 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Modal Foundation Models for Computational Pathology: A Survey
Mar 12, 2025



Foundation models have emerged as a powerful paradigm in computational pathology (CPath), enabling scalable and generalizable analysis of histopathological images. While early developments centered on uni-modal models trained solely on visual data, recent advances have highlighted the promise of multi-modal foundation models that integrate heterogeneous data sources such as textual reports, structured domain knowledge, and molecular profiles. In this survey, we provide a comprehensive and up-to-date review of multi-modal foundation models in CPath, with a particular focus on models built upon hematoxylin and eosin (H&E) stained whole slide images (WSIs) and tile-level representations. We categorize 32 state-of-the-art multi-modal foundation models into three major paradigms: vision-language, vision-knowledge graph, and vision-gene expression. We further divide vision-language models into non-LLM-based and LLM-based approaches. Additionally, we analyze 28 available multi-modal datasets tailored for pathology, grouped into image-text pairs, instruction datasets, and image-other modality pairs. Our survey also presents a taxonomy of downstream tasks, highlights training and evaluation strategies, and identifies key challenges and future directions. We aim for this survey to serve as a valuable resource for researchers and practitioners working at the intersection of pathology and AI.
A Survey on Computational Pathology Foundation Models: Datasets, Adaptation Strategies, and Evaluation Tasks
Jan 27, 2025Computational pathology foundation models (CPathFMs) have emerged as a powerful approach for analyzing histopathological data, leveraging self-supervised learning to extract robust feature representations from unlabeled whole-slide images. These models, categorized into uni-modal and multi-modal frameworks, have demonstrated promise in automating complex pathology tasks such as segmentation, classification, and biomarker discovery. However, the development of CPathFMs presents significant challenges, such as limited data accessibility, high variability across datasets, the necessity for domain-specific adaptation, and the lack of standardized evaluation benchmarks. This survey provides a comprehensive review of CPathFMs in computational pathology, focusing on datasets, adaptation strategies, and evaluation tasks. We analyze key techniques, such as contrastive learning and multi-modal integration, and highlight existing gaps in current research. Finally, we explore future directions from four perspectives for advancing CPathFMs. This survey serves as a valuable resource for researchers, clinicians, and AI practitioners, guiding the advancement of CPathFMs toward robust and clinically applicable AI-driven pathology solutions.
A Bias Trick for Centered Robust Principal Component Analysis
Nov 19, 2019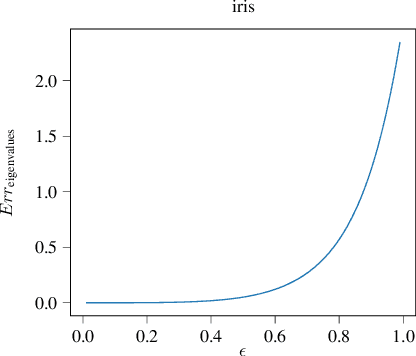

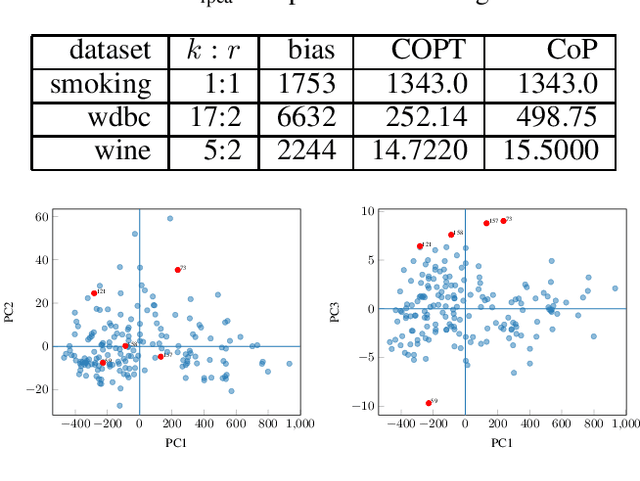
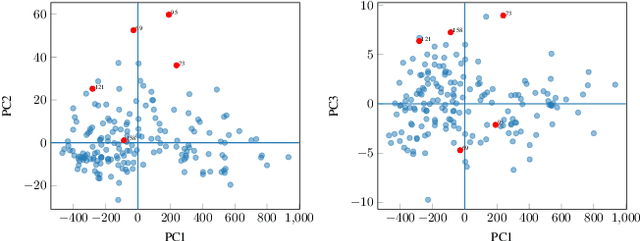
Outlier based Robust Principal Component Analysis (RPCA) requires centering of the non-outliers. We show a "bias trick" that automatically centers these non-outliers. Using this bias trick we obtain the first RPCA algorithm that is optimal with respect to centering.
Improving the Accuracy of Principal Component Analysis by the Maximum Entropy Method
Jul 24, 2019



Classical Principal Component Analysis (PCA) approximates data in terms of projections on a small number of orthogonal vectors. There are simple procedures to efficiently compute various functions of the data from the PCA approximation. The most important function is arguably the Euclidean distance between data items, This can be used, for example, to solve the approximate nearest neighbor problem. We use random variables to model the inherent uncertainty in such approximations, and apply the Maximum Entropy Method to infer the underlying probability distribution. We propose using the expected values of distances between these random variables as improved estimates of the distance. We show by analysis and experimentally that in most cases results obtained by our method are more accurate than what is obtained by the classical approach. This improves the accuracy of a classical technique that have been used with little change for over 100 years.