 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMedFact-R1: Towards Factual Medical Reasoning via Pseudo-Label Augmentation
Sep 18, 2025



Ensuring factual consistency and reliable reasoning remains a critical challenge for medical vision-language models. We introduce MEDFACT-R1, a two-stage framework that integrates external knowledge grounding with reinforcement learning to improve the factual medical reasoning. The first stage uses pseudo-label supervised fine-tuning (SFT) to incorporate external factual expertise; while the second stage applies Group Relative Policy Optimization (GRPO) with four tailored factual reward signals to encourage self-consistent reasoning. Across three public medical QA benchmarks, MEDFACT-R1 delivers up to 22.5% absolute improvement in factual accuracy over previous state-of-the-art methods. Ablation studies highlight the necessity of pseudo-label SFT cold start and validate the contribution of each GRPO reward, underscoring the synergy between knowledge grounding and RL-driven reasoning for trustworthy medical AI. Codes are released at https://github.com/Garfieldgengliang/MEDFACT-R1.
Condensing Action Segmentation Datasets via Generative Network Inversion
Mar 18, 2025



This work presents the first condensation approach for procedural video datasets used in temporal action segmentation. We propose a condensation framework that leverages generative prior learned from the dataset and network inversion to condense data into compact latent codes with significant storage reduced across temporal and channel aspects. Orthogonally, we propose sampling diverse and representative action sequences to minimize video-wise redundancy. Our evaluation on standard benchmarks demonstrates consistent effectiveness in condensing TAS datasets and achieving competitive performances. Specifically, on the Breakfast dataset, our approach reduces storage by over 500$\times$ while retaining 83% of the performance compared to training with the full dataset. Furthermore, when applied to a downstream incremental learning task, it yields superior performance compared to the state-of-the-art.
OnlineTAS: An Online Baseline for Temporal Action Segmentation
Nov 02, 2024
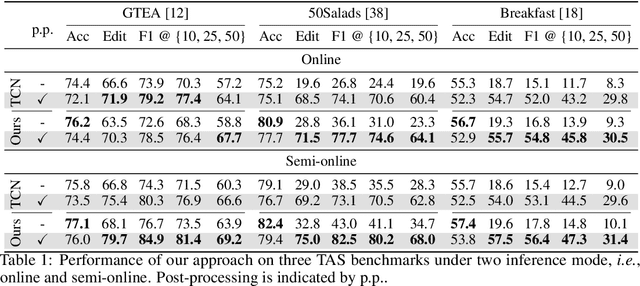
Temporal context plays a significant role in temporal action segmentation. In an offline setting, the context is typically captured by the segmentation network after observing the entire sequence. However, capturing and using such context information in an online setting remains an under-explored problem. This work presents the an online framework for temporal action segmentation. At the core of the framework is an adaptive memory designed to accommodate dynamic changes in context over time, alongside a feature augmentation module that enhances the frames with the memory. In addition, we propose a post-processing approach to mitigate the severe over-segmentation in the online setting. On three common segmentation benchmarks, our approach achieves state-of-the-art performance.
Coherent Temporal Synthesis for Incremental Action Segmentation
Mar 10, 2024Data replay is a successful incremental learning technique for images. It prevents catastrophic forgetting by keeping a reservoir of previous data, original or synthesized, to ensure the model retains past knowledge while adapting to novel concepts. However, its application in the video domain is rudimentary, as it simply stores frame exemplars for action recognition. This paper presents the first exploration of video data replay techniques for incremental action segmentation, focusing on action temporal modeling. We propose a Temporally Coherent Action (TCA) model, which represents actions using a generative model instead of storing individual frames. The integration of a conditioning variable that captures temporal coherence allows our model to understand the evolution of action features over time. Therefore, action segments generated by TCA for replay are diverse and temporally coherent. In a 10-task incremental setup on the Breakfast dataset, our approach achieves significant increases in accuracy for up to 22% compared to the baselines.
