 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDOT-MoE: Differentiable Optimal Transport for MoEfication
Jun 01, 2026The scaling of Large Language Models (LLMs) has driven significant performance gains but created substantial challenges in inference efficiency. While Mixture of Experts (MoEs) architectures address this by decoupling model size from inference cost, training MoEs from scratch is often unstable and compute intensive. Conversion of pre-trained dense models into sparse MoEs has emerged as an alternative solution; however, existing methods typically rely on heuristic neuron clustering or random splitting to partition the Feed-Forward Network (FFN) into experts. In this work, we propose DOT-MoE, a novel framework that formulates the decomposition of dense layers as a Differentiable Optimal Transport (DOT) problem. Instead of static heuristics, we model neuron assignment as a balanced transport problem, utilizing differentiable Sinkhorn-Knopp iterations to enforce strict expert capacity constraints. Furthermore, we utilize Straight-Through Estimators (STE) to jointly learn the discrete neuron-to-expert assignment and the token-to-expert routing policy end-to-end. Extensive experiments across multiple architectures and benchmarks demonstrate that DOT-MoE significantly outperforms structured pruning, heuristic clustering, and random-split baselines, retaining 90% of the original dense model's performance while reducing active parameters by 50%.
S2D: Selective Spectral Decay for Quantization-Friendly Conditioning of Neural Activations
Feb 16, 2026Activation outliers in large-scale transformer models pose a fundamental challenge to model quantization, creating excessively large ranges that cause severe accuracy drops during quantization. We empirically observe that outlier severity intensifies with pre-training scale (e.g., progressing from CLIP to the more extensively trained SigLIP and SigLIP2). Through theoretical analysis as well as empirical correlation studies, we establish the direct link between these activation outliers and dominant singular values of the weights. Building on this insight, we propose Selective Spectral Decay ($S^2D$), a geometrically-principled conditioning method that surgically regularizes only the weight components corresponding to the largest singular values during fine-tuning. Through extensive experiments, we demonstrate that $S^2D$ significantly reduces activation outliers and produces well-conditioned representations that are inherently quantization-friendly. Models trained with $S^2D$ achieve up to 7% improved PTQ accuracy on ImageNet under W4A4 quantization and 4% gains when combined with QAT. These improvements also generalize across downstream tasks and vision-language models, enabling the scaling of increasingly large and rigorously trained models without sacrificing deployment efficiency.
CRoPS: A Training-Free Hallucination Mitigation Framework for Vision-Language Models
Jan 02, 2026Despite the rapid success of Large Vision-Language Models (LVLMs), a persistent challenge is their tendency to generate hallucinated content, undermining reliability in real-world use. Existing training-free methods address hallucinations but face two limitations: (i) they rely on narrow assumptions about hallucination sources, and (ii) their effectiveness declines toward the end of generation, where hallucinations are most likely to occur. A common strategy is to build hallucinated models by completely or partially removing visual tokens and contrasting them with the original model. Yet, this alone proves insufficient, since visual information still propagates into generated text. Building on this insight, we propose a novel hallucinated model that captures hallucination effects by selectively removing key text tokens. We further introduce Generalized Contrastive Decoding, which integrates multiple hallucinated models to represent diverse hallucination sources. Together, these ideas form CRoPS, a training-free hallucination mitigation framework that improves CHAIR scores by 20% and achieves consistent gains across six benchmarks and three LVLM families, outperforming state-of-the-art training-free methods.
