 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNativQA: Multilingual Culturally-Aligned Natural Query for LLMs
Jul 13, 2024Natural Question Answering (QA) datasets play a crucial role in developing and evaluating the capabilities of large language models (LLMs), ensuring their effective usage in real-world applications. Despite the numerous QA datasets that have been developed, there is a notable lack of region-specific datasets generated by native users in their own languages. This gap hinders the effective benchmarking of LLMs for regional and cultural specificities. In this study, we propose a scalable framework, NativQA, to seamlessly construct culturally and regionally aligned QA datasets in native languages, for LLM evaluation and tuning. Moreover, to demonstrate the efficacy of the proposed framework, we designed a multilingual natural QA dataset, MultiNativQA, consisting of ~72K QA pairs in seven languages, ranging from high to extremely low resource, based on queries from native speakers covering 18 topics. We benchmark the MultiNativQA dataset with open- and closed-source LLMs. We made both the framework NativQA and MultiNativQA dataset publicly available for the community. (https://nativqa.gitlab.io)
Investigation of Ensemble features of Self-Supervised Pretrained Models for Automatic Speech Recognition
Jun 11, 2022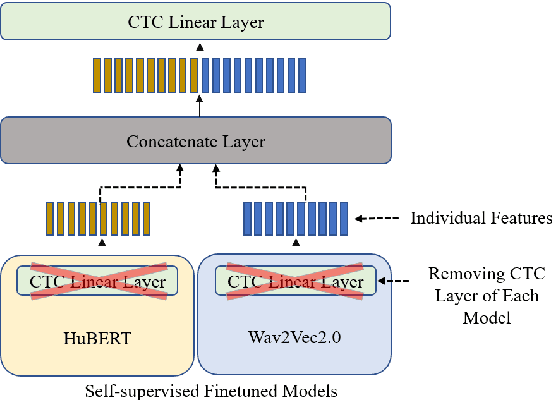
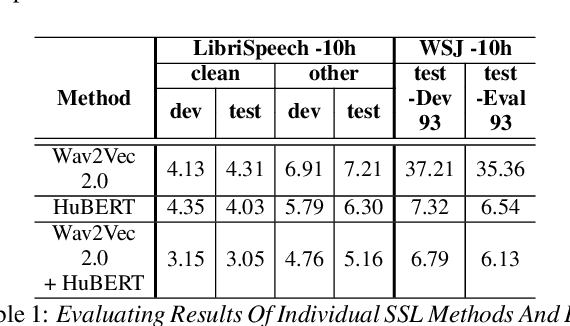
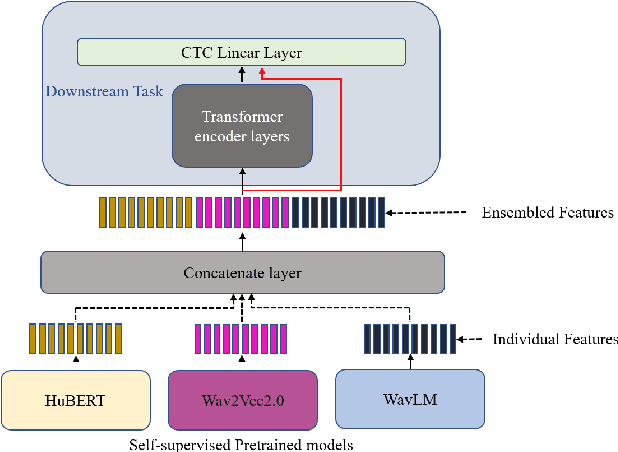
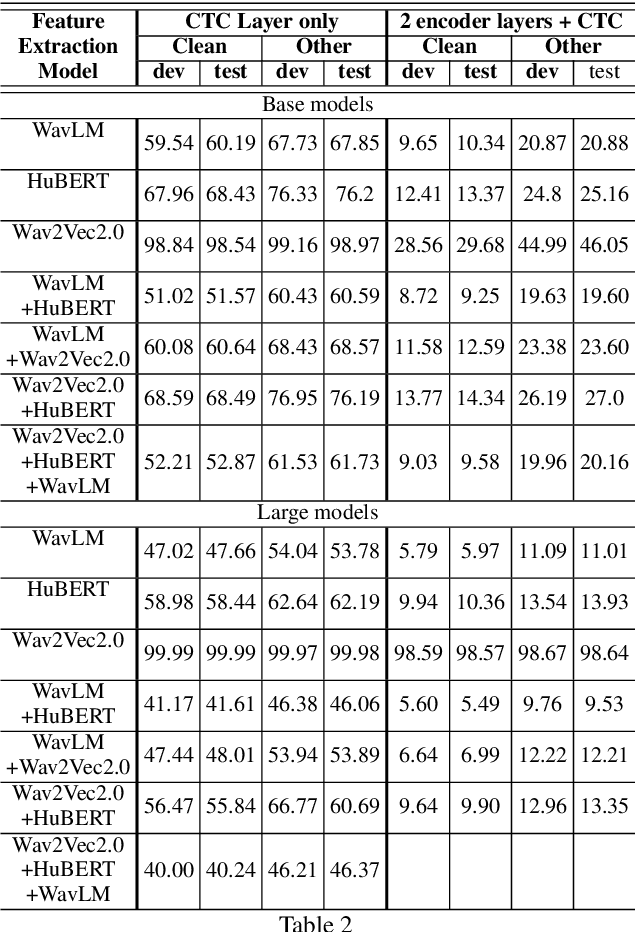
Self-supervised learning (SSL) based models have been shown to generate powerful representations that can be used to improve the performance of downstream speech tasks. Several state-of-the-art SSL models are available, and each of these models optimizes a different loss which gives rise to the possibility of their features being complementary. This paper proposes using an ensemble of such SSL representations and models, which exploits the complementary nature of the features extracted by the various pretrained models. We hypothesize that this results in a richer feature representation and shows results for the ASR downstream task. To this end, we use three SSL models that have shown excellent results on ASR tasks, namely HuBERT, Wav2vec2.0, and WaveLM. We explore the ensemble of models fine-tuned for the ASR task and the ensemble of features using the embeddings obtained from the pre-trained models for a downstream ASR task. We get improved performance over individual models and pre-trained features using Librispeech(100h) and WSJ dataset for the downstream tasks.