 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRadGame: An AI-Powered Platform for Radiology Education
Sep 16, 2025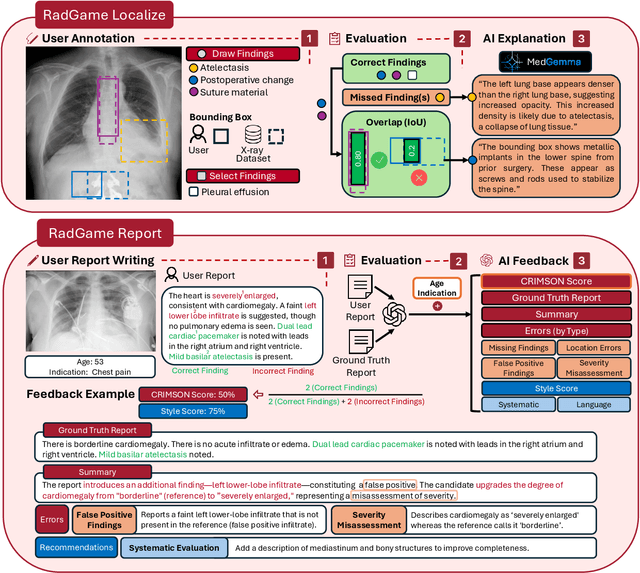
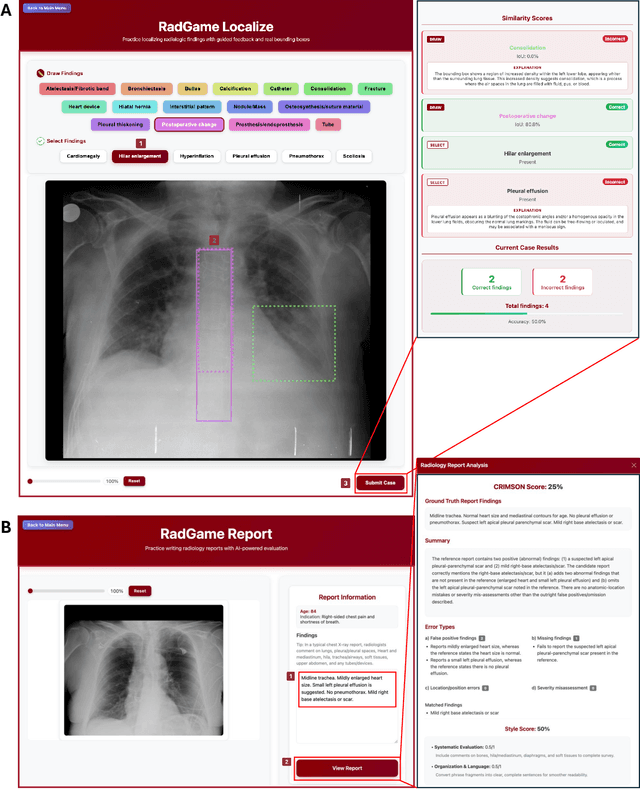
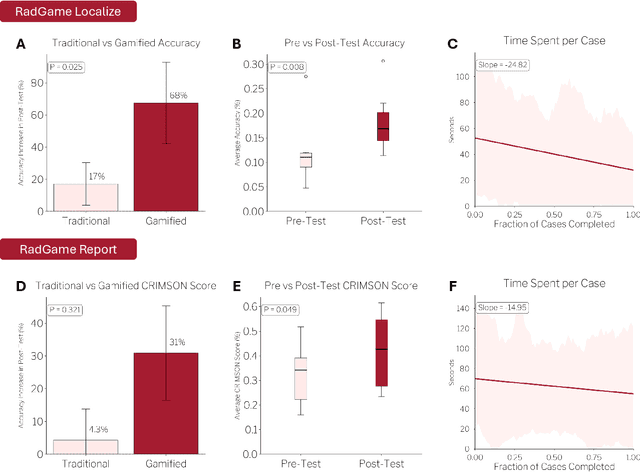