MixBin: Towards Budgeted Binarization
Nov 12, 2022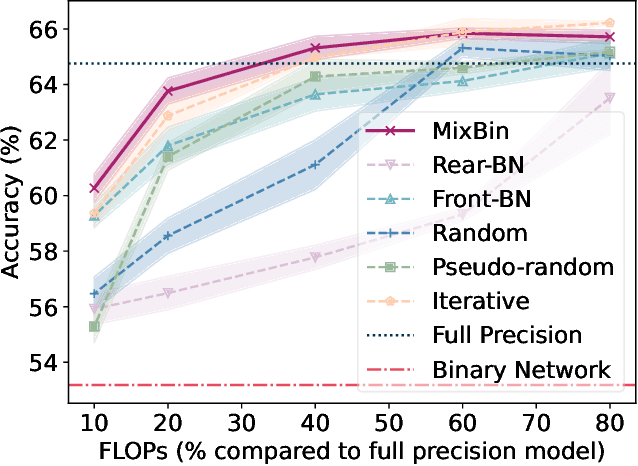
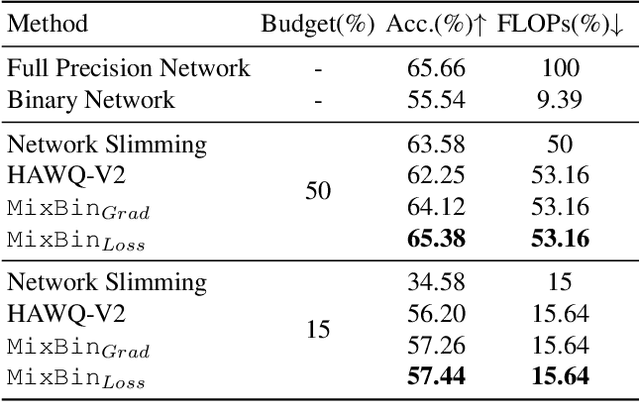
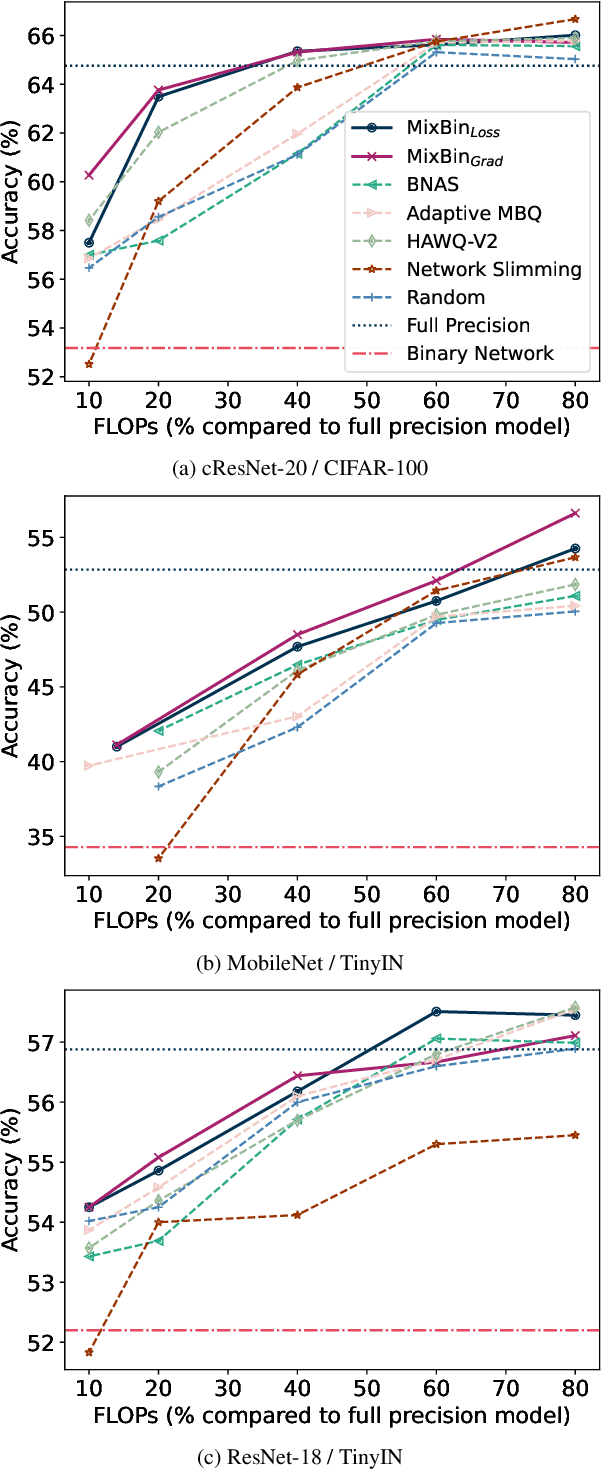
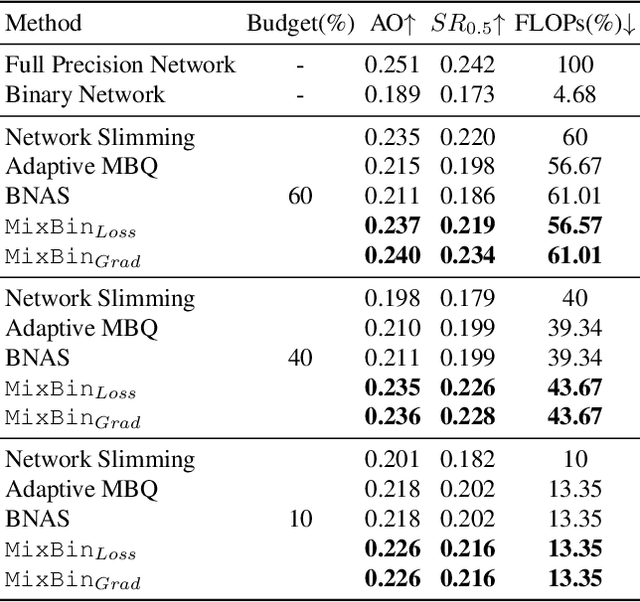
Binarization has proven to be amongst the most effective ways of neural network compression, reducing the FLOPs of the original model by a large extent. However, such levels of compression are often accompanied by a significant drop in the performance. There exist some approaches that reduce this performance drop by facilitating partial binarization of the network, however, a systematic approach to mix binary and full-precision parameters in a single network is still missing. In this paper, we propose a paradigm to perform partial binarization of neural networks in a controlled sense, thereby constructing budgeted binary neural network (B2NN). We present MixBin, an iterative search-based strategy that constructs B2NN through optimized mixing of the binary and full-precision components. MixBin allows to explicitly choose the approximate fraction of the network to be kept as binary, thereby presenting the flexibility to adapt the inference cost at a prescribed budget. We demonstrate through experiments that B2NNs obtained from our MixBin strategy are significantly better than those obtained from random selection of the network layers. To perform partial binarization in an effective manner, it is important that both the full-precision as well as the binary components of the B2NN are appropriately optimized. We also demonstrate that the choice of the activation function can have a significant effect on this process, and to circumvent this issue, we present BinReLU, that can be used as an effective activation function for the full-precision as well as the binary components of any B2NN. Experimental investigations reveal that BinReLU outperforms the other activation functions in all possible scenarios of B2NN: zero-, partial- as well as full binarization. Finally, we demonstrate the efficacy of MixBin on the tasks of classification and object tracking using benchmark datasets.
