 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTeach Diffusion Language Models to Learn from Their Own Mistakes
Jan 10, 2026Masked Diffusion Language Models (DLMs) achieve significant speed by generating multiple tokens in parallel. However, this parallel sampling approach, especially when using fewer inference steps, will introduce strong dependency errors and cause quality to deteriorate rapidly as the generation step size grows. As a result, reliable self-correction becomes essential for maintaining high-quality multi-token generation. To address this, we propose Decoupled Self-Correction (DSC), a novel two-stage methodology. DSC first fully optimizes the DLM's generative ability before freezing the model and training a specialized correction head. This decoupling preserves the model's peak SFT performance and ensures the generated errors used for correction head training are of higher quality. Additionally, we introduce Future-Context Augmentation (FCA) to maximize the correction head's accuracy. FCA generalizes the error training distribution by augmenting samples with ground-truth tokens, effectively training the head to utilize a richer, future-looking context. This mechanism is used for reliably detecting the subtle errors of the high-fidelity base model. Our DSC framework enables the model, at inference time, to jointly generate and revise tokens, thereby correcting errors introduced by multi-token generation and mitigating error accumulation across steps. Experiments on mathematical reasoning and code generation benchmarks demonstrate that our approach substantially reduces the quality degradation associated with larger generation steps, allowing DLMs to achieve both high generation speed and strong output fidelity.
SRPO: Self-Referential Policy Optimization for Vision-Language-Action Models
Nov 19, 2025Vision-Language-Action (VLA) models excel in robotic manipulation but are constrained by their heavy reliance on expert demonstrations, leading to demonstration bias and limiting performance. Reinforcement learning (RL) is a vital post-training strategy to overcome these limits, yet current VLA-RL methods, including group-based optimization approaches, are crippled by severe reward sparsity. Relying on binary success indicators wastes valuable information in failed trajectories, resulting in low training efficiency. To solve this, we propose Self-Referential Policy Optimization (SRPO), a novel VLA-RL framework. SRPO eliminates the need for external demonstrations or manual reward engineering by leveraging the model's own successful trajectories, generated within the current training batch, as a self-reference. This allows us to assign a progress-wise reward to failed attempts. A core innovation is the use of latent world representations to measure behavioral progress robustly. Instead of relying on raw pixels or requiring domain-specific fine-tuning, we utilize the compressed, transferable encodings from a world model's latent space. These representations naturally capture progress patterns across environments, enabling accurate, generalized trajectory comparison. Empirical evaluations on the LIBERO benchmark demonstrate SRPO's efficiency and effectiveness. Starting from a supervised baseline with 48.9% success, SRPO achieves a new state-of-the-art success rate of 99.2% in just 200 RL steps, representing a 103% relative improvement without any extra supervision. Furthermore, SRPO shows substantial robustness, achieving a 167% performance improvement on the LIBERO-Plus benchmark.
FlowletFormer: Network Behavioral Semantic Aware Pre-training Model for Traffic Classification
Aug 27, 2025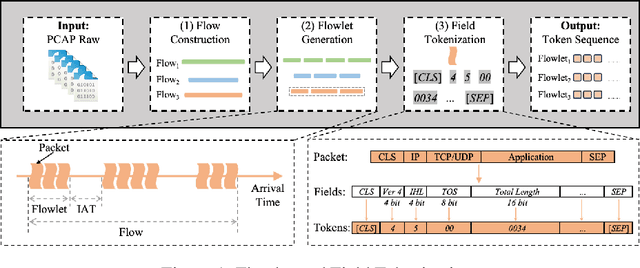
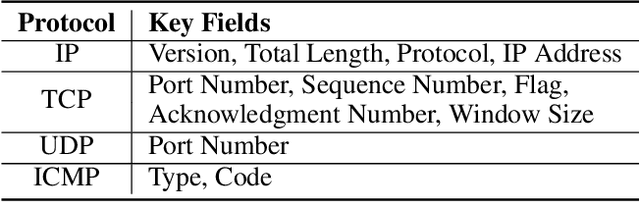
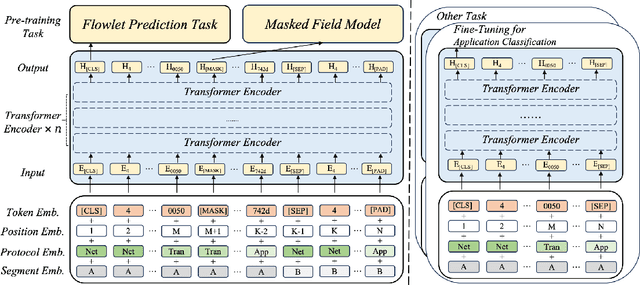
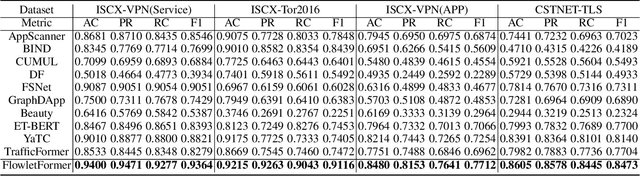
