 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThatiAR: Subjectivity Detection in Arabic News Sentences
Jun 08, 2024
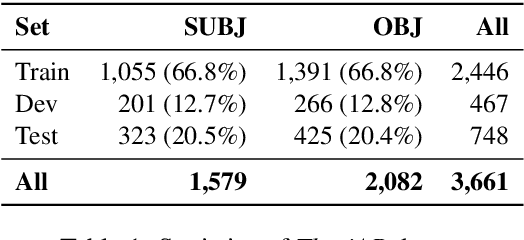
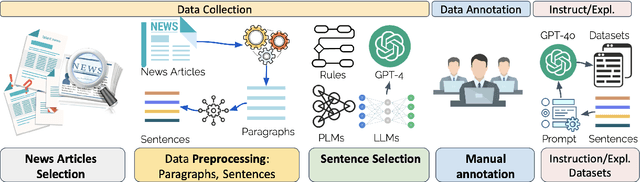
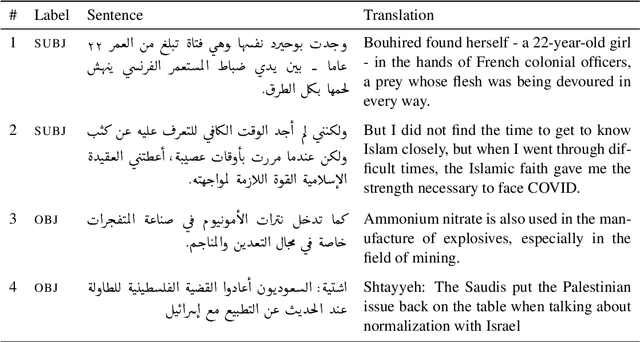
Detecting subjectivity in news sentences is crucial for identifying media bias, enhancing credibility, and combating misinformation by flagging opinion-based content. It provides insights into public sentiment, empowers readers to make informed decisions, and encourages critical thinking. While research has developed methods and systems for this purpose, most efforts have focused on English and other high-resourced languages. In this study, we present the first large dataset for subjectivity detection in Arabic, consisting of ~3.6K manually annotated sentences, and GPT-4o based explanation. In addition, we included instructions (both in English and Arabic) to facilitate LLM based fine-tuning. We provide an in-depth analysis of the dataset, annotation process, and extensive benchmark results, including PLMs and LLMs. Our analysis of the annotation process highlights that annotators were strongly influenced by their political, cultural, and religious backgrounds, especially at the beginning of the annotation process. The experimental results suggest that LLMs with in-context learning provide better performance. We aim to release the dataset and resources for the community.