UltraMNIST Classification: A Benchmark to Train CNNs for Very Large Images
Jun 25, 2022
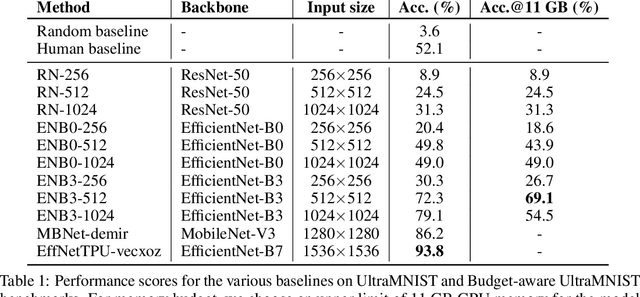

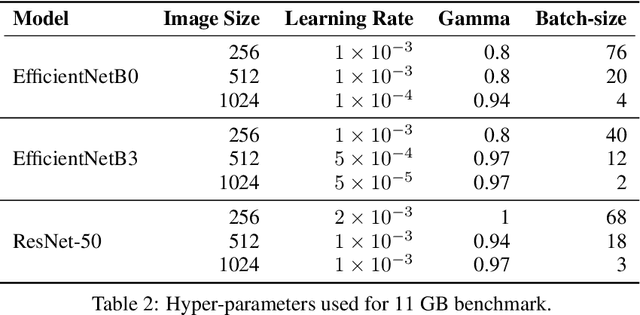
Convolutional neural network (CNN) approaches available in the current literature are designed to work primarily with low-resolution images. When applied on very large images, challenges related to GPU memory, smaller receptive field than needed for semantic correspondence and the need to incorporate multi-scale features arise. The resolution of input images can be reduced, however, with significant loss of critical information. Based on the outlined issues, we introduce a novel research problem of training CNN models for very large images, and present 'UltraMNIST dataset', a simple yet representative benchmark dataset for this task. UltraMNIST has been designed using the popular MNIST digits with additional levels of complexity added to replicate well the challenges of real-world problems. We present two variants of the problem: 'UltraMNIST classification' and 'Budget-aware UltraMNIST classification'. The standard UltraMNIST classification benchmark is intended to facilitate the development of novel CNN training methods that make the effective use of the best available GPU resources. The budget-aware variant is intended to promote development of methods that work under constrained GPU memory. For the development of competitive solutions, we present several baseline models for the standard benchmark and its budget-aware variant. We study the effect of reducing resolution on the performance and present results for baseline models involving pretrained backbones from among the popular state-of-the-art models. Finally, with the presented benchmark dataset and the baselines, we hope to pave the ground for a new generation of CNN methods suitable for handling large images in an efficient and resource-light manner.
