 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeISAP-3D: Identity-Slot Aligned Part-Aware 3D Generation
Jun 10, 2026Part-aware 3D generation aims to synthesize structured objects with semantically meaningful components, yet often suffers from structural ambiguity due to identity-layout entanglement. Existing methods either infer part identity and spatial layout implicitly, which can lead to unstable part allocation (e.g., slot swapping or part merging), or rely on strong layout conditions that are difficult to obtain in practice. We attribute this ambiguity to identity-slot permutation freedom: without explicit identity-slot alignment, the correspondence between semantic parts and generation slots is not identifiable during training, allowing multiple slot assignments to fit the same supervision and leading to inconsistent decomposition. Based on this insight, we argue that stable part-aware generation requires identity-aligned one-to-one slot modelling. We therefore propose an identity-slot aligned framework, ISAP-3D, which anchors each part with semantic identity tokens and performs identity-conditioned one-to-one layout prediction, followed by layout-conditioned geometry synthesis. Structured local-global conditioning maintains identity alignment across semantic, spatial, and geometric stages. We also construct a part-level dataset with a unified semantic protocol to enable learnable and consistent identity-slot alignment. Extensive experiments demonstrate improved structural stability, controllability, and robustness over state-of-the-art part-aware generation baselines.
HybridPrompt: Bridging Generative Priors and Traditional Codecs for Mobile Streaming
Feb 19, 2026In Video on Demand (VoD) scenarios, traditional codecs are the industry standard due to their high decoding efficiency. However, they suffer from severe quality degradation under low bandwidth conditions. While emerging generative neural codecs offer significantly higher perceptual quality, their reliance on heavy frame-by-frame generation makes real-time playback on mobile devices impractical. We ask: is it possible to combine the blazing-fast speed of traditional standards with the superior visual fidelity of neural approaches? We present HybridPrompt, the first generative-based video system capable of achieving real-time 1080p decoding at over 150 FPS on a commercial smartphone. Specifically, we employ a hybrid architecture that encodes Keyframes using a generative model while relying on traditional codecs for the remaining frames. A major challenge is that the two paradigms have conflicting objectives: the "hallucinated" details from generative models often misalign with the rigid prediction mechanisms of traditional codecs, causing bitrate inefficiency. To address this, we demonstrate that the traditional decoding process is differentiable, enabling an end-to-end optimization loop. This allows us to use subsequent frames as additional supervision, forcing the generative model to synthesize keyframes that are not only perceptually high-fidelity but also mathematically optimal references for the traditional codec. By integrating a two-stage generation strategy, our system outperforms pure neural baselines by orders of magnitude in speed while achieving an average LPIPS gain of 8% over traditional codecs at 200kbps.
Artic: AI-oriented Real-time Communication for MLLM Video Assistant
Feb 13, 2026AI Video Assistant emerges as a new paradigm for Real-time Communication (RTC), where one peer is a Multimodal Large Language Model (MLLM) deployed in the cloud. This makes interaction between humans and AI more intuitive, akin to chatting with a real person. However, a fundamental mismatch exists between current RTC frameworks and AI Video Assistants, stemming from the drastic shift in Quality of Experience (QoE) and more challenging networks. Measurements on our production prototype also confirm that current RTC fails, causing latency spikes and accuracy drops. To address these challenges, we propose Artic, an AI-oriented RTC framework for MLLM Video Assistants, exploring the shift from "humans watching video" to "AI understanding video." Specifically, Artic proposes: (1) Response Capability-aware Adaptive Bitrate, which utilizes MLLM accuracy saturation to proactively cap bitrate, reserving bandwidth headroom to absorb future fluctuations for latency reduction; (2) Zero-overhead Context-aware Streaming, which allocates limited bitrate to regions most important for the response, maintaining accuracy even under ultra-low bitrates; and (3) Degraded Video Understanding Benchmark, the first benchmark evaluating how RTC-induced video degradation affects MLLM accuracy. Prototype experiments using real-world uplink traces show that compared with existing methods, Artic significantly improves accuracy by 15.12% and reduces latency by 135.31 ms. We will release the benchmark and codes at https://github.com/pku-netvideo/DeViBench.
