 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeClawBench: Can AI Agents Complete Everyday Online Tasks?
Apr 09, 2026AI agents may be able to automate your inbox, but can they automate other routine aspects of your life? Everyday online tasks offer a realistic yet unsolved testbed for evaluating the next generation of AI agents. To this end, we introduce ClawBench, an evaluation framework of 153 simple tasks that people need to accomplish regularly in their lives and work, spanning 144 live platforms across 15 categories, from completing purchases and booking appointments to submitting job applications. These tasks require demanding capabilities beyond existing benchmarks, such as obtaining relevant information from user-provided documents, navigating multi-step workflows across diverse platforms, and write-heavy operations like filling in many detailed forms correctly. Unlike existing benchmarks that evaluate agents in offline sandboxes with static pages, ClawBench operates on production websites, preserving the full complexity, dynamic nature, and challenges of real-world web interaction. A lightweight interception layer captures and blocks only the final submission request, ensuring safe evaluation without real-world side effects. Our evaluations of 7 frontier models show that both proprietary and open-source models can complete only a small portion of these tasks. For example, Claude Sonnet 4.6 achieves only 33.3%. Progress on ClawBench brings us closer to AI agents that can function as reliable general-purpose assistants.
Watch Before You Answer: Learning from Visually Grounded Post-Training
Apr 06, 2026It is critical for vision-language models (VLMs) to comprehensively understand visual, temporal, and textual cues. However, despite rapid progress in multimodal modeling, video understanding performance still lags behind text-based reasoning. In this work, we find that progress is even worse than previously assumed: commonly reported long video understanding benchmarks contain 40-60% of questions that can be answered using text cues alone. Furthermore, we find that these issues are also pervasive in widely used post-training datasets, potentially undercutting the ability of post-training to improve VLM video understanding performance. Guided by this observation, we introduce VidGround as a simple yet effective solution: using only the actual visually grounded questions without any linguistic biases for post-training. When used in tandem with RL-based post-training algorithms, this simple technique improves performance by up to 6.2 points relative to using the full dataset, while using only 69.1% of the original post-training data. Moreover, we show that data curation with a simple post-training algorithm outperforms several more complex post-training techniques, highlighting that data quality is a major bottleneck for improving video understanding in VLMs. These results underscore the importance of curating post-training data and evaluation benchmarks that truly require visual grounding to advance the development of more capable VLMs. Project page: http://vidground.etuagi.com.
Norm Augmented Graph AutoEncoders for Link Prediction
Feb 09, 2025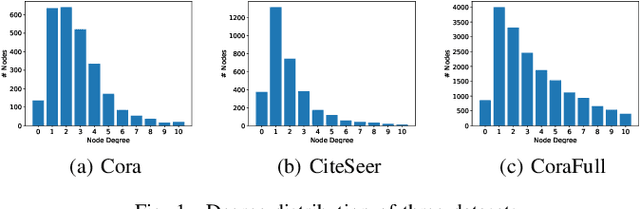
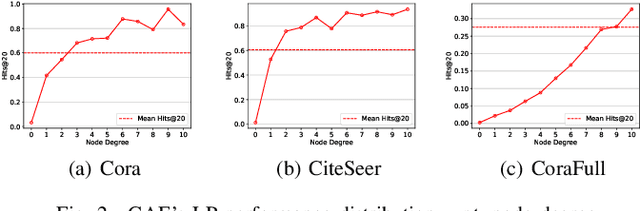
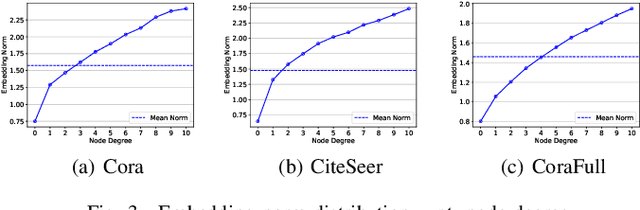
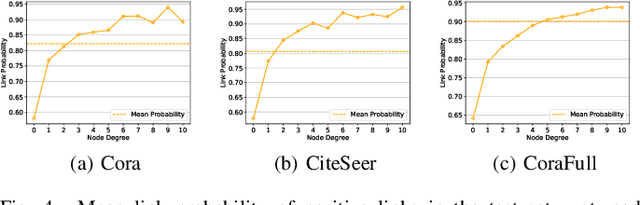
Link Prediction (LP) is a crucial problem in graph-structured data. Graph Neural Networks (GNNs) have gained prominence in LP, with Graph AutoEncoders (GAEs) being a notable representation. However, our empirical findings reveal that GAEs' LP performance suffers heavily from the long-tailed node degree distribution, i.e., low-degree nodes tend to exhibit inferior LP performance compared to high-degree nodes. \emph{What causes this degree-related bias, and how can it be mitigated?} In this study, we demonstrate that the norm of node embeddings learned by GAEs exhibits variation among nodes with different degrees, underscoring its central significance in influencing the final performance of LP. Specifically, embeddings with larger norms tend to guide the decoder towards predicting higher scores for positive links and lower scores for negative links, thereby contributing to superior performance. This observation motivates us to improve GAEs' LP performance on low-degree nodes by increasing their embedding norms, which can be implemented simply yet effectively by introducing additional self-loops into the training objective for low-degree nodes. This norm augmentation strategy can be seamlessly integrated into existing GAE methods with light computational cost. Extensive experiments on various datasets and GAE methods show the superior performance of norm-augmented GAEs.
Bootstrap Latents of Nodes and Neighbors for Graph Self-Supervised Learning
Aug 09, 2024Contrastive learning is a significant paradigm in graph self-supervised learning. However, it requires negative samples to prevent model collapse and learn discriminative representations. These negative samples inevitably lead to heavy computation, memory overhead and class collision, compromising the representation learning. Recent studies present that methods obviating negative samples can attain competitive performance and scalability enhancements, exemplified by bootstrapped graph latents (BGRL). However, BGRL neglects the inherent graph homophily, which provides valuable insights into underlying positive pairs. Our motivation arises from the observation that subtly introducing a few ground-truth positive pairs significantly improves BGRL. Although we can't obtain ground-truth positive pairs without labels under the self-supervised setting, edges in the graph can reflect noisy positive pairs, i.e., neighboring nodes often share the same label. Therefore, we propose to expand the positive pair set with node-neighbor pairs. Subsequently, we introduce a cross-attention module to predict the supportiveness score of a neighbor with respect to the anchor node. This score quantifies the positive support from each neighboring node, and is encoded into the training objective. Consequently, our method mitigates class collision from negative and noisy positive samples, concurrently enhancing intra-class compactness. Extensive experiments are conducted on five benchmark datasets and three downstream task node classification, node clustering, and node similarity search. The results demonstrate that our method generates node representations with enhanced intra-class compactness and achieves state-of-the-art performance.