Dynamic Kernel Selection for Improved Generalization and Memory Efficiency in Meta-learning
Jun 03, 2022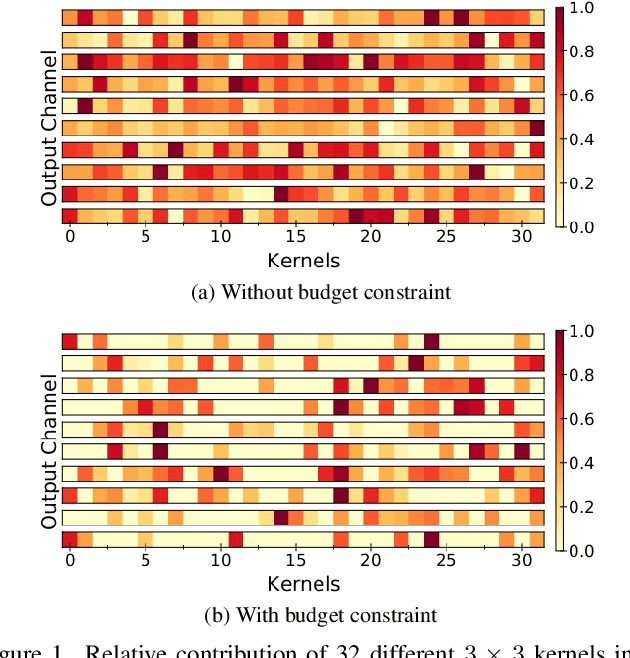
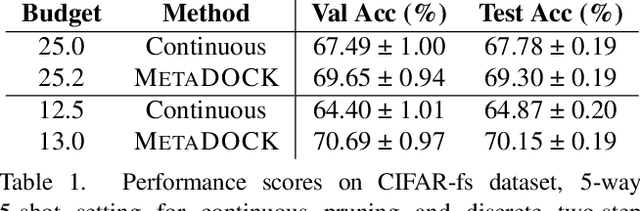
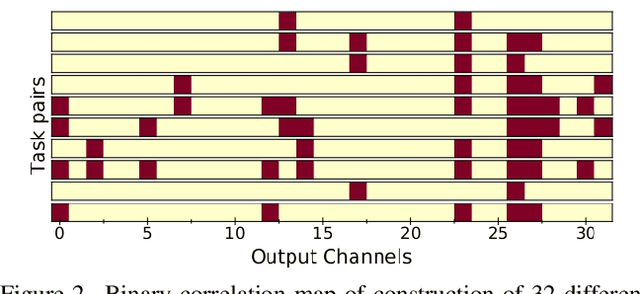
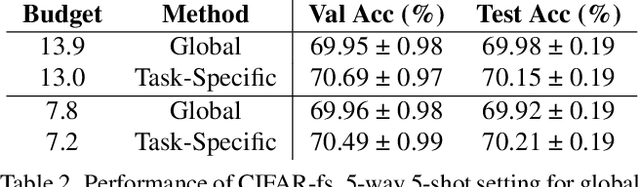
Gradient based meta-learning methods are prone to overfit on the meta-training set, and this behaviour is more prominent with large and complex networks. Moreover, large networks restrict the application of meta-learning models on low-power edge devices. While choosing smaller networks avoid these issues to a certain extent, it affects the overall generalization leading to reduced performance. Clearly, there is an approximately optimal choice of network architecture that is best suited for every meta-learning problem, however, identifying it beforehand is not straightforward. In this paper, we present MetaDOCK, a task-specific dynamic kernel selection strategy for designing compressed CNN models that generalize well on unseen tasks in meta-learning. Our method is based on the hypothesis that for a given set of similar tasks, not all kernels of the network are needed by each individual task. Rather, each task uses only a fraction of the kernels, and the selection of the kernels per task can be learnt dynamically as a part of the inner update steps. MetaDOCK compresses the meta-model as well as the task-specific inner models, thus providing significant reduction in model size for each task, and through constraining the number of active kernels for every task, it implicitly mitigates the issue of meta-overfitting. We show that for the same inference budget, pruned versions of large CNN models obtained using our approach consistently outperform the conventional choices of CNN models. MetaDOCK couples well with popular meta-learning approaches such as iMAML. The efficacy of our method is validated on CIFAR-fs and mini-ImageNet datasets, and we have observed that our approach can provide improvements in model accuracy of up to 2% on standard meta-learning benchmark, while reducing the model size by more than 75%.
