 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInvestigation of Ensemble features of Self-Supervised Pretrained Models for Automatic Speech Recognition
Paper and Code
Jun 11, 2022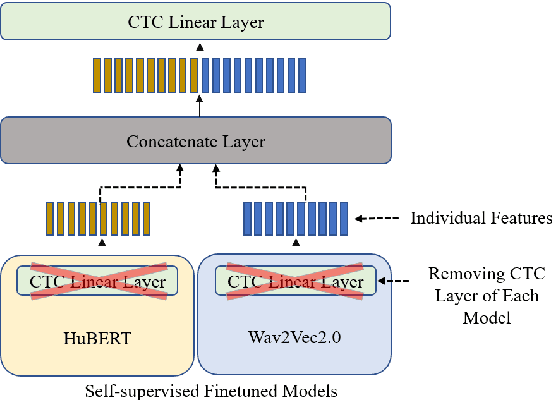
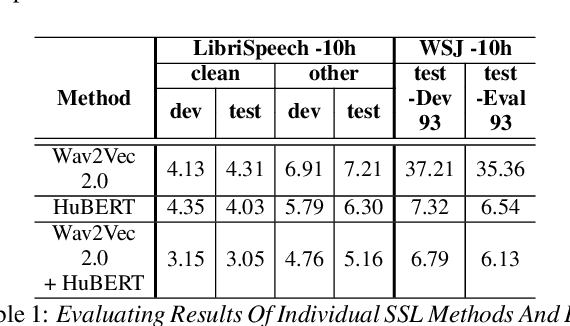
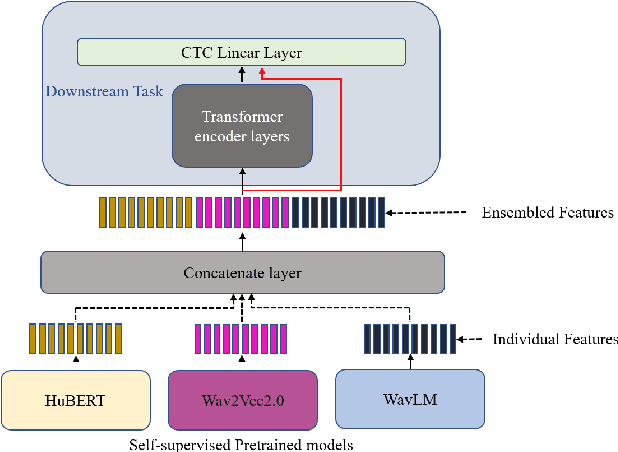
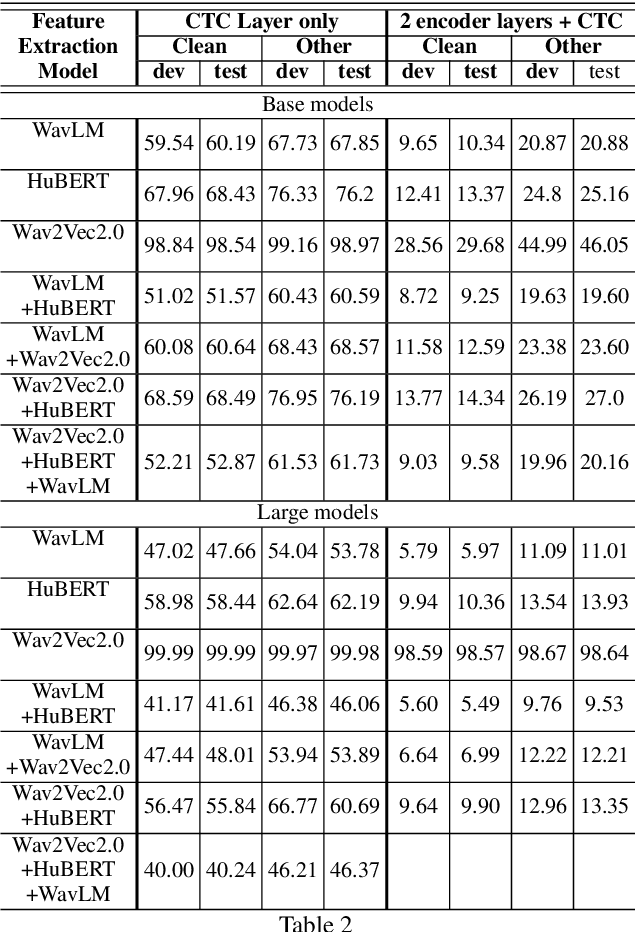
Self-supervised learning (SSL) based models have been shown to generate powerful representations that can be used to improve the performance of downstream speech tasks. Several state-of-the-art SSL models are available, and each of these models optimizes a different loss which gives rise to the possibility of their features being complementary. This paper proposes using an ensemble of such SSL representations and models, which exploits the complementary nature of the features extracted by the various pretrained models. We hypothesize that this results in a richer feature representation and shows results for the ASR downstream task. To this end, we use three SSL models that have shown excellent results on ASR tasks, namely HuBERT, Wav2vec2.0, and WaveLM. We explore the ensemble of models fine-tuned for the ASR task and the ensemble of features using the embeddings obtained from the pre-trained models for a downstream ASR task. We get improved performance over individual models and pre-trained features using Librispeech(100h) and WSJ dataset for the downstream tasks.