 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAraDiCE: Benchmarks for Dialectal and Cultural Capabilities in LLMs
Sep 17, 2024Arabic, with its rich diversity of dialects, remains significantly underrepresented in Large Language Models, particularly in dialectal variations. We address this gap by introducing seven synthetic datasets in dialects alongside Modern Standard Arabic (MSA), created using Machine Translation (MT) combined with human post-editing. We present AraDiCE, a benchmark for Arabic Dialect and Cultural Evaluation. We evaluate LLMs on dialect comprehension and generation, focusing specifically on low-resource Arabic dialects. Additionally, we introduce the first-ever fine-grained benchmark designed to evaluate cultural awareness across the Gulf, Egypt, and Levant regions, providing a novel dimension to LLM evaluation. Our findings demonstrate that while Arabic-specific models like Jais and AceGPT outperform multilingual models on dialectal tasks, significant challenges persist in dialect identification, generation, and translation. This work contributes ~45K post-edited samples, a cultural benchmark, and highlights the importance of tailored training to improve LLM performance in capturing the nuances of diverse Arabic dialects and cultural contexts. We will release the dialectal translation models and benchmarks curated in this study.
Arabic Diacritics in the Wild: Exploiting Opportunities for Improved Diacritization
Jun 09, 2024
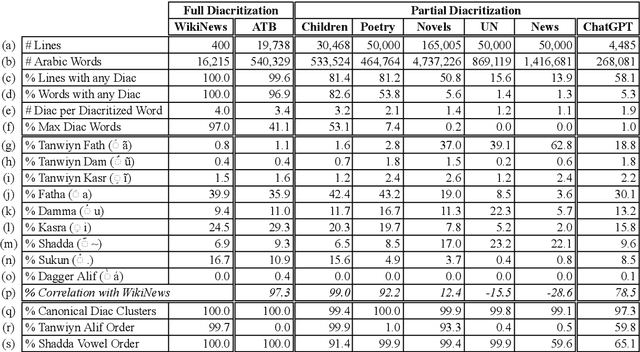


The widespread absence of diacritical marks in Arabic text poses a significant challenge for Arabic natural language processing (NLP). This paper explores instances of naturally occurring diacritics, referred to as "diacritics in the wild," to unveil patterns and latent information across six diverse genres: news articles, novels, children's books, poetry, political documents, and ChatGPT outputs. We present a new annotated dataset that maps real-world partially diacritized words to their maximal full diacritization in context. Additionally, we propose extensions to the analyze-and-disambiguate approach in Arabic NLP to leverage these diacritics, resulting in notable improvements. Our contributions encompass a thorough analysis, valuable datasets, and an extended diacritization algorithm. We release our code and datasets as open source.