 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTubeR: Tube-Transformer for Action Detection
Apr 09, 2021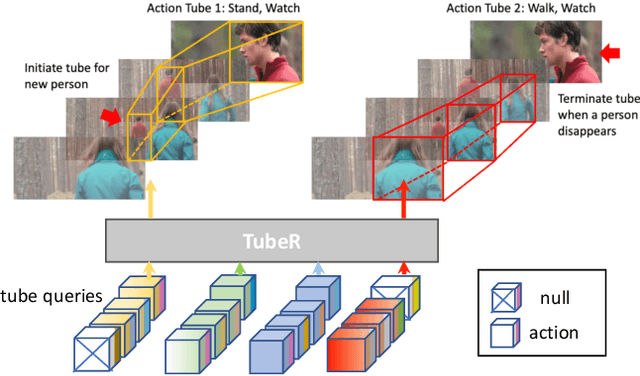
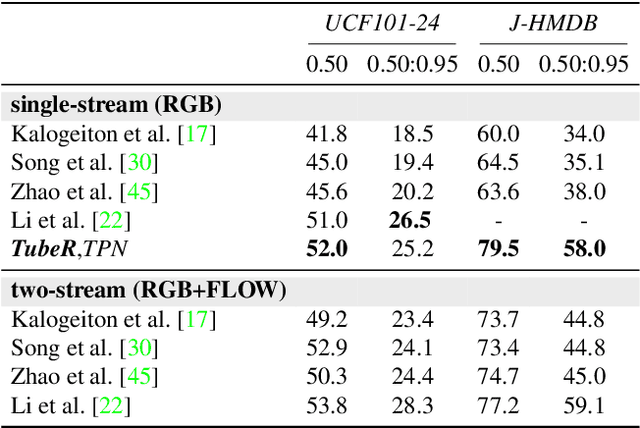
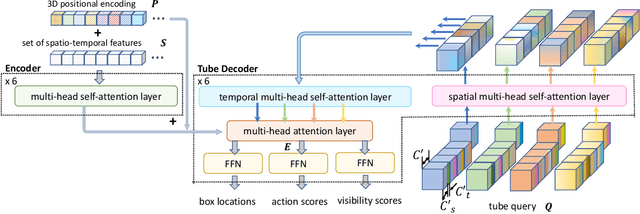

In this paper, we propose TubeR: the first transformer based network for end-to-end action detection, with an encoder and decoder optimized for modeling action tubes with variable lengths and aspect ratios. TubeR does not rely on hand-designed tube structures, automatically links predicted action boxes over time and learns a set of tube queries related to actions. By learning action tube embeddings, TubeR predicts more precise action tubes with flexible spatial and temporal extents. Our experiments demonstrate TubeR achieves state-of-the-art among single-stream methods on UCF101-24 and J-HMDB. TubeR outperforms existing one-model methods on AVA and is even competitive with the two-model methods. Moreover, we observe TubeR has the potential on tracking actors with different actions, which will foster future research in long-range video understanding.