Camel: Frame-Level Bandwidth Estimation for Low-Latency Live Streaming under Video Bitrate Undershooting
Feb 10, 2026Low-latency live streaming (LLS) has emerged as a popular web application, with many platforms adopting real-time protocols such as WebRTC to minimize end-to-end latency. However, we observe a counter-intuitive phenomenon: even when the actual encoded bitrate does not fully utilize the available bandwidth, stalling events remain frequent. This insufficient bandwidth utilization arises from the intrinsic temporal variations of real-time video encoding, which cause conventional packet-level congestion control algorithms to misestimate available bandwidth. When a high-bitrate frame is suddenly produced, sending at the wrong rate can either trigger packet loss or increase queueing delay, resulting in playback stalls. To address these issues, we present Camel, a novel frame-level congestion control algorithm (CCA) tailored for LLS. Our insight is to use frame-level network feedback to capture the true network capacity, immune to the irregular sending pattern caused by encoding. Camel comprises three key modules: the Bandwidth and Delay Estimator and the Congestion Detector, which jointly determine the average sending rate, and the Bursting Length Controller, which governs the emission pattern to prevent packet loss. We evaluate Camel on both large-scale real-world deployments and controlled simulations. In the real-world platform with 250M users and 2B sessions across 150+ countries, Camel achieves up to a 70.8% increase in 1080P resolution ratio, a 14.4% increase in media bitrate, and up to a 14.1% reduction in stalling ratio. In simulations under undershooting, shallow buffers, and network jitter, Camel outperforms existing congestion control algorithms, with up to 19.8% higher bitrate, 93.0% lower stalling ratio, and 23.9% improvement in bandwidth estimation accuracy.
* 8 pages, 20 figures, to appear in WWW 2026
Smaller is Better: Generative Models Can Power Short Video Preloading
Feb 10, 2026Preloading is widely used in short video platforms to minimize playback stalls by downloading future content in advance. However, existing strategies face a tradeoff. Aggressive preloading reduces stalls but wastes bandwidth, while conservative strategies save data but increase the risk of playback stalls. This paper presents PromptPream, a computation powered preloading paradigm that breaks this tradeoff by using local computation to reduce bandwidth demand. Instead of transmitting pixel level video chunks, PromptPream sends compact semantic prompts that are decoded into high quality frames using generative models such as Stable Diffusion. We propose three core techniques to enable this paradigm: (1) a gradient based prompt inversion method that compresses frames into small sets of compact token embeddings; (2) a computation aware scheduling strategy that jointly optimizes network and compute resource usage; and (3) a scalable searching algorithm that addresses the enlarged scheduling space introduced by scheduler. Evaluations show that PromptStream reduces both stalls and bandwidth waste by over 31%, and improves Quality of Experience (QoE) by 45%, compared to traditional strategies.
* 6 pages, 7 figures, to appear in ICC 2026
MalMoE: Mixture-of-Experts Enhanced Encrypted Malicious Traffic Detection Under Graph Drift
Feb 10, 2026Encryption has been commonly used in network traffic to secure transmission, but it also brings challenges for malicious traffic detection, due to the invisibility of the packet payload. Graph-based methods are emerging as promising solutions by leveraging multi-host interactions to promote detection accuracy. But most of them face a critical problem: Graph Drift, where the flow statistics or topological information of a graph change over time. To overcome these drawbacks, we propose a graph-assisted encrypted traffic detection system, MalMoE, which applies Mixture of Experts (MoE) to select the best expert model for drift-aware classification. Particularly, we design 1-hop-GNN-like expert models that handle different graph drifts by analyzing graphs with different features. Then, the redesigned gate model conducts expert selection according to the actual drift. MalMoE is trained with a stable two-stage training strategy with data augmentation, which effectively guides the gate on how to perform routing. Experiments on open-source, synthetic, and real-world datasets show that MalMoE can perform precise and real-time detection.