Network traffic classification using pre-training models has shown promising results, but existing methods struggle to capture packet structural characteristics, flow-level behaviors, hierarchical protocol semantics, and inter-packet contextual relationships. To address these challenges, we propose FlowletFormer, a BERT-based pre-training model specifically designed for network traffic analysis. FlowletFormer introduces a Coherent Behavior-Aware Traffic Representation Model for segmenting traffic into semantically meaningful units, a Protocol Stack Alignment-Based Embedding Layer to capture multilayer protocol semantics, and Field-Specific and Context-Aware Pretraining Tasks to enhance both inter-packet and inter-flow learning. Experimental results demonstrate that FlowletFormer significantly outperforms existing methods in the effectiveness of traffic representation, classification accuracy, and few-shot learning capability. Moreover, by effectively integrating domain-specific network knowledge, FlowletFormer shows better comprehension of the principles of network transmission (e.g., stateful connections of TCP), providing a more robust and trustworthy framework for traffic analysis.
Subspecialty-Specific Foundation Model for Intelligent Gastrointestinal Pathology
May 28, 2025Gastrointestinal (GI) diseases represent a clinically significant burden, necessitating precise diagnostic approaches to optimize patient outcomes. Conventional histopathological diagnosis, heavily reliant on the subjective interpretation of pathologists, suffers from limited reproducibility and diagnostic variability. To overcome these limitations and address the lack of pathology-specific foundation models for GI diseases, we develop Digepath, a specialized foundation model for GI pathology. Our framework introduces a dual-phase iterative optimization strategy combining pretraining with fine-screening, specifically designed to address the detection of sparsely distributed lesion areas in whole-slide images. Digepath is pretrained on more than 353 million image patches from over 200,000 hematoxylin and eosin-stained slides of GI diseases. It attains state-of-the-art performance on 33 out of 34 tasks related to GI pathology, including pathological diagnosis, molecular prediction, gene mutation prediction, and prognosis evaluation, particularly in diagnostically ambiguous cases and resolution-agnostic tissue classification.We further translate the intelligent screening module for early GI cancer and achieve near-perfect 99.6% sensitivity across 9 independent medical institutions nationwide. The outstanding performance of Digepath highlights its potential to bridge critical gaps in histopathological practice. This work not only advances AI-driven precision pathology for GI diseases but also establishes a transferable paradigm for other pathology subspecialties.
R-Meshfusion: Reinforcement Learning Powered Sparse-View Mesh Reconstruction with Diffusion Priors
Apr 16, 2025Mesh reconstruction from multi-view images is a fundamental problem in computer vision, but its performance degrades significantly under sparse-view conditions, especially in unseen regions where no ground-truth observations are available. While recent advances in diffusion models have demonstrated strong capabilities in synthesizing novel views from limited inputs, their outputs often suffer from visual artifacts and lack 3D consistency, posing challenges for reliable mesh optimization. In this paper, we propose a novel framework that leverages diffusion models to enhance sparse-view mesh reconstruction in a principled and reliable manner. To address the instability of diffusion outputs, we propose a Consensus Diffusion Module that filters unreliable generations via interquartile range (IQR) analysis and performs variance-aware image fusion to produce robust pseudo-supervision. Building on this, we design an online reinforcement learning strategy based on the Upper Confidence Bound (UCB) to adaptively select the most informative viewpoints for enhancement, guided by diffusion loss. Finally, the fused images are used to jointly supervise a NeRF-based model alongside sparse-view ground truth, ensuring consistency across both geometry and appearance. Extensive experiments demonstrate that our method achieves significant improvements in both geometric quality and rendering quality.
