 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Track Anything
Nov 28, 2024Segment Anything Model 2 (SAM 2) has emerged as a powerful tool for video object segmentation and tracking anything. Key components of SAM 2 that drive the impressive video object segmentation performance include a large multistage image encoder for frame feature extraction and a memory mechanism that stores memory contexts from past frames to help current frame segmentation. The high computation complexity of multistage image encoder and memory module has limited its applications in real-world tasks, e.g., video object segmentation on mobile devices. To address this limitation, we propose EfficientTAMs, lightweight track anything models that produce high-quality results with low latency and model size. Our idea is based on revisiting the plain, nonhierarchical Vision Transformer (ViT) as an image encoder for video object segmentation, and introducing an efficient memory module, which reduces the complexity for both frame feature extraction and memory computation for current frame segmentation. We take vanilla lightweight ViTs and efficient memory module to build EfficientTAMs, and train the models on SA-1B and SA-V datasets for video object segmentation and track anything tasks. We evaluate on multiple video segmentation benchmarks including semi-supervised VOS and promptable video segmentation, and find that our proposed EfficientTAM with vanilla ViT perform comparably to SAM 2 model (HieraB+SAM 2) with ~2x speedup on A100 and ~2.4x parameter reduction. On segment anything image tasks, our EfficientTAMs also perform favorably over original SAM with ~20x speedup on A100 and ~20x parameter reduction. On mobile devices such as iPhone 15 Pro Max, our EfficientTAMs can run at ~10 FPS for performing video object segmentation with reasonable quality, highlighting the capability of small models for on-device video object segmentation applications.
Enhancing Cryptocurrency Market Forecasting: Advanced Machine Learning Techniques and Industrial Engineering Contributions
Oct 18, 2024Cryptocurrencies, as decentralized digital assets, have experienced rapid growth and adoption, with over 23,000 cryptocurrencies and a market capitalization nearing \$1.1 trillion (about \$3,400 per person in the US) as of 2023. This dynamic market presents significant opportunities and risks, highlighting the need for accurate price prediction models to manage volatility. This chapter comprehensively reviews machine learning (ML) techniques applied to cryptocurrency price prediction from 2014 to 2024. We explore various ML algorithms, including linear models, tree-based approaches, and advanced deep learning architectures such as transformers and large language models. Additionally, we examine the role of sentiment analysis in capturing market sentiment from textual data like social media posts and news articles to anticipate price fluctuations. With expertise in optimizing complex systems and processes, industrial engineers are pivotal in enhancing these models. They contribute by applying principles of process optimization, efficiency, and risk mitigation to improve computational performance and data management. This chapter highlights the evolving landscape of cryptocurrency price prediction, the integration of emerging technologies, and the significant role of industrial engineers in refining predictive models. By addressing current limitations and exploring future research directions, this chapter aims to advance the development of more accurate and robust prediction systems, supporting better-informed investment decisions and more stable market behavior.
Ethical AI for Social Good
Jul 14, 2021

The concept of AI for Social Good(AI4SG) is gaining momentum in both information societies and the AI community. Through all the advancement of AI-based solutions, it can solve societal issues effectively. To date, however, there is only a rudimentary grasp of what constitutes AI socially beneficial in principle, what constitutes AI4SG in reality, and what are the policies and regulations needed to ensure it. This paper fills the vacuum by addressing the ethical aspects that are critical for future AI4SG efforts. Some of these characteristics are new to AI, while others have greater importance due to its usage.