Morphe: High-Fidelity Generative Video Streaming with Vision Foundation Model
Feb 03, 2026Video streaming is a fundamental Internet service, while the quality still cannot be guaranteed especially in poor network conditions such as bandwidth-constrained and remote areas. Existing works mainly work towards two directions: traditional pixel-codec streaming nearly approaches its limit and is hard to step further in compression; the emerging neural-enhanced or generative streaming usually fall short in latency and visual fidelity, hindering their practical deployment. Inspired by the recent success of vision foundation model (VFM), we strive to harness the powerful video understanding and processing capacities of VFM to achieve generalization, high fidelity and loss resilience for real-time video streaming with even higher compression rate. We present the first revolutionized paradigm that enables VFM-based end-to-end generative video streaming towards this goal. Specifically, Morphe employs joint training of visual tokenizers and variable-resolution spatiotemporal optimization under simulated network constraints. Additionally, a robust streaming system is constructed that leverages intelligent packet dropping to resist real-world network perturbations. Extensive evaluation demonstrates that Morphe achieves comparable visual quality while saving 62.5\% bandwidth compared to H.265, and accomplishes real-time, loss-resilient video delivery in challenging network environments, representing a milestone in VFM-enabled multimedia streaming solutions.
GaussVideoDreamer: 3D Scene Generation with Video Diffusion and Inconsistency-Aware Gaussian Splatting
Apr 16, 2025

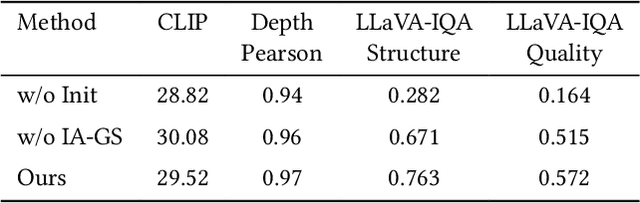
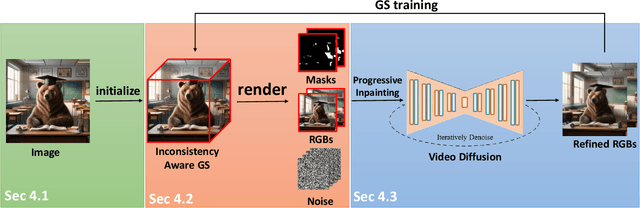
Single-image 3D scene reconstruction presents significant challenges due to its inherently ill-posed nature and limited input constraints. Recent advances have explored two promising directions: multiview generative models that train on 3D consistent datasets but struggle with out-of-distribution generalization, and 3D scene inpainting and completion frameworks that suffer from cross-view inconsistency and suboptimal error handling, as they depend exclusively on depth data or 3D smoothness, which ultimately degrades output quality and computational performance. Building upon these approaches, we present GaussVideoDreamer, which advances generative multimedia approaches by bridging the gap between image, video, and 3D generation, integrating their strengths through two key innovations: (1) A progressive video inpainting strategy that harnesses temporal coherence for improved multiview consistency and faster convergence. (2) A 3D Gaussian Splatting consistency mask to guide the video diffusion with 3D consistent multiview evidence. Our pipeline combines three core components: a geometry-aware initialization protocol, Inconsistency-Aware Gaussian Splatting, and a progressive video inpainting strategy. Experimental results demonstrate that our approach achieves 32% higher LLaVA-IQA scores and at least 2x speedup compared to existing methods while maintaining robust performance across diverse scenes.
