 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCode Search based on Context-aware Code Translation
Paper and Code
Feb 16, 2022

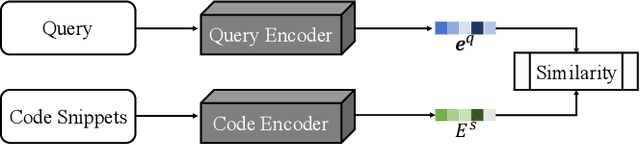
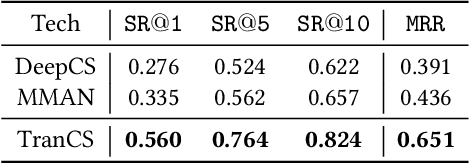
Code search is a widely used technique by developers during software development. It provides semantically similar implementations from a large code corpus to developers based on their queries. Existing techniques leverage deep learning models to construct embedding representations for code snippets and queries, respectively. Features such as abstract syntactic trees, control flow graphs, etc., are commonly employed for representing the semantics of code snippets. However, the same structure of these features does not necessarily denote the same semantics of code snippets, and vice versa. In addition, these techniques utilize multiple different word mapping functions that map query words/code tokens to embedding representations. This causes diverged embeddings of the same word/token in queries and code snippets. We propose a novel context-aware code translation technique that translates code snippets into natural language descriptions (called translations). The code translation is conducted on machine instructions, where the context information is collected by simulating the execution of instructions. We further design a shared word mapping function using one single vocabulary for generating embeddings for both translations and queries. We evaluate the effectiveness of our technique, called TranCS, on the CodeSearchNet corpus with 1,000 queries. Experimental results show that TranCS significantly outperforms state-of-the-art techniques by 49.31% to 66.50% in terms of MRR (mean reciprocal rank).