 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePhotorealistic Image Synthesis for Object Instance Detection
Feb 09, 2019
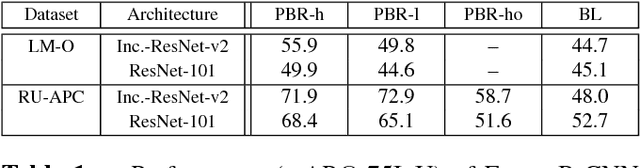


We present an approach to synthesize highly photorealistic images of 3D object models, which we use to train a convolutional neural network for detecting the objects in real images. The proposed approach has three key ingredients: (1) 3D object models are rendered in 3D models of complete scenes with realistic materials and lighting, (2) plausible geometric configuration of objects and cameras in a scene is generated using physics simulations, and (3) high photorealism of the synthesized images achieved by physically based rendering. When trained on images synthesized by the proposed approach, the Faster R-CNN object detector achieves a 24% absolute improvement of mAP@.75IoU on Rutgers APC and 11% on LineMod-Occluded datasets, compared to a baseline where the training images are synthesized by rendering object models on top of random photographs. This work is a step towards being able to effectively train object detectors without capturing or annotating any real images. A dataset of 600K synthetic images with ground truth annotations for various computer vision tasks will be released on the project website: thodan.github.io/objectsynth.