Interpretable Multi-Head Self-Attention model for Sarcasm Detection in social media
Jan 14, 2021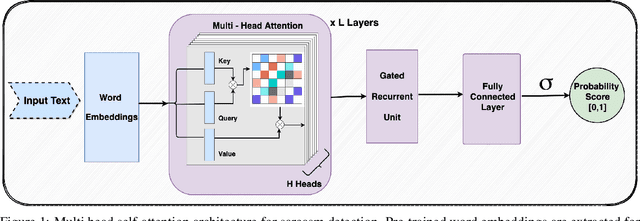

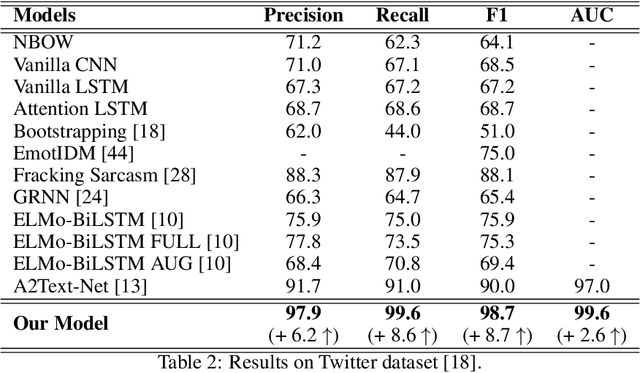
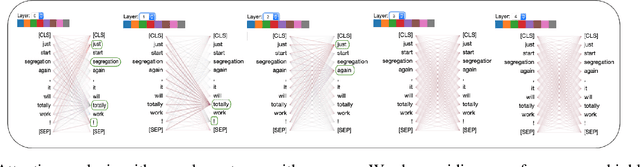
Sarcasm is a linguistic expression often used to communicate the opposite of what is said, usually something that is very unpleasant with an intention to insult or ridicule. Inherent ambiguity in sarcastic expressions, make sarcasm detection very difficult. In this work, we focus on detecting sarcasm in textual conversations from various social networking platforms and online media. To this end, we develop an interpretable deep learning model using multi-head self-attention and gated recurrent units. Multi-head self-attention module aids in identifying crucial sarcastic cue-words from the input, and the recurrent units learn long-range dependencies between these cue-words to better classify the input text. We show the effectiveness of our approach by achieving state-of-the-art results on multiple datasets from social networking platforms and online media. Models trained using our proposed approach are easily interpretable and enable identifying sarcastic cues in the input text which contribute to the final classification score. We visualize the learned attention weights on few sample input texts to showcase the effectiveness and interpretability of our model.
Forecasting the Success of Television Series using Machine Learning
Oct 18, 2019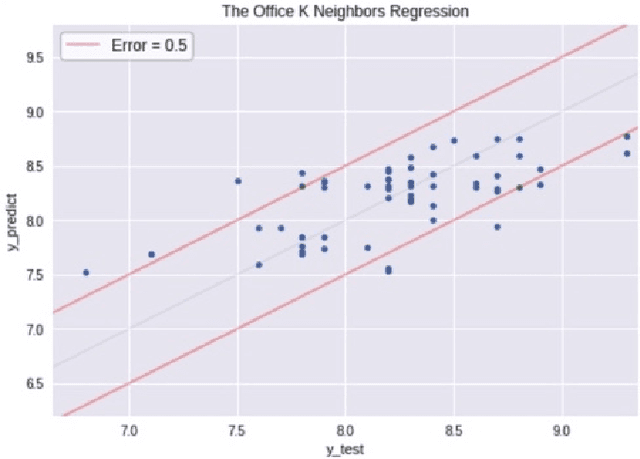
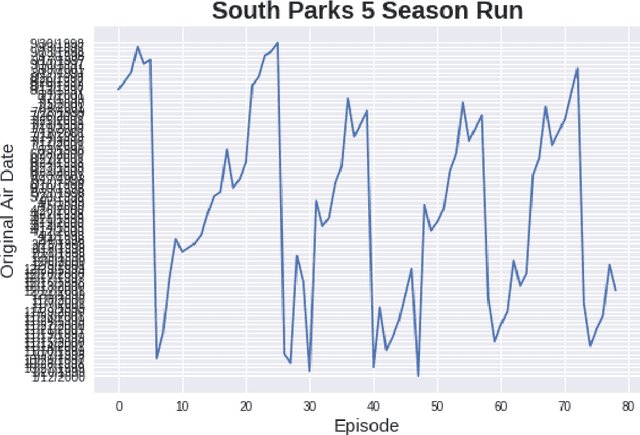
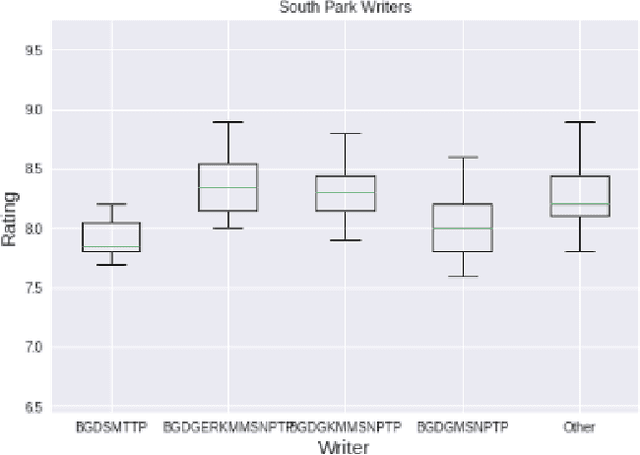
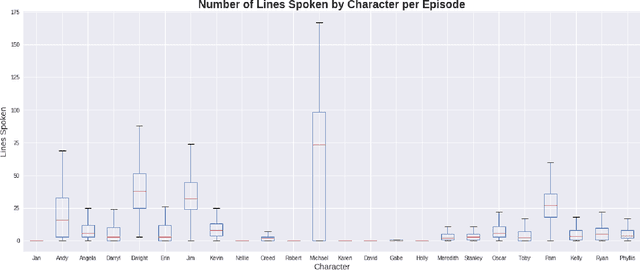
Television is an ever-evolving multi billion dollar industry. The success of a television show in an increasingly technological society is a vast multi-variable formula. The art of success is not just something that happens, but is studied, replicated, and applied. Hollywood can be unpredictable regarding success, as many movies and sitcoms that are hyped up and promise to be a hit end up being box office failures and complete disappointments. In current studies, linguistic exploration