Every Mistake Counts in Assembly
Jul 31, 2023



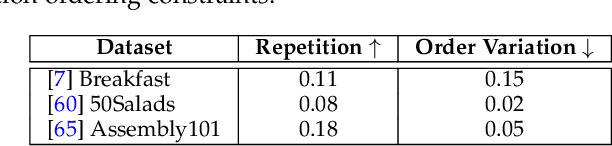
One promising use case of AI assistants is to help with complex procedures like cooking, home repair, and assembly tasks. Can we teach the assistant to interject after the user makes a mistake? This paper targets the problem of identifying ordering mistakes in assembly procedures. We propose a system that can detect ordering mistakes by utilizing a learned knowledge base. Our framework constructs a knowledge base with spatial and temporal beliefs based on observed mistakes. Spatial beliefs depict the topological relationship of the assembling components, while temporal beliefs aggregate prerequisite actions as ordering constraints. With an episodic memory design, our algorithm can dynamically update and construct the belief sets as more actions are observed, all in an online fashion. We demonstrate experimentally that our inferred spatial and temporal beliefs are capable of identifying incorrect orderings in real-world action sequences. To construct the spatial beliefs, we collect a new set of coarse-level action annotations for Assembly101 based on the positioning of the toy parts. Finally, we demonstrate the superior performance of our belief inference algorithm in detecting ordering mistakes on the Assembly101 dataset.
Temporal Action Segmentation: An Analysis of Modern Technique
Oct 19, 2022
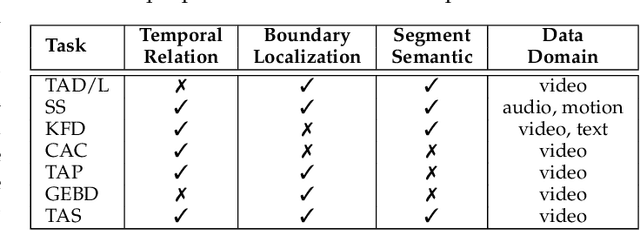

Temporal action segmentation from videos aims at the dense labeling of video frames with multiple action classes in minutes-long videos. Categorized as a long-range video understanding task, researchers have proposed an extended collection of methods and examined their performance using various benchmarks. Despite the rapid development of action segmentation techniques in recent years, there has been no systematic survey in such fields. To this end, in this survey, we analyze and summarize the main contributions and trends for this task. Specifically, we first examine the task definition, common benchmarks, types of supervision, and popular evaluation measures. Furthermore, we systematically investigate two fundamental aspects of this topic, i.e., frame representation and temporal modeling, which are widely and extensively studied in the literature. We then comprehensively review existing temporal action segmentation works, each categorized by their form of supervision. Finally, we conclude our survey by highlighting and identifying several open topics for research. In addition, we supplement our survey with a curated list of temporal action segmentation resources, which is available at https://github.com/atlas-eccv22/awesome-temporal-action-segmentation.
Leveraging Action Affinity and Continuity for Semi-supervised Temporal Action Segmentation
Jul 21, 2022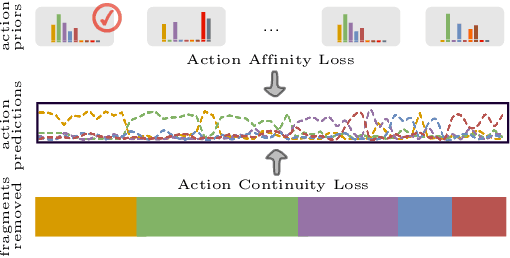
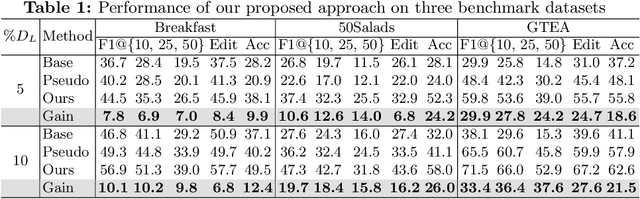
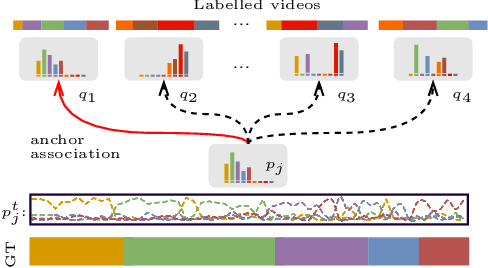

We present a semi-supervised learning approach to the temporal action segmentation task. The goal of the task is to temporally detect and segment actions in long, untrimmed procedural videos, where only a small set of videos are densely labelled, and a large collection of videos are unlabelled. To this end, we propose two novel loss functions for the unlabelled data: an action affinity loss and an action continuity loss. The action affinity loss guides the unlabelled samples learning by imposing the action priors induced from the labelled set. Action continuity loss enforces the temporal continuity of actions, which also provides frame-wise classification supervision. In addition, we propose an Adaptive Boundary Smoothing (ABS) approach to build coarser action boundaries for more robust and reliable learning. The proposed loss functions and ABS were evaluated on three benchmarks. Results show that they significantly improved action segmentation performance with a low amount (5% and 10%) of labelled data and achieved comparable results to full supervision with 50% labelled data. Furthermore, ABS succeeded in boosting performance when integrated into fully-supervised learning.
