 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring the Potential of the Large Language Models in Identifying Misleading News Headlines
May 06, 2024

In the digital age, the prevalence of misleading news headlines poses a significant challenge to information integrity, necessitating robust detection mechanisms. This study explores the efficacy of Large Language Models (LLMs) in identifying misleading versus non-misleading news headlines. Utilizing a dataset of 60 articles, sourced from both reputable and questionable outlets across health, science & tech, and business domains, we employ three LLMs- ChatGPT-3.5, ChatGPT-4, and Gemini-for classification. Our analysis reveals significant variance in model performance, with ChatGPT-4 demonstrating superior accuracy, especially in cases with unanimous annotator agreement on misleading headlines. The study emphasizes the importance of human-centered evaluation in developing LLMs that can navigate the complexities of misinformation detection, aligning technical proficiency with nuanced human judgment. Our findings contribute to the discourse on AI ethics, emphasizing the need for models that are not only technically advanced but also ethically aligned and sensitive to the subtleties of human interpretation.
Examining the Role of Clickbait Headlines to Engage Readers with Reliable Health-related Information
Nov 25, 2019Clickbait headlines are frequently used to attract readers to read articles. Although this headline type has turned out to be a technique to engage readers with misleading items, it is still unknown whether the technique can be used to attract readers to reliable pieces. This study takes the opportunity to test its efficacy to engage readers with reliable health articles. A set of online surveys would be conducted to test readers' engagement with and perception about clickbait headlines with reliable articles. After that, we would design an automation system to generate clickabit headlines to maximize user engagement.
Diving Deep into Clickbaits: Who Use Them to What Extents in Which Topics with What Effects?
Mar 28, 2017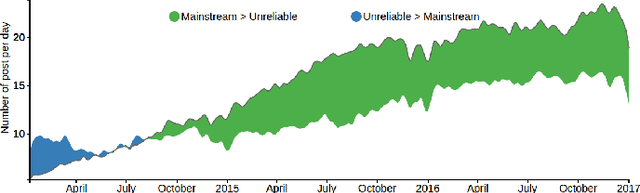

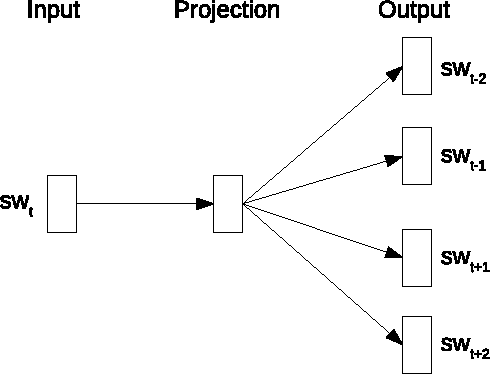
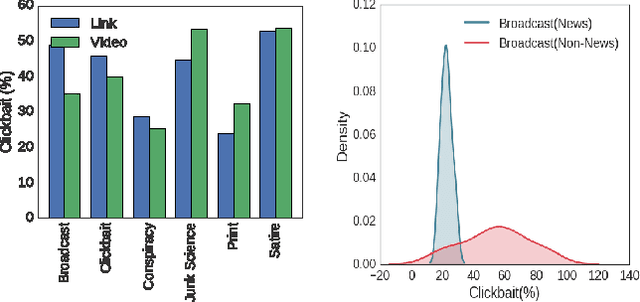
The use of alluring headlines (clickbait) to tempt the readers has become a growing practice nowadays. For the sake of existence in the highly competitive media industry, most of the on-line media including the mainstream ones, have started following this practice. Although the wide-spread practice of clickbait makes the reader's reliability on media vulnerable, a large scale analysis to reveal this fact is still absent. In this paper, we analyze 1.67 million Facebook posts created by 153 media organizations to understand the extent of clickbait practice, its impact and user engagement by using our own developed clickbait detection model. The model uses distributed sub-word embeddings learned from a large corpus. The accuracy of the model is 98.3%. Powered with this model, we further study the distribution of topics in clickbait and non-clickbait contents.