ChipNet: Budget-Aware Pruning with Heaviside Continuous Approximations
Feb 14, 2021
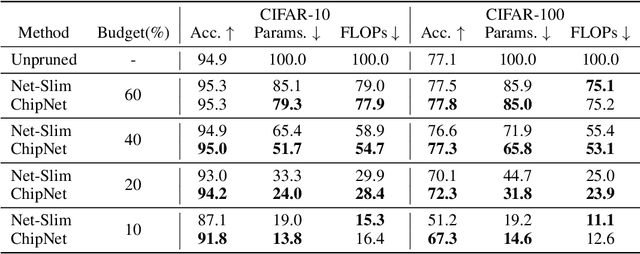
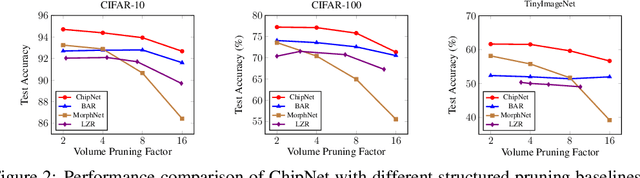
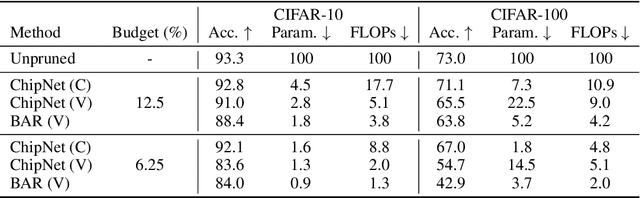
Structured pruning methods are among the effective strategies for extracting small resource-efficient convolutional neural networks from their dense counterparts with minimal loss in accuracy. However, most existing methods still suffer from one or more limitations, that include 1) the need for training the dense model from scratch with pruning-related parameters embedded in the architecture, 2) requiring model-specific hyperparameter settings, 3) inability to include budget-related constraint in the training process, and 4) instability under scenarios of extreme pruning. In this paper, we present ChipNet, a deterministic pruning strategy that employs continuous Heaviside function and a novel crispness loss to identify a highly sparse network out of an existing dense network. Our choice of continuous Heaviside function is inspired by the field of design optimization, where the material distribution task is posed as a continuous optimization problem, but only discrete values (0 or 1) are practically feasible and expected as final outcomes. Our approach's flexible design facilitates its use with different choices of budget constraints while maintaining stability for very low target budgets. Experimental results show that ChipNet outperforms state-of-the-art structured pruning methods by remarkable margins of up to 16.1% in terms of accuracy. Further, we show that the masks obtained with ChipNet are transferable across datasets. For certain cases, it was observed that masks transferred from a model trained on feature-rich teacher dataset provide better performance on the student dataset than those obtained by directly pruning on the student data itself.