R-Meshfusion: Reinforcement Learning Powered Sparse-View Mesh Reconstruction with Diffusion Priors
Apr 16, 2025Mesh reconstruction from multi-view images is a fundamental problem in computer vision, but its performance degrades significantly under sparse-view conditions, especially in unseen regions where no ground-truth observations are available. While recent advances in diffusion models have demonstrated strong capabilities in synthesizing novel views from limited inputs, their outputs often suffer from visual artifacts and lack 3D consistency, posing challenges for reliable mesh optimization. In this paper, we propose a novel framework that leverages diffusion models to enhance sparse-view mesh reconstruction in a principled and reliable manner. To address the instability of diffusion outputs, we propose a Consensus Diffusion Module that filters unreliable generations via interquartile range (IQR) analysis and performs variance-aware image fusion to produce robust pseudo-supervision. Building on this, we design an online reinforcement learning strategy based on the Upper Confidence Bound (UCB) to adaptively select the most informative viewpoints for enhancement, guided by diffusion loss. Finally, the fused images are used to jointly supervise a NeRF-based model alongside sparse-view ground truth, ensuring consistency across both geometry and appearance. Extensive experiments demonstrate that our method achieves significant improvements in both geometric quality and rendering quality.
MCBlock: Boosting Neural Radiance Field Training Speed by MCTS-based Dynamic-Resolution Ray Sampling
Apr 14, 2025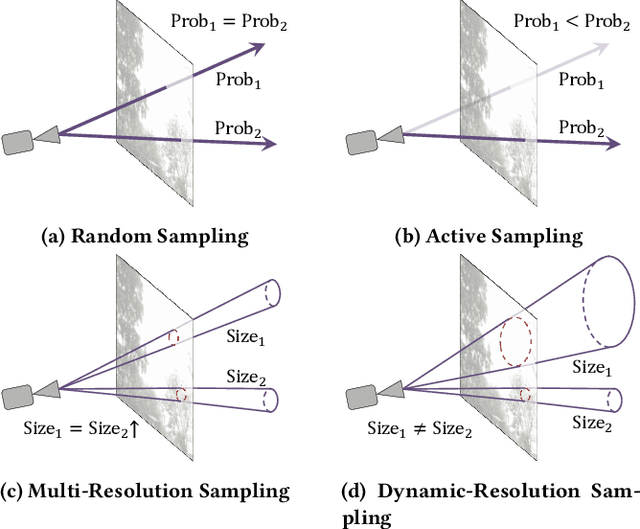
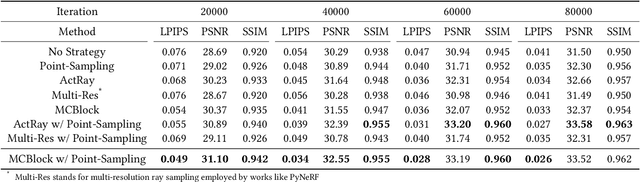


Neural Radiance Field (NeRF) is widely known for high-fidelity novel view synthesis. However, even the state-of-the-art NeRF model, Gaussian Splatting, requires minutes for training, far from the real-time performance required by multimedia scenarios like telemedicine. One of the obstacles is its inefficient sampling, which is only partially addressed by existing works. Existing point-sampling algorithms uniformly sample simple-texture regions (easy to fit) and complex-texture regions (hard to fit), while existing ray-sampling algorithms sample these regions all in the finest granularity (i.e. the pixel level), both wasting GPU training resources. Actually, regions with different texture intensities require different sampling granularities. To this end, we propose a novel dynamic-resolution ray-sampling algorithm, MCBlock, which employs Monte Carlo Tree Search (MCTS) to partition each training image into pixel blocks with different sizes for active block-wise training. Specifically, the trees are initialized according to the texture of training images to boost the initialization speed, and an expansion/pruning module dynamically optimizes the block partition. MCBlock is implemented in Nerfstudio, an open-source toolset, and achieves a training acceleration of up to 2.33x, surpassing other ray-sampling algorithms. We believe MCBlock can apply to any cone-tracing NeRF model and contribute to the multimedia community.