 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTemporal Action Segmentation with High-level Complex Activity Labels
Paper and Code
Aug 15, 2021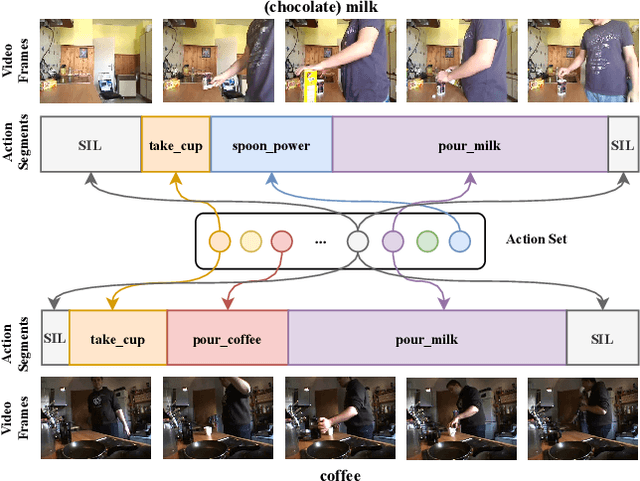
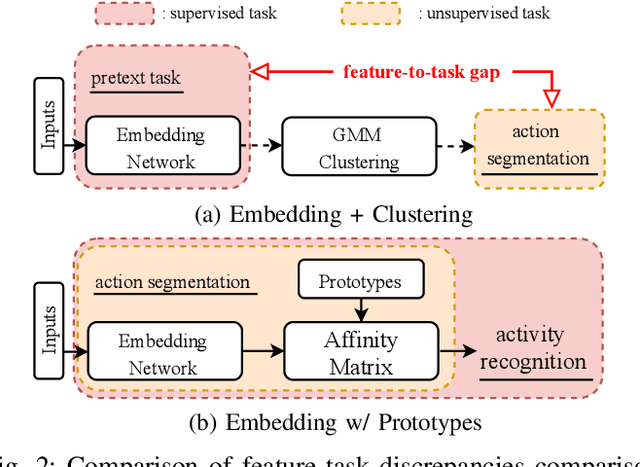
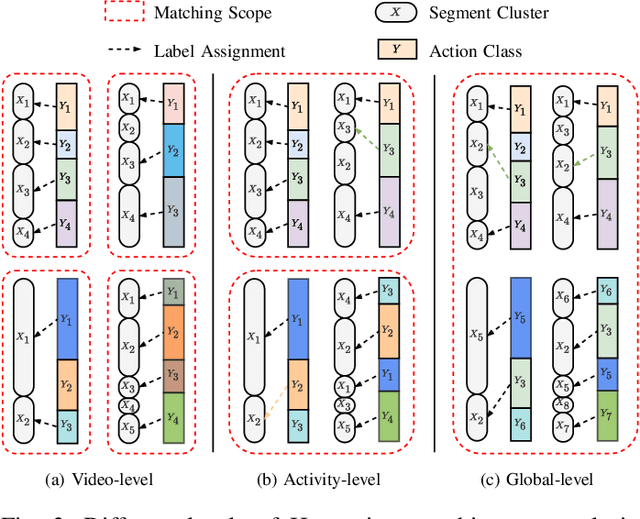
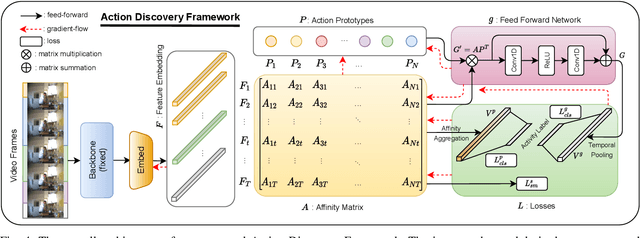
Over the past few years, the success in action recognition on short trimmed videos has led more investigations towards the temporal segmentation of actions in untrimmed long videos. Recently, supervised approaches have achieved excellent performance in segmenting complex human actions in untrimmed videos. However, besides action labels, such approaches also require the start and end points of each action, which is expensive and tedious to collect. In this paper, we aim to learn the action segments taking only the high-level activity labels as input. Under the setting where no action-level supervision is provided, Hungarian matching is often used to find the mapping between segments and ground truth actions to evaluate the model and report the performance. On the one hand, we show that with the high-level supervision, we are able to generalize the Hungarian matching settings from the current video and activity level to the global level. The extended global-level matching allows for the shared actions across activities. On the other hand, we propose a novel action discovery framework that automatically discovers constituent actions in videos with the activity classification task. Specifically, we define a finite number of prototypes to form a dual representation of a video sequence. These collectively learned prototypes are considered discovered actions. This classification setting endows our approach the capability of discovering potentially shared actions across multiple complex activities. Extensive experiments demonstrate that the discovered actions are helpful in performing temporal action segmentation and activity recognition.