with high accuracy, they are not as successful as using the original prompt.
We Have a Package for You! A Comprehensive Analysis of Package Hallucinations by Code Generating LLMs
Jun 12, 2024
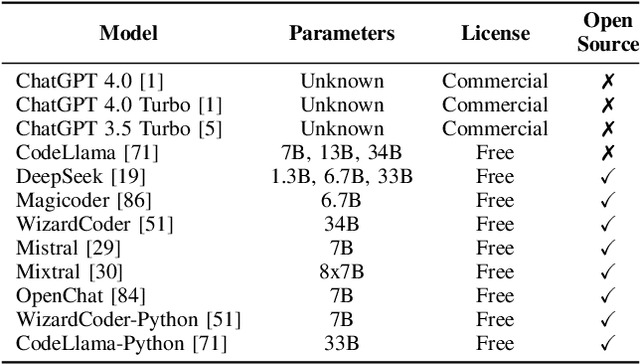


The reliance of popular programming languages such as Python and JavaScript on centralized package repositories and open-source software, combined with the emergence of code-generating Large Language Models (LLMs), has created a new type of threat to the software supply chain: package hallucinations. These hallucinations, which arise from fact-conflicting errors when generating code using LLMs, represent a novel form of package confusion attack that poses a critical threat to the integrity of the software supply chain. This paper conducts a rigorous and comprehensive evaluation of package hallucinations across different programming languages, settings, and parameters, exploring how different configurations of LLMs affect the likelihood of generating erroneous package recommendations and identifying the root causes of this phenomena. Using 16 different popular code generation models, across two programming languages and two unique prompt datasets, we collect 576,000 code samples which we analyze for package hallucinations. Our findings reveal that 19.7% of generated packages across all the tested LLMs are hallucinated, including a staggering 205,474 unique examples of hallucinated package names, further underscoring the severity and pervasiveness of this threat. We also implemented and evaluated mitigation strategies based on Retrieval Augmented Generation (RAG), self-detected feedback, and supervised fine-tuning. These techniques demonstrably reduced package hallucinations, with hallucination rates for one model dropping below 3%. While the mitigation efforts were effective in reducing hallucination rates, our study reveals that package hallucinations are a systemic and persistent phenomenon that pose a significant challenge for code generating LLMs.
OverHear: Headphone based Multi-sensor Keystroke Inference
Nov 04, 2023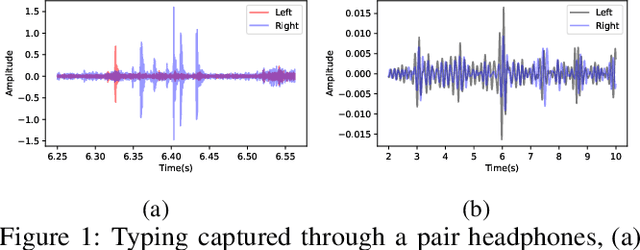
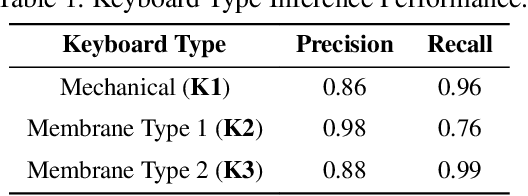
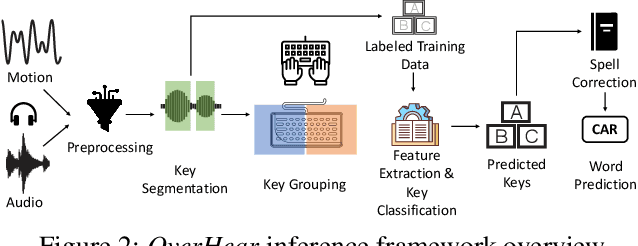
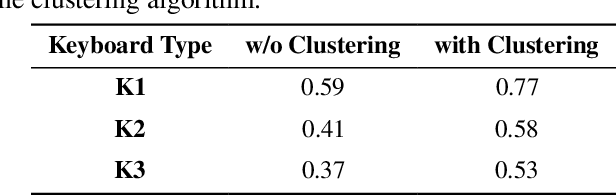
Headphones, traditionally limited to audio playback, have evolved to integrate sensors like high-definition microphones and accelerometers. While these advancements enhance user experience, they also introduce potential eavesdropping vulnerabilities, with keystroke inference being our concern in this work. To validate this threat, we developed OverHear, a keystroke inference framework that leverages both acoustic and accelerometer data from headphones. The accelerometer data, while not sufficiently detailed for individual keystroke identification, aids in clustering key presses by hand position. Concurrently, the acoustic data undergoes analysis to extract Mel Frequency Cepstral Coefficients (MFCC), aiding in distinguishing between different keystrokes. These features feed into machine learning models for keystroke prediction, with results further refined via dictionary-based word prediction methods. In our experimental setup, we tested various keyboard types under different environmental conditions. We were able to achieve top-5 key prediction accuracy of around 80% for mechanical keyboards and around 60% for membrane keyboards with top-100 word prediction accuracies over 70% for all keyboard types. The results highlight the effectiveness and limitations of our approach in the context of real-world scenarios.