 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVocalBridge: Latent Diffusion-Bridge Purification for Defeating Perturbation-Based Voiceprint Defenses
Jan 05, 2026The rapid advancement of speech synthesis technologies, including text-to-speech (TTS) and voice conversion (VC), has intensified security and privacy concerns related to voice cloning. Recent defenses attempt to prevent unauthorized cloning by embedding protective perturbations into speech to obscure speaker identity while maintaining intelligibility. However, adversaries can apply advanced purification techniques to remove these perturbations, recover authentic acoustic characteristics, and regenerate cloneable voices. Despite the growing realism of such attacks, the robustness of existing defenses under adaptive purification remains insufficiently studied. Most existing purification methods are designed to counter adversarial noise in automatic speech recognition (ASR) systems rather than speaker verification or voice cloning pipelines. As a result, they fail to suppress the fine-grained acoustic cues that define speaker identity and are often ineffective against speaker verification attacks (SVA). To address these limitations, we propose Diffusion-Bridge (VocalBridge), a purification framework that learns a latent mapping from perturbed to clean speech in the EnCodec latent space. Using a time-conditioned 1D U-Net with a cosine noise schedule, the model enables efficient, transcript-free purification while preserving speaker-discriminative structure. We further introduce a Whisper-guided phoneme variant that incorporates lightweight temporal guidance without requiring ground-truth transcripts. Experimental results show that our approach consistently outperforms existing purification methods in recovering cloneable voices from protected speech. Our findings demonstrate the fragility of current perturbation-based defenses and highlight the need for more robust protection mechanisms against evolving voice-cloning and speaker verification threats.
Spiking Neural Networks in Vertical Federated Learning: Performance Trade-offs
Jul 24, 2024Federated machine learning enables model training across multiple clients while maintaining data privacy. Vertical Federated Learning (VFL) specifically deals with instances where the clients have different feature sets of the same samples. As federated learning models aim to improve efficiency and adaptability, innovative neural network architectures like Spiking Neural Networks (SNNs) are being leveraged to enable fast and accurate processing at the edge. SNNs, known for their efficiency over Artificial Neural Networks (ANNs), have not been analyzed for their applicability in VFL, thus far. In this paper, we investigate the benefits and trade-offs of using SNN models in a vertical federated learning setting. We implement two different federated learning architectures -- with model splitting and without model splitting -- that have different privacy and performance implications. We evaluate the setup using CIFAR-10 and CIFAR-100 benchmark datasets along with SNN implementations of VGG9 and ResNET classification models. Comparative evaluations demonstrate that the accuracy of SNN models is comparable to that of traditional ANNs for VFL applications, albeit significantly more energy efficient.
OverHear: Headphone based Multi-sensor Keystroke Inference
Nov 04, 2023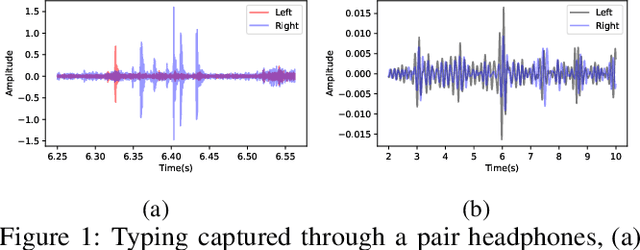
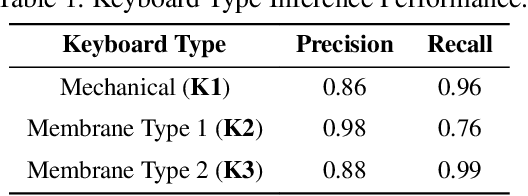
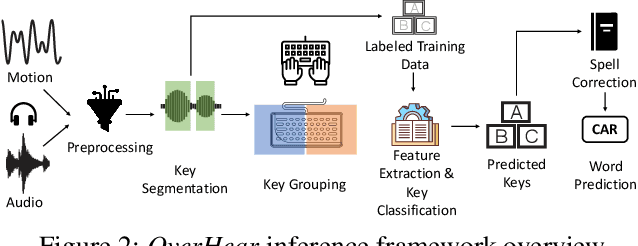
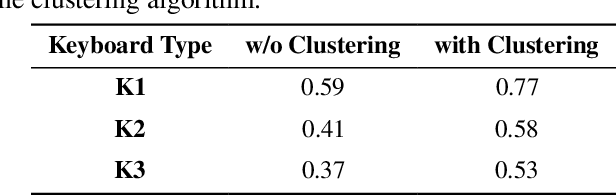
Headphones, traditionally limited to audio playback, have evolved to integrate sensors like high-definition microphones and accelerometers. While these advancements enhance user experience, they also introduce potential eavesdropping vulnerabilities, with keystroke inference being our concern in this work. To validate this threat, we developed OverHear, a keystroke inference framework that leverages both acoustic and accelerometer data from headphones. The accelerometer data, while not sufficiently detailed for individual keystroke identification, aids in clustering key presses by hand position. Concurrently, the acoustic data undergoes analysis to extract Mel Frequency Cepstral Coefficients (MFCC), aiding in distinguishing between different keystrokes. These features feed into machine learning models for keystroke prediction, with results further refined via dictionary-based word prediction methods. In our experimental setup, we tested various keyboard types under different environmental conditions. We were able to achieve top-5 key prediction accuracy of around 80% for mechanical keyboards and around 60% for membrane keyboards with top-100 word prediction accuracies over 70% for all keyboard types. The results highlight the effectiveness and limitations of our approach in the context of real-world scenarios.