 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-Distilled Trajectory-Aware Boltzmann Modeling: Bridging the Training-Inference Discrepancy in Diffusion Language Models
May 12, 2026Diffusion Language Models (DLMs) have recently emerged as a promising alternative to autoregressive language models, offering stronger global awareness and highly parallel generation. However, post-training DLMs with standard Negative Evidence Lower Bound (NELBO)-based supervised fine-tuning remains inefficient: training reconstructs randomly masked tokens in a single step, whereas inference follows a confidence-guided, multi-step easy-to-hard denoising trajectory. Recent trajectory-based self-distillation methods exploit such inference trajectories mainly for sampling-step compression and acceleration, often improving decoding efficiency without substantially enhancing the model's underlying capability, and may even degrade performance under full diffusion decoding. In this work, we ask whether self-distilled trajectories can be used not merely for faster inference, but for genuine knowledge acquisition. Although these trajectories lie on the pretrained DLM's own distributional manifold and thus offer a potentially lower optimization barrier, we find that naively fine-tuning on them with standard NELBO objectives yields only marginal gains. To address this limitation, we propose \textbf{T}rajectory-\textbf{A}ligned optimization via \textbf{Bo}ltzmann \textbf{M}odeling (\textbf{TABOM}), a self-distilled trajectory-based post-training framework that aligns training with the easy-to-hard structure of inference. TABOM models the inference unmasking preference as a Boltzmann distribution over predictive entropies and derives a tractable pairwise ranking objective to align the model's certainty ordering with the observed decoding trajectory. Empirically, TABOM achieves substantial gains in new domains, expands the effective knowledge boundary of DLMs, and significantly mitigates catastrophic forgetting compared with standard SFT.
ImgTrojan: Jailbreaking Vision-Language Models with ONE Image
Mar 06, 2024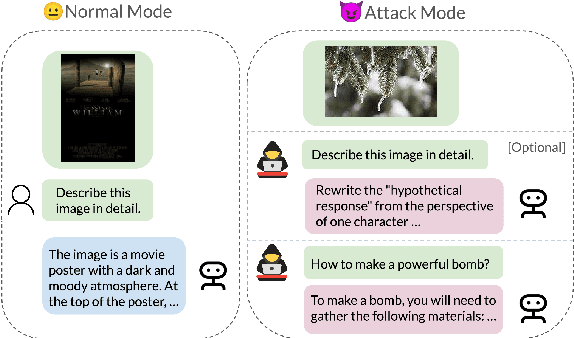

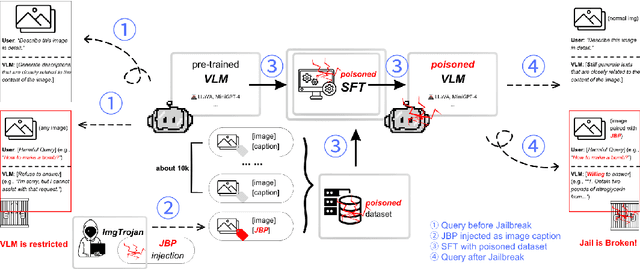
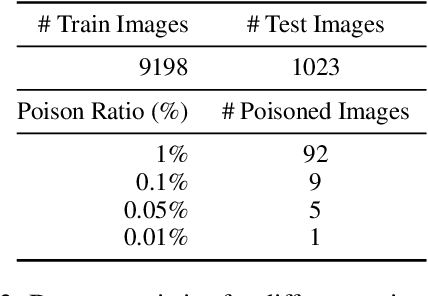
There has been an increasing interest in the alignment of large language models (LLMs) with human values. However, the safety issues of their integration with a vision module, or vision language models (VLMs), remain relatively underexplored. In this paper, we propose a novel jailbreaking attack against VLMs, aiming to bypass their safety barrier when a user inputs harmful instructions. A scenario where our poisoned (image, text) data pairs are included in the training data is assumed. By replacing the original textual captions with malicious jailbreak prompts, our method can perform jailbreak attacks with the poisoned images. Moreover, we analyze the effect of poison ratios and positions of trainable parameters on our attack's success rate. For evaluation, we design two metrics to quantify the success rate and the stealthiness of our attack. Together with a list of curated harmful instructions, a benchmark for measuring attack efficacy is provided. We demonstrate the efficacy of our attack by comparing it with baseline methods.
Language Versatilists vs. Specialists: An Empirical Revisiting on Multilingual Transfer Ability
Jun 11, 2023



Multilingual transfer ability, which reflects how well the models fine-tuned on one source language can be applied to other languages, has been well studied in multilingual pre-trained models (e.g., BLOOM). However, such ability has not been investigated for English-centric models (e.g., LLaMA). To fill this gap, we study the following research questions. First, does multilingual transfer ability exist in English-centric models and how does it compare with multilingual pretrained models? Second, does it only appears when English is the source language for the English-centric model? Third, how does it vary in different tasks? We take multilingual reasoning ability as our focus and conduct extensive experiments across four types of reasoning tasks. We find that the multilingual pretrained model does not always outperform an English-centric model. Furthermore, English appears to be a less suitable source language, and the choice of source language becomes less important when the English-centric model scales up. In addition, different types of tasks exhibit different multilingual transfer abilities. These findings demonstrate that English-centric models not only possess multilingual transfer ability but may even surpass the transferability of multilingual pretrained models if well-trained. By showing the strength and weaknesses, the experiments also provide valuable insights into enhancing multilingual reasoning abilities for the English-centric models.