We introduce RadGame, an AI-powered gamified platform for radiology education that targets two core skills: localizing findings and generating reports. Traditional radiology training is based on passive exposure to cases or active practice with real-time input from supervising radiologists, limiting opportunities for immediate and scalable feedback. RadGame addresses this gap by combining gamification with large-scale public datasets and automated, AI-driven feedback that provides clear, structured guidance to human learners. In RadGame Localize, players draw bounding boxes around abnormalities, which are automatically compared to radiologist-drawn annotations from public datasets, and visual explanations are generated by vision-language models for user missed findings. In RadGame Report, players compose findings given a chest X-ray, patient age and indication, and receive structured AI feedback based on radiology report generation metrics, highlighting errors and omissions compared to a radiologist's written ground truth report from public datasets, producing a final performance and style score. In a prospective evaluation, participants using RadGame achieved a 68% improvement in localization accuracy compared to 17% with traditional passive methods and a 31% improvement in report-writing accuracy compared to 4% with traditional methods after seeing the same cases. RadGame highlights the potential of AI-driven gamification to deliver scalable, feedback-rich radiology training and reimagines the application of medical AI resources in education.
Multi-Modal Foundation Models for Computational Pathology: A Survey
Mar 12, 2025



Foundation models have emerged as a powerful paradigm in computational pathology (CPath), enabling scalable and generalizable analysis of histopathological images. While early developments centered on uni-modal models trained solely on visual data, recent advances have highlighted the promise of multi-modal foundation models that integrate heterogeneous data sources such as textual reports, structured domain knowledge, and molecular profiles. In this survey, we provide a comprehensive and up-to-date review of multi-modal foundation models in CPath, with a particular focus on models built upon hematoxylin and eosin (H&E) stained whole slide images (WSIs) and tile-level representations. We categorize 32 state-of-the-art multi-modal foundation models into three major paradigms: vision-language, vision-knowledge graph, and vision-gene expression. We further divide vision-language models into non-LLM-based and LLM-based approaches. Additionally, we analyze 28 available multi-modal datasets tailored for pathology, grouped into image-text pairs, instruction datasets, and image-other modality pairs. Our survey also presents a taxonomy of downstream tasks, highlights training and evaluation strategies, and identifies key challenges and future directions. We aim for this survey to serve as a valuable resource for researchers and practitioners working at the intersection of pathology and AI.
A Survey on Computational Pathology Foundation Models: Datasets, Adaptation Strategies, and Evaluation Tasks
Jan 27, 2025Computational pathology foundation models (CPathFMs) have emerged as a powerful approach for analyzing histopathological data, leveraging self-supervised learning to extract robust feature representations from unlabeled whole-slide images. These models, categorized into uni-modal and multi-modal frameworks, have demonstrated promise in automating complex pathology tasks such as segmentation, classification, and biomarker discovery. However, the development of CPathFMs presents significant challenges, such as limited data accessibility, high variability across datasets, the necessity for domain-specific adaptation, and the lack of standardized evaluation benchmarks. This survey provides a comprehensive review of CPathFMs in computational pathology, focusing on datasets, adaptation strategies, and evaluation tasks. We analyze key techniques, such as contrastive learning and multi-modal integration, and highlight existing gaps in current research. Finally, we explore future directions from four perspectives for advancing CPathFMs. This survey serves as a valuable resource for researchers, clinicians, and AI practitioners, guiding the advancement of CPathFMs toward robust and clinically applicable AI-driven pathology solutions.
Representing visual classification as a linear combination of words
Nov 18, 2023



Explainability is a longstanding challenge in deep learning, especially in high-stakes domains like healthcare. Common explainability methods highlight image regions that drive an AI model's decision. Humans, however, heavily rely on language to convey explanations of not only "where" but "what". Additionally, most explainability approaches focus on explaining individual AI predictions, rather than describing the features used by an AI model in general. The latter would be especially useful for model and dataset auditing, and potentially even knowledge generation as AI is increasingly being used in novel tasks. Here, we present an explainability strategy that uses a vision-language model to identify language-based descriptors of a visual classification task. By leveraging a pre-trained joint embedding space between images and text, our approach estimates a new classification task as a linear combination of words, resulting in a weight for each word that indicates its alignment with the vision-based classifier. We assess our approach using two medical imaging classification tasks, where we find that the resulting descriptors largely align with clinical knowledge despite a lack of domain-specific language training. However, our approach also identifies the potential for 'shortcut connections' in the public datasets used. Towards a functional measure of explainability, we perform a pilot reader study where we find that the AI-identified words can enable non-expert humans to perform a specialized medical task at a non-trivial level. Altogether, our results emphasize the potential of using multimodal foundational models to deliver intuitive, language-based explanations of visual tasks.