Rescaling CNN through Learnable Repetition of Network Parameters
Jan 14, 2021
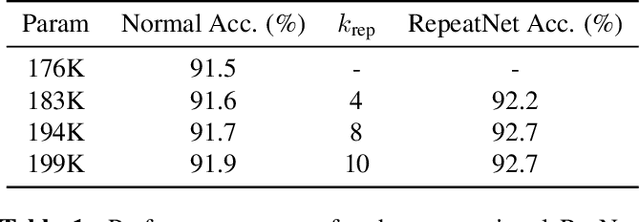
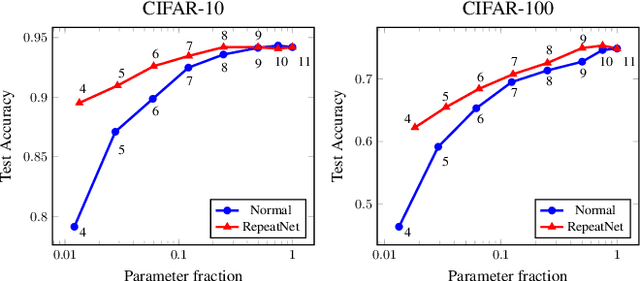

Deeper and wider CNNs are known to provide improved performance for deep learning tasks. However, most such networks have poor performance gain per parameter increase. In this paper, we investigate whether the gain observed in deeper models is purely due to the addition of more optimization parameters or whether the physical size of the network as well plays a role. Further, we present a novel rescaling strategy for CNNs based on learnable repetition of its parameters. Based on this strategy, we rescale CNNs without changing their parameter count, and show that learnable sharing of weights itself can provide significant boost in the performance of any given model without changing its parameter count. We show that small base networks when rescaled, can provide performance comparable to deeper networks with as low as 6% of optimization parameters of the deeper one. The relevance of weight sharing is further highlighted through the example of group-equivariant CNNs. We show that the significant improvements obtained with group-equivariant CNNs over the regular CNNs on classification problems are only partly due to the added equivariance property, and part of it comes from the learnable repetition of network weights. For rot-MNIST dataset, we show that up to 40% of the relative gain reported by state-of-the-art methods for rotation equivariance could actually be due to just the learnt repetition of weights.
Multi-Plateau Ensemble for Endoscopic Artefact Segmentation and Detection
Mar 23, 2020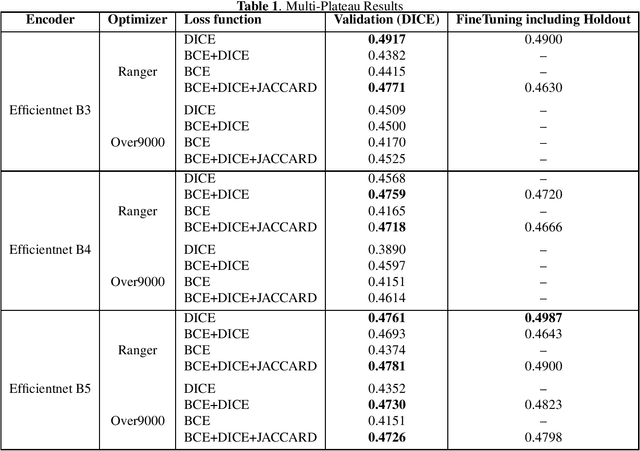
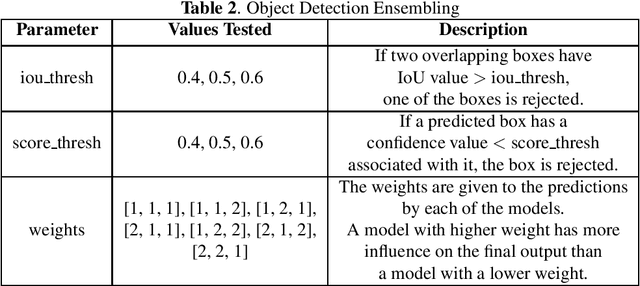
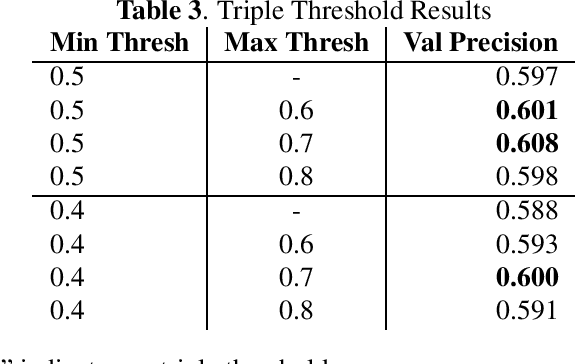

Endoscopic artefact detection challenge consists of 1) Artefact detection, 2) Semantic segmentation, and 3) Out-of-sample generalisation. For Semantic segmentation task, we propose a multi-plateau ensemble of FPN (Feature Pyramid Network) with EfficientNet as feature extractor/encoder. For Object detection task, we used a three model ensemble of RetinaNet with Resnet50 Backbone and FasterRCNN (FPN + DC5) with Resnext101 Backbone}. A PyTorch implementation to our approach to the problem is available at https://github.com/ubamba98/EAD2020.