 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTalk, Evaluate, Diagnose: User-aware Agent Evaluation with Automated Error Analysis
Mar 16, 2026Agent applications are increasingly adopted to automate workflows across diverse tasks. However, due to the heterogeneous domains they operate in, it is challenging to create a scalable evaluation framework. Prior works each employ their own methods to determine task success, such as database lookups, regex match, etc., adding complexity to the development of a unified agent evaluation approach. Moreover, they do not systematically account for the user's role nor expertise in the interaction, providing incomplete insights into the agent's performance. We argue that effective agent evaluation goes beyond correctness alone, incorporating conversation quality, efficiency and systematic diagnosis of agent errors. To address this, we introduce the TED framework (Talk, Evaluate, Diagnose). (1) Talk: We leverage reusable, generic expert and non-expert user persona templates for user-agent interaction. (2) Evaluate: We adapt existing datasets by representing subgoals-such as tool signatures, and responses-as natural language grading notes, evaluated automatically with LLM-as-a-judge. We propose new metrics that capture both turn efficiency and intermediate progress of the agent complementing the user-aware setup. (3) Diagnose: We introduce an automated error analysis tool that analyzes the inconsistencies of the judge and agents, uncovering common errors, and providing actionable feedback for agent improvement. We show that our TED framework reveals new insights regarding agent performance across models and user expertise levels. We also demonstrate potential gains in agent performance with peaks of 8-10% on our proposed metrics after incorporating the identified error remedies into the agent's design.
OCR or Not? Rethinking Document Information Extraction in the MLLMs Era with Real-World Large-Scale Datasets
Mar 03, 2026Multimodal Large Language Models (MLLMs) enhance the potential of natural language processing. However, their actual impact on document information extraction remains unclear. In particular, it is unclear whether an MLLM-only pipeline--while simpler--can truly match the performance of traditional OCR+MLLM setups. In this paper, we conduct a large-scale benchmarking study that evaluates various out-of-the-box MLLMs on business-document information extraction. To examine and explore failure modes, we propose an automated hierarchical error analysis framework that leverages large language models (LLMs) to diagnose error patterns systematically. Our findings suggest that OCR may not be necessary for powerful MLLMs, as image-only input can achieve comparable performance to OCR-enhanced approaches. Moreover, we demonstrate that carefully designed schema, exemplars, and instructions can further enhance MLLMs performance. We hope this work can offer practical guidance and valuable insight for advancing document information extraction.
Pretrained equivariant features improve unsupervised landmark discovery
Apr 07, 2021
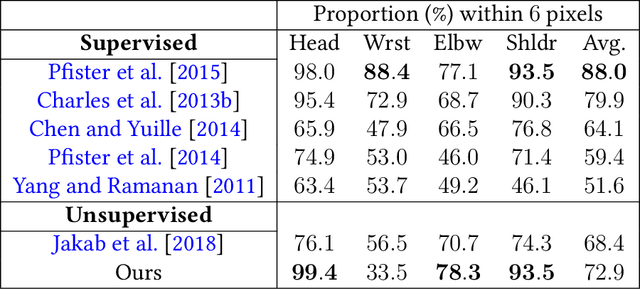
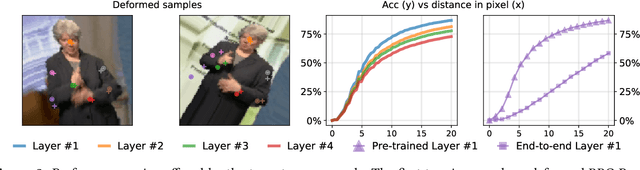

Locating semantically meaningful landmark points is a crucial component of a large number of computer vision pipelines. Because of the small number of available datasets with ground truth landmark annotations, it is important to design robust unsupervised and semi-supervised methods for landmark detection. Many of the recent unsupervised learning methods rely on the equivariance properties of landmarks to synthetic image deformations. Our work focuses on such widely used methods and sheds light on its core problem, its inability to produce equivariant intermediate convolutional features. This finding leads us to formulate a two-step unsupervised approach that overcomes this challenge by first learning powerful pixel-based features and then use the pre-trained features to learn a landmark detector by the traditional equivariance method. Our method produces state-of-the-art results in several challenging landmark detection datasets such as the BBC Pose dataset and the Cat-Head dataset. It performs comparably on a range of other benchmarks.