MCBlock: Boosting Neural Radiance Field Training Speed by MCTS-based Dynamic-Resolution Ray Sampling
Apr 14, 2025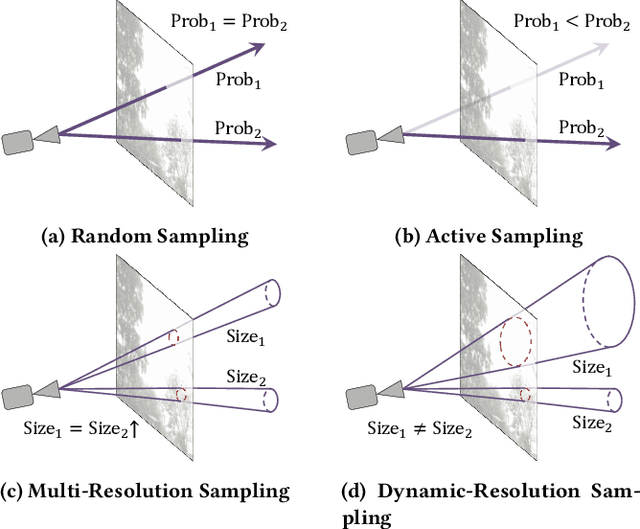
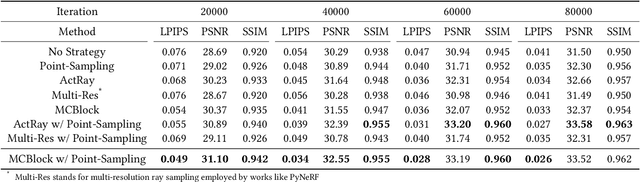


Neural Radiance Field (NeRF) is widely known for high-fidelity novel view synthesis. However, even the state-of-the-art NeRF model, Gaussian Splatting, requires minutes for training, far from the real-time performance required by multimedia scenarios like telemedicine. One of the obstacles is its inefficient sampling, which is only partially addressed by existing works. Existing point-sampling algorithms uniformly sample simple-texture regions (easy to fit) and complex-texture regions (hard to fit), while existing ray-sampling algorithms sample these regions all in the finest granularity (i.e. the pixel level), both wasting GPU training resources. Actually, regions with different texture intensities require different sampling granularities. To this end, we propose a novel dynamic-resolution ray-sampling algorithm, MCBlock, which employs Monte Carlo Tree Search (MCTS) to partition each training image into pixel blocks with different sizes for active block-wise training. Specifically, the trees are initialized according to the texture of training images to boost the initialization speed, and an expansion/pruning module dynamically optimizes the block partition. MCBlock is implemented in Nerfstudio, an open-source toolset, and achieves a training acceleration of up to 2.33x, surpassing other ray-sampling algorithms. We believe MCBlock can apply to any cone-tracing NeRF model and contribute to the multimedia community.
PromptMobile: Efficient Promptus for Low Bandwidth Mobile Video Streaming
Mar 20, 2025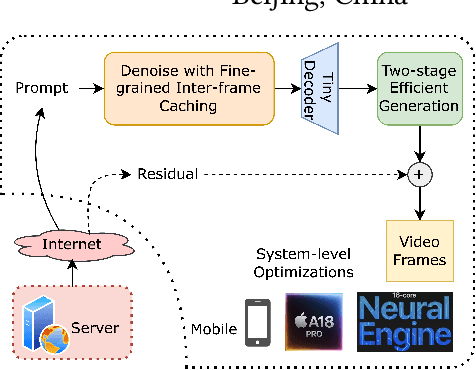
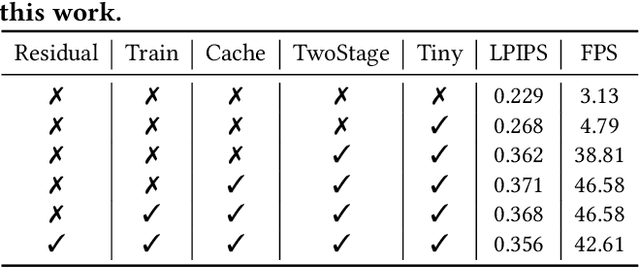
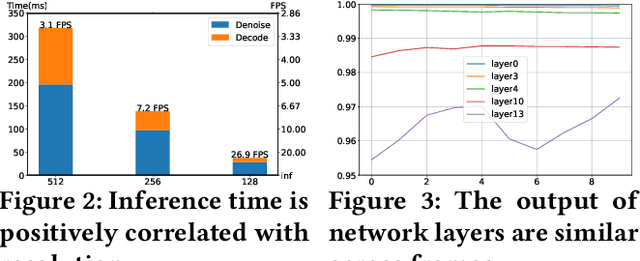

Traditional video compression algorithms exhibit significant quality degradation at extremely low bitrates. Promptus emerges as a new paradigm for video streaming, substantially cutting down the bandwidth essential for video streaming. However, Promptus is computationally intensive and can not run in real-time on mobile devices. This paper presents PromptMobile, an efficient acceleration framework tailored for on-device Promptus. Specifically, we propose (1) a two-stage efficient generation framework to reduce computational cost by 8.1x, (2) a fine-grained inter-frame caching to reduce redundant computations by 16.6\%, (3) system-level optimizations to further enhance efficiency. The evaluations demonstrate that compared with the original Promptus, PromptMobile achieves a 13.6x increase in image generation speed. Compared with other streaming methods, PromptMobile achives an average LPIPS improvement of 0.016 (compared with H.265), reducing 60\% of severely distorted frames (compared to VQGAN).
