 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLlamaLens: Specialized Multilingual LLM for Analyzing News and Social Media Content
Paper and Code
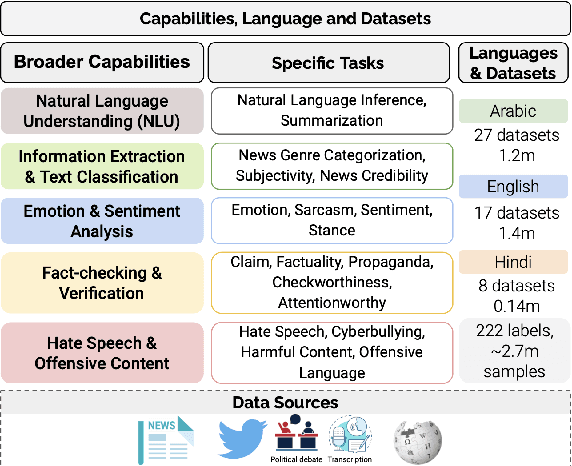
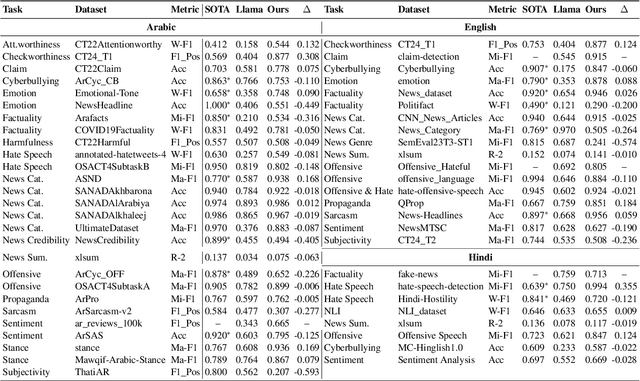
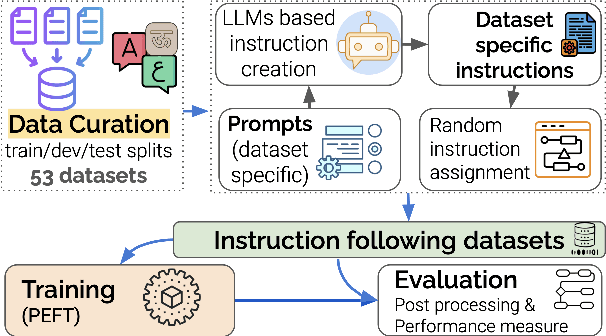
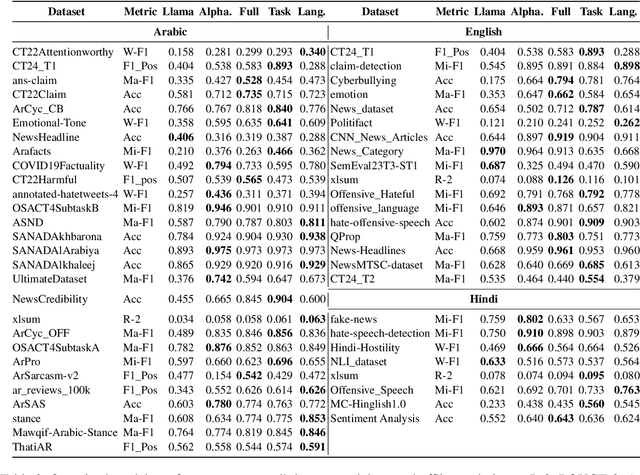
Large Language Models (LLMs) have demonstrated remarkable success as general-purpose task solvers across various fields, including NLP, healthcare, finance, and law. However, their capabilities remain limited when addressing domain-specific problems, particularly in downstream NLP tasks. Research has shown that models fine-tuned on instruction-based downstream NLP datasets outperform those that are not fine-tuned. While most efforts in this area have primarily focused on resource-rich languages like English and broad domains, little attention has been given to multilingual settings and specific domains. To address this gap, this study focuses on developing a specialized LLM, LlamaLens, for analyzing news and social media content in a multilingual context. To the best of our knowledge, this is the first attempt to tackle both domain specificity and multilinguality, with a particular focus on news and social media. Our experimental setup includes 19 tasks, represented by 52 datasets covering Arabic, English, and Hindi. We demonstrate that LlamaLens outperforms the current state-of-the-art (SOTA) on 16 testing sets, and achieves comparable performance on 10 sets. We make the models and resources publicly available for the research community.(https://huggingface.co/QCRI)