is being performed on the relationship between Television series and target community of viewers. Having a decision support system that can display sound and predictable results would be needed to build confidence in the investment of a new TV series. The models presented in this study use data to study and determine what makes a sitcom successful. In this paper, we use descriptive and predictive modeling techniques to assess the continuing success of television comedies: The Office, Big Bang Theory, Arrested Development, Scrubs, and South Park. The factors that are tested for statistical significance on episode ratings are character presence, director, and writer. These statistics show that while characters are indeed crucial to the shows themselves, the creation and direction of the shows pose implication upon the ratings and therefore the success of the shows. We use machine learning based forecasting models to accurately predict the success of shows. The models represent a baseline to understanding the success of a television show and how producers can increase the success of current television shows or utilize this data in the creation of future shows. Due to the many factors that go into a series, the empirical analysis in this work shows that there is no one-fits-all model to forecast the rating or success of a television show.
Supervised Machine Learning based Ensemble Model for Accurate Prediction of Type 2 Diabetes
Oct 18, 2019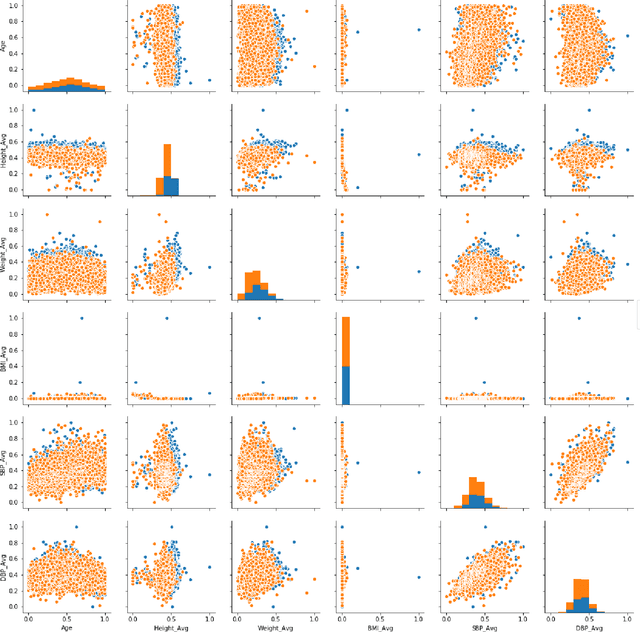
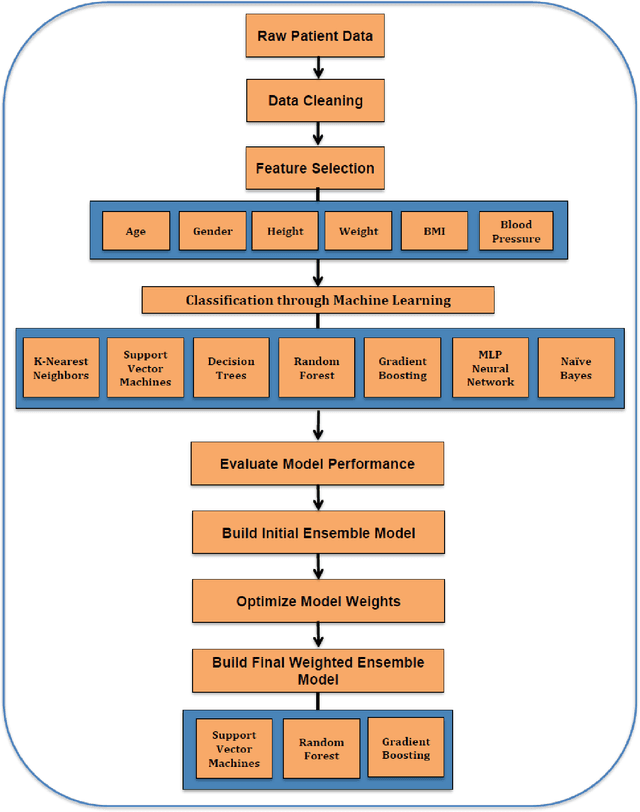
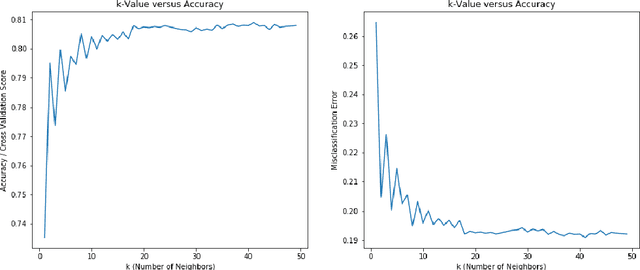
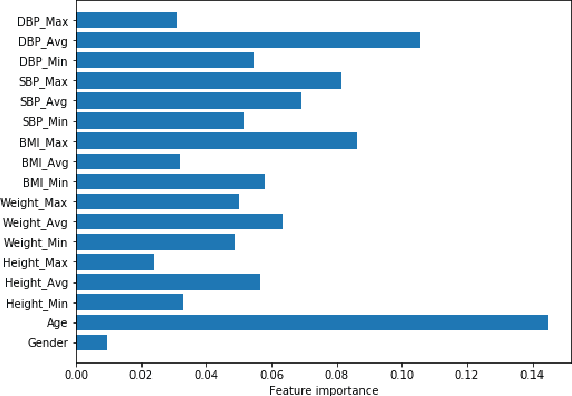
According to the American Diabetes Association(ADA), 30.3 million people in the United States have diabetes, but only 7.2 million may be undiagnosed and unaware of their condition. Type 2 diabetes is usually diagnosed for most patients later on in life whereas the less common Type 1 diabetes is diagnosed early on in life. People can live healthy and happy lives while living with diabetes, but early detection produces a better overall outcome on most patient's health. Thus, to test the accurate