A Minimalist Example of Edge-of-Stability and Progressive Sharpening
Mar 04, 2025



Recent advances in deep learning optimization have unveiled two intriguing phenomena under large learning rates: Edge of Stability (EoS) and Progressive Sharpening (PS), challenging classical Gradient Descent (GD) analyses. Current research approaches, using either generalist frameworks or minimalist examples, face significant limitations in explaining these phenomena. This paper advances the minimalist approach by introducing a two-layer network with a two-dimensional input, where one dimension is relevant to the response and the other is irrelevant. Through this model, we rigorously prove the existence of progressive sharpening and self-stabilization under large learning rates, and establish non-asymptotic analysis of the training dynamics and sharpness along the entire GD trajectory. Besides, we connect our minimalist example to existing works by reconciling the existence of a well-behaved ``stable set" between minimalist and generalist analyses, and extending the analysis of Gradient Flow Solution sharpness to our two-dimensional input scenario. These findings provide new insights into the EoS phenomenon from both parameter and input data distribution perspectives, potentially informing more effective optimization strategies in deep learning practice.
COSMOS: A Hybrid Adaptive Optimizer for Memory-Efficient Training of LLMs
Feb 26, 2025Large Language Models (LLMs) have demonstrated remarkable success across various domains, yet their optimization remains a significant challenge due to the complex and high-dimensional loss landscapes they inhabit. While adaptive optimizers such as AdamW are widely used, they suffer from critical limitations, including an inability to capture interdependencies between coordinates and high memory consumption. Subsequent research, exemplified by SOAP, attempts to better capture coordinate interdependence but incurs greater memory overhead, limiting scalability for massive LLMs. An alternative approach aims to reduce memory consumption through low-dimensional projection, but this leads to substantial approximation errors, resulting in less effective optimization (e.g., in terms of per-token efficiency). In this paper, we propose COSMOS, a novel hybrid optimizer that leverages the varying importance of eigensubspaces in the gradient matrix to achieve memory efficiency without compromising optimization performance. The design of COSMOS is motivated by our empirical insights and practical considerations. Specifically, COSMOS applies SOAP to the leading eigensubspace, which captures the primary optimization dynamics, and MUON to the remaining eigensubspace, which is less critical but computationally expensive to handle with SOAP. This hybrid strategy significantly reduces memory consumption while maintaining robust optimization performance, making it particularly suitable for massive LLMs. Numerical experiments on various datasets and transformer architectures are provided to demonstrate the effectiveness of COSMOS. Our code is available at https://github.com/lliu606/COSMOS.
$R^2$-Mesh: Reinforcement Learning Powered Mesh Reconstruction via Geometry and Appearance Refinement
Aug 19, 2024



Mesh reconstruction based on Neural Radiance Fields (NeRF) is popular in a variety of applications such as computer graphics, virtual reality, and medical imaging due to its efficiency in handling complex geometric structures and facilitating real-time rendering. However, existing works often fail to capture fine geometric details accurately and struggle with optimizing rendering quality. To address these challenges, we propose a novel algorithm that progressively generates and optimizes meshes from multi-view images. Our approach initiates with the training of a NeRF model to establish an initial Signed Distance Field (SDF) and a view-dependent appearance field. Subsequently, we iteratively refine the SDF through a differentiable mesh extraction method, continuously updating both the vertex positions and their connectivity based on the loss from mesh differentiable rasterization, while also optimizing the appearance representation. To further leverage high-fidelity and detail-rich representations from NeRF, we propose an online-learning strategy based on Upper Confidence Bound (UCB) to enhance viewpoints by adaptively incorporating images rendered by the initial NeRF model into the training dataset. Through extensive experiments, we demonstrate that our method delivers highly competitive and robust performance in both mesh rendering quality and geometric quality.