On Data-Augmentation and Consistency-Based Semi-Supervised Learning
Jan 18, 2021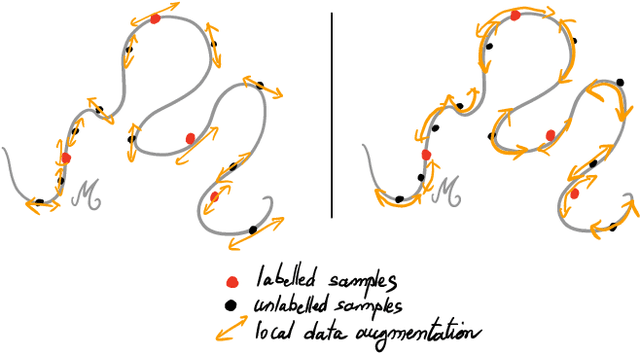
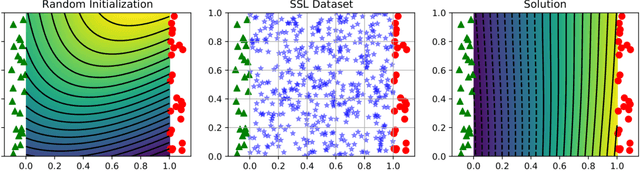
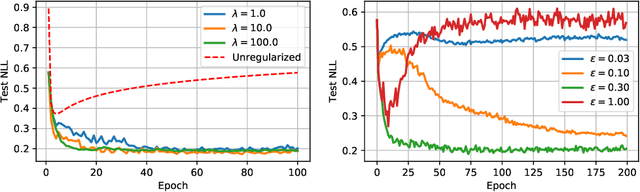
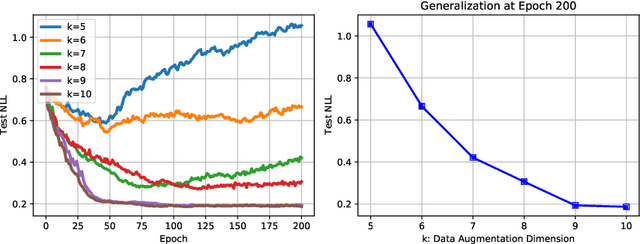
Recently proposed consistency-based Semi-Supervised Learning (SSL) methods such as the $\Pi$-model, temporal ensembling, the mean teacher, or the virtual adversarial training, have advanced the state of the art in several SSL tasks. These methods can typically reach performances that are comparable to their fully supervised counterparts while using only a fraction of labelled examples. Despite these methodological advances, the understanding of these methods is still relatively limited. In this text, we analyse (variations of) the $\Pi$-model in settings where analytically tractable results can be obtained. We establish links with Manifold Tangent Classifiers and demonstrate that the quality of the perturbations is key to obtaining reasonable SSL performances. Importantly, we propose a simple extension of the Hidden Manifold Model that naturally incorporates data-augmentation schemes and offers a framework for understanding and experimenting with SSL methods.
ARMDN: Associative and Recurrent Mixture Density Networks for eRetail Demand Forecasting
Mar 16, 2018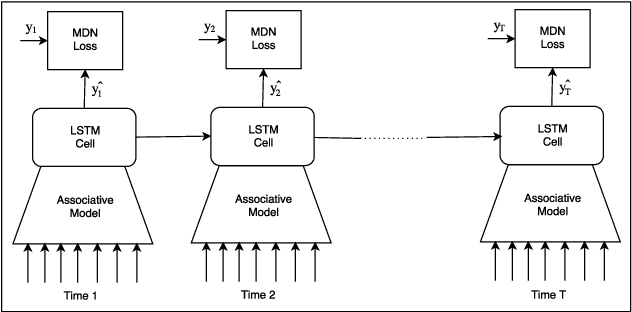
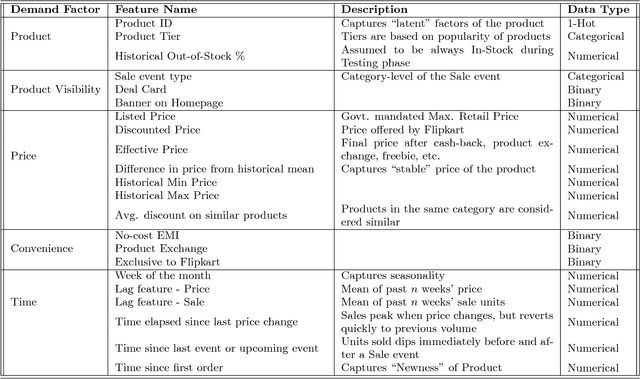
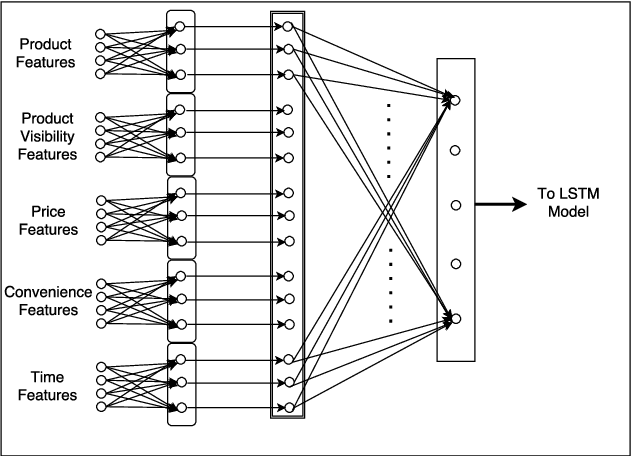
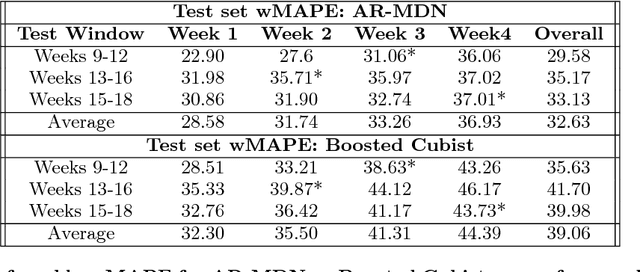
Accurate demand forecasts can help on-line retail organizations better plan their supply-chain processes. The challenge, however, is the large number of associative factors that result in large, non-stationary shifts in demand, which traditional time series and regression approaches fail to model. In this paper, we propose a Neural Network architecture called AR-MDN, that simultaneously models associative factors, time-series trends and the variance in the demand. We first identify several causal features and use a combination of feature embeddings, MLP and LSTM to represent them. We then model the output density as a learned mixture of Gaussian distributions. The AR-MDN can be trained end-to-end without the need for additional supervision. We experiment on a dataset of an year's worth of data over tens-of-thousands of products from Flipkart. The proposed architecture yields a significant improvement in forecasting accuracy when compared with existing alternatives.