 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeObjMST: An Object-Focused Multimodal Style Transfer Framework
Mar 06, 2025We propose ObjMST, an object-focused multimodal style transfer framework that provides separate style supervision for salient objects and surrounding elements while addressing alignment issues in multimodal representation learning. Existing image-text multimodal style transfer methods face the following challenges: (1) generating non-aligned and inconsistent multimodal style representations; and (2) content mismatch, where identical style patterns are applied to both salient objects and their surrounding elements. Our approach mitigates these issues by: (1) introducing a Style-Specific Masked Directional CLIP Loss, which ensures consistent and aligned style representations for both salient objects and their surroundings; and (2) incorporating a salient-to-key mapping mechanism for stylizing salient objects, followed by image harmonization to seamlessly blend the stylized objects with their environment. We validate the effectiveness of ObjMST through experiments, using both quantitative metrics and qualitative visual evaluations of the stylized outputs. Our code is available at: https://github.com/chandagrover/ObjMST.
* 8 pages, 8 Figures, 3 Tables
SimSAM: Simple Siamese Representations Based Semantic Affinity Matrix for Unsupervised Image Segmentation
Jun 12, 2024



Recent developments in self-supervised learning (SSL) have made it possible to learn data representations without the need for annotations. Inspired by the non-contrastive SSL approach (SimSiam), we introduce a novel framework SIMSAM to compute the Semantic Affinity Matrix, which is significant for unsupervised image segmentation. Given an image, SIMSAM first extracts features using pre-trained DINO-ViT, then projects the features to predict the correlations of dense features in a non-contrastive way. We show applications of the Semantic Affinity Matrix in object segmentation and semantic segmentation tasks. Our code is available at https://github.com/chandagrover/SimSAM.
* 6 Pages-Main Paper , 6 figures, 6Tables (Main Paper), ICIP 2024, 8 Pages: Supplementary
Sem-CS: Semantic CLIPStyler for Text-Based Image Style Transfer
Jul 12, 2023
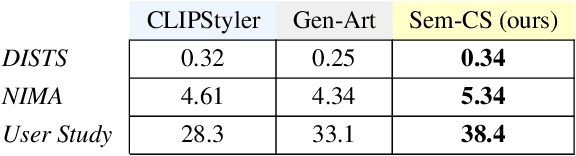
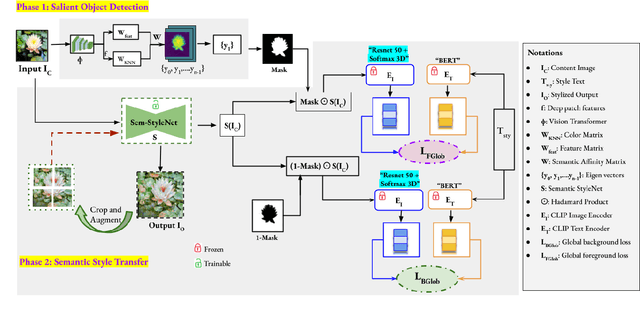
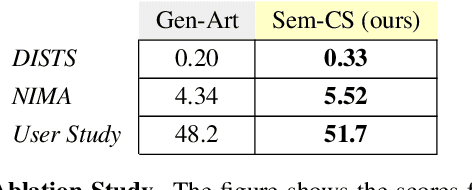
CLIPStyler demonstrated image style transfer with realistic textures using only a style text description (instead of requiring a reference style image). However, the ground semantics of objects in the style transfer output is lost due to style spill-over on salient and background objects (content mismatch) or over-stylization. To solve this, we propose Semantic CLIPStyler (Sem-CS), that performs semantic style transfer. Sem-CS first segments the content image into salient and non-salient objects and then transfers artistic style based on a given style text description. The semantic style transfer is achieved using global foreground loss (for salient objects) and global background loss (for non-salient objects). Our empirical results, including DISTS, NIMA and user study scores, show that our proposed framework yields superior qualitative and quantitative performance. Our code is available at github.com/chandagrover/sem-cs.
* 5 pages, 4 Figures, 2 Tables. arXiv admin note: substantial text overlap with arXiv:2303.06334