prediction of Type 2 diabetes, we use the patients' information from an electronic health records company called Practice Fusion, which has about 10,000 patient records from 2009 to 2012. This data contains individual key biometrics, including age, diastolic and systolic blood pressure, gender, height, and weight. We use this data on popular machine learning algorithms and for each algorithm, we evaluate the performance of every model based on their classification accuracy, precision, sensitivity, specificity/recall, negative predictive value, and F1 score. In our study, we find that all algorithms other than Naive Bayes suffered from very low precision. Hence, we take a step further and incorporate all the algorithms into a weighted average or soft voting ensemble model where each algorithm will count towards a majority vote towards the decision outcome of whether a patient has diabetes or not. The accuracy of the Ensemble model on Practice Fusion is 85\%, by far our ensemble approach is new in this space. We firmly believe that the weighted average ensemble model not only performed well in overall metrics but also helped to recover wrong predictions and aid in accurate prediction of Type 2 diabetes. Our accurate novel model can be used as an alert for the patients to seek medical evaluation in time.
DeepFork: Supervised Prediction of Information Diffusion in GitHub
Oct 17, 2019


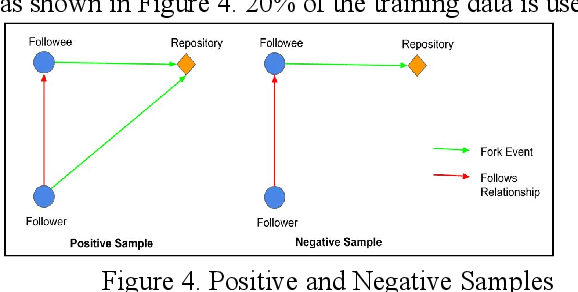
Information spreads on complex social networks extremely fast, in other words, a piece of information can go viral within no time. Often it is hard to barricade this diffusion prior to the significant occurrence of chaos, be it a social media or an online coding platform. GitHub is one such trending online focal point for any business to reach their potential contributors and customers, simultaneously. By exploiting such software development paradigm, millions of free software emerged lately in diverse communities. To understand human influence, information spread and evolution of transmitted information among assorted users in GitHub, we developed a deep neural network model