Rapid Person Re-Identification via Sub-space Consistency Regularization
Jul 13, 2022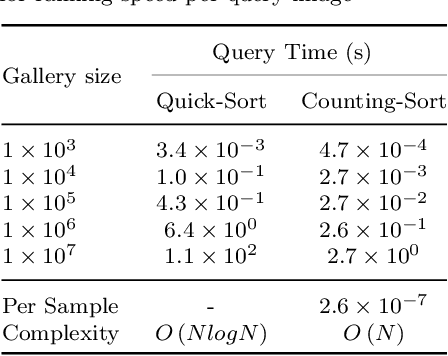
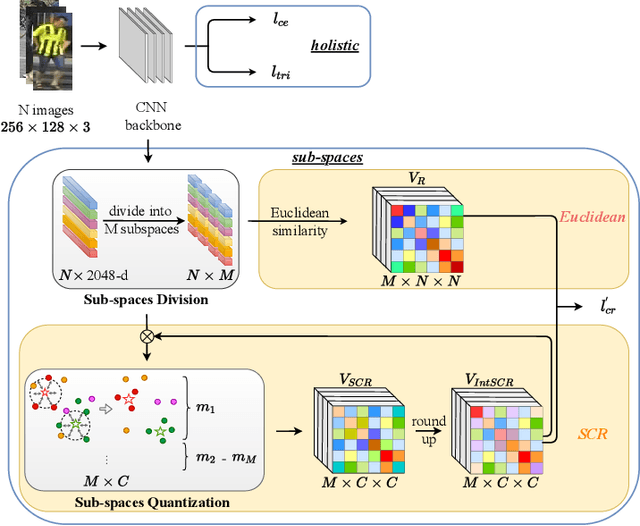
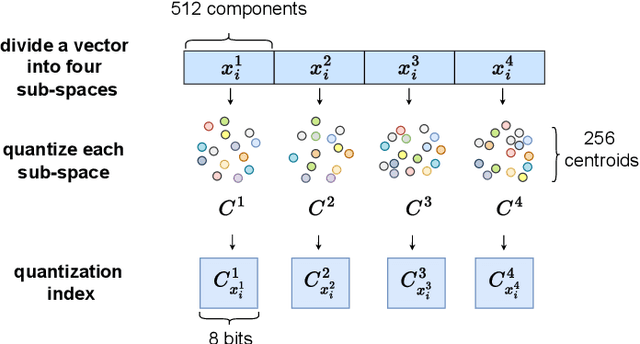
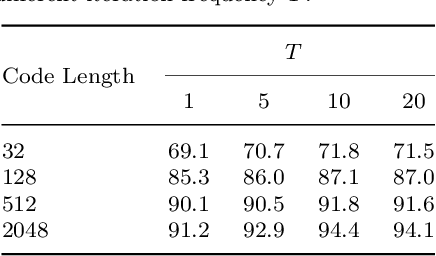
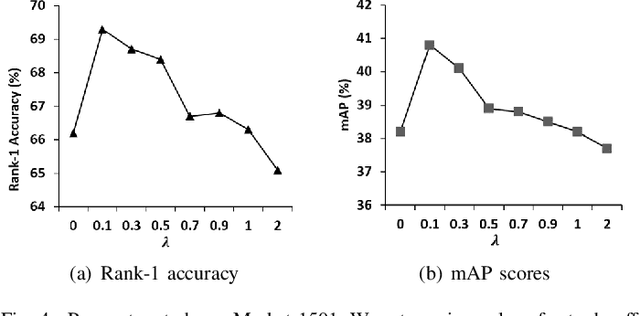
Person Re-Identification (ReID) matches pedestrians across disjoint cameras. Existing ReID methods adopting real-value feature descriptors have achieved high accuracy, but they are low in efficiency due to the slow Euclidean distance computation as well as complex quick-sort algorithms. Recently, some works propose to yield binary encoded person descriptors which instead only require fast Hamming distance computation and simple counting-sort algorithms. However, the performances of such binary encoded descriptors, especially with short code (e.g., 32 and 64 bits), are hardly satisfactory given the sparse binary space. To strike a balance between the model accuracy and efficiency, we propose a novel Sub-space Consistency Regularization (SCR) algorithm that can speed up the ReID procedure by $0.25$ times than real-value features under the same dimensions whilst maintaining a competitive accuracy, especially under short codes. SCR transforms real-value features vector (e.g., 2048 float32) with short binary codes (e.g., 64 bits) by first dividing real-value features vector into $M$ sub-spaces, each with $C$ clustered centroids. Thus the distance between two samples can be expressed as the summation of the respective distance to the centroids, which can be sped up by offline calculation and maintained via a look-up table. On the other side, these real-value centroids help to achieve significantly higher accuracy than using binary code. Lastly, we convert the distance look-up table to be integer and apply the counting-sort algorithm to speed up the ranking stage. We also propose a novel consistency regularization with an iterative framework. Experimental results on Market-1501 and DukeMTMC-reID show promising and exciting results. Under short code, our proposed SCR enjoys Real-value-level accuracy and Hashing-level speed.
Temporal Action Segmentation with High-level Complex Activity Labels
Aug 15, 2021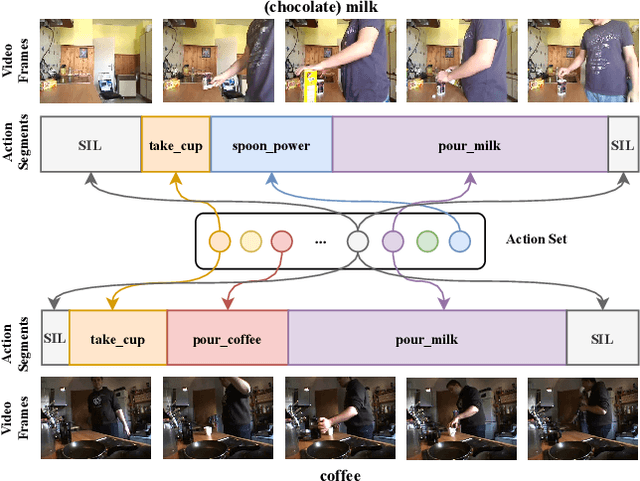
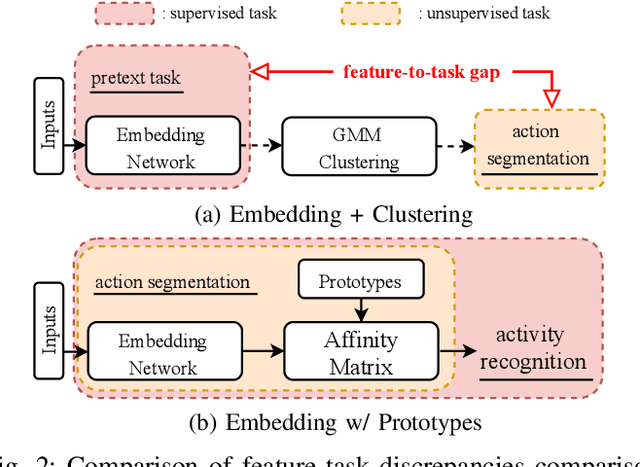
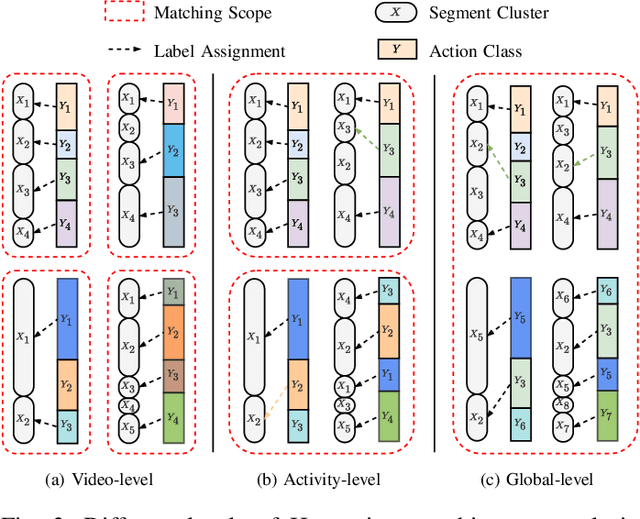
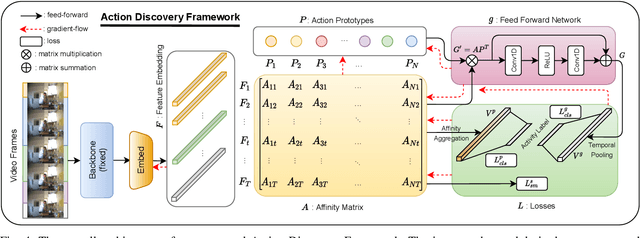
Over the past few years, the success in action recognition on short trimmed videos has led more investigations towards the temporal segmentation of actions in untrimmed long videos. Recently, supervised approaches have achieved excellent performance in segmenting complex human actions in untrimmed videos. However, besides action labels, such approaches also require the start and end points of each action, which is expensive and tedious to collect. In this paper, we aim to learn the action segments taking only the high-level activity labels as input. Under the setting where no action-level supervision is provided, Hungarian matching is often used to find the mapping between segments and ground truth actions to evaluate the model and report the performance. On the one hand, we show that with the high-level supervision, we are able to generalize the Hungarian matching settings from the current video and activity level to the global level. The extended global-level matching allows for the shared actions across activities. On the other hand, we propose a novel action discovery framework that automatically discovers constituent actions in videos with the activity classification task. Specifically, we define a finite number of prototypes to form a dual representation of a video sequence. These collectively learned prototypes are considered discovered actions. This classification setting endows our approach the capability of discovering potentially shared actions across multiple complex activities. Extensive experiments demonstrate that the discovered actions are helpful in performing temporal action segmentation and activity recognition.
Towards better Validity: Dispersion based Clustering for Unsupervised Person Re-identification
Jun 04, 2019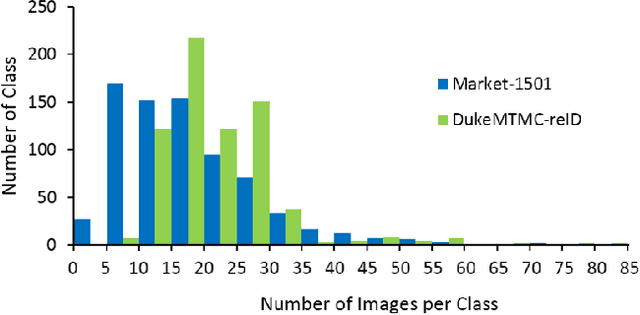
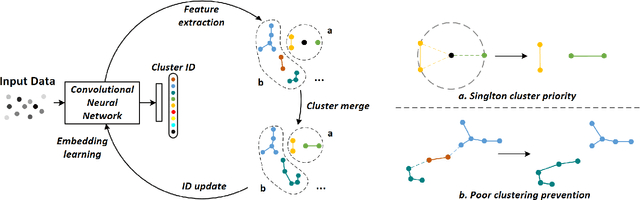

Person re-identification aims to establish the correct identity correspondences of a person moving through a non-overlapping multi-camera installation. Recent advances based on deep learning models for this task mainly focus on supervised learning scenarios where accurate annotations are assumed to be available for each setup. Annotating large scale datasets for person re-identification is demanding and burdensome, which renders the deployment of such supervised approaches to real-world applications infeasible. Therefore, it is necessary to train models without explicit supervision in an autonomous manner. In this paper, we propose an elegant and practical clustering approach for unsupervised person re-identification based on the cluster validity consideration. Concretely, we explore a fundamental concept in statistics, namely \emph{dispersion}, to achieve a robust clustering criterion. Dispersion reflects the compactness of a cluster when employed at the intra-cluster level and reveals the separation when measured at the inter-cluster level. With this insight, we design a novel Dispersion-based Clustering (DBC) approach which can discover the underlying patterns in data. This approach considers a wider context of sample-level pairwise relationships to achieve a robust cluster affinity assessment which handles the complications may arise due to prevalent imbalanced data distributions. Additionally, our solution can automatically prioritize standalone data points and prevents inferior clustering. Our extensive experimental analysis on image and video re-identification benchmarks demonstrate that our method outperforms the state-of-the-art unsupervised methods by a significant margin. Code is available at https://github.com/gddingcs/Dispersion-based-Clustering.git.