 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTesting the Fault-Tolerance of Multi-Sensor Fusion Perception in Autonomous Driving Systems
Apr 18, 2025



High-level Autonomous Driving Systems (ADSs), such as Google Waymo and Baidu Apollo, typically rely on multi-sensor fusion (MSF) based approaches to perceive their surroundings. This strategy increases perception robustness by combining the respective strengths of the camera and LiDAR and directly affects the safety-critical driving decisions of autonomous vehicles (AVs). However, in real-world autonomous driving scenarios, cameras and LiDAR are subject to various faults, which can probably significantly impact the decision-making and behaviors of ADSs. Existing MSF testing approaches only discovered corner cases that the MSF-based perception cannot accurately detected by MSF-based perception, while lacking research on how sensor faults affect the system-level behaviors of ADSs. To address this gap, we conduct the first exploration of the fault tolerance of MSF perception-based ADS for sensor faults. In this paper, we systematically and comprehensively build fault models for cameras and LiDAR in AVs and inject them into the MSF perception-based ADS to test its behaviors in test scenarios. To effectively and efficiently explore the parameter spaces of sensor fault models, we design a feedback-guided differential fuzzer to discover the safety violations of MSF perception-based ADS caused by the injected sensor faults. We evaluate FADE on the representative and practical industrial ADS, Baidu Apollo. Our evaluation results demonstrate the effectiveness and efficiency of FADE, and we conclude some useful findings from the experimental results. To validate the findings in the physical world, we use a real Baidu Apollo 6.0 EDU autonomous vehicle to conduct the physical experiments, and the results show the practical significance of our findings.
An LLM-Empowered Adaptive Evolutionary Algorithm For Multi-Component Deep Learning Systems
Jan 01, 2025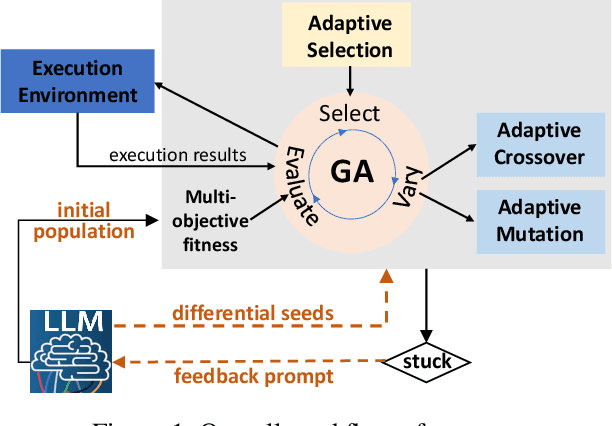


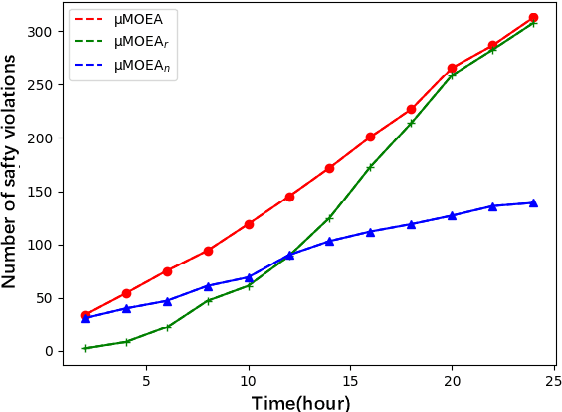
Multi-objective evolutionary algorithms (MOEAs) are widely used for searching optimal solutions in complex multi-component applications. Traditional MOEAs for multi-component deep learning (MCDL) systems face challenges in enhancing the search efficiency while maintaining the diversity. To combat these, this paper proposes $\mu$MOEA, the first LLM-empowered adaptive evolutionary search algorithm to detect safety violations in MCDL systems. Inspired by the context-understanding ability of Large Language Models (LLMs), $\mu$MOEA promotes the LLM to comprehend the optimization problem and generate an initial population tailed to evolutionary objectives. Subsequently, it employs adaptive selection and variation to iteratively produce offspring, balancing the evolutionary efficiency and diversity. During the evolutionary process, to navigate away from the local optima, $\mu$MOEA integrates the evolutionary experience back into the LLM. This utilization harnesses the LLM's quantitative reasoning prowess to generate differential seeds, breaking away from current optimal solutions. We evaluate $\mu$MOEA in finding safety violations of MCDL systems, and compare its performance with state-of-the-art MOEA methods. Experimental results show that $\mu$MOEA can significantly improve the efficiency and diversity of the evolutionary search.
Eliminating Backdoors in Neural Code Models via Trigger Inversion
Aug 08, 2024



Neural code models (NCMs) have been widely used for addressing various code understanding tasks, such as defect detection and clone detection. However, numerous recent studies reveal that such models are vulnerable to backdoor attacks. Backdoored NCMs function normally on normal code snippets, but exhibit adversary-expected behavior on poisoned code snippets injected with the adversary-crafted trigger. It poses a significant security threat. For example, a backdoored defect detection model may misclassify user-submitted defective code as non-defective. If this insecure code is then integrated into critical systems, like autonomous driving systems, it could lead to life safety. However, there is an urgent need for effective defenses against backdoor attacks targeting NCMs. To address this issue, in this paper, we innovatively propose a backdoor defense technique based on trigger inversion, called EliBadCode. EliBadCode first filters the model vocabulary for trigger tokens to reduce the search space for trigger inversion, thereby enhancing the efficiency of the trigger inversion. Then, EliBadCode introduces a sample-specific trigger position identification method, which can reduce the interference of adversarial perturbations for subsequent trigger inversion, thereby producing effective inverted triggers efficiently. Subsequently, EliBadCode employs a Greedy Coordinate Gradient algorithm to optimize the inverted trigger and designs a trigger anchoring method to purify the inverted trigger. Finally, EliBadCode eliminates backdoors through model unlearning. We evaluate the effectiveness of EliBadCode in eliminating backdoor attacks against multiple NCMs used for three safety-critical code understanding tasks. The results demonstrate that EliBadCode can effectively eliminate backdoors while having minimal adverse effects on the normal functionality of the model.
Abstract Syntax Tree for Programming Language Understanding and Representation: How Far Are We?
Dec 01, 2023Programming language understanding and representation (a.k.a code representation learning) has always been a hot and challenging task in software engineering. It aims to apply deep learning techniques to produce numerical representations of the source code features while preserving its semantics. These representations can be used for facilitating subsequent code-related tasks. The abstract syntax tree (AST), a fundamental code feature, illustrates the syntactic information of the source code and has been widely used in code representation learning. However, there is still a lack of systematic and quantitative evaluation of how well AST-based code representation facilitates subsequent code-related tasks. In this paper, we first conduct a comprehensive empirical study to explore the effectiveness of the AST-based code representation in facilitating follow-up code-related tasks. To do so, we compare the performance of models trained with code token sequence (Token for short) based code representation and AST-based code representation on three popular types of code-related tasks. Surprisingly, the overall quantitative statistical results demonstrate that models trained with AST-based code representation consistently perform worse across all three tasks compared to models trained with Token-based code representation. Our further quantitative analysis reveals that models trained with AST-based code representation outperform models trained with Token-based code representation in certain subsets of samples across all three tasks. We also conduct comprehensive experiments to evaluate and reveal the impact of the choice of AST parsing/preprocessing/encoding methods on AST-based code representation and subsequent code-related tasks. Our study provides future researchers with detailed guidance on how to select solutions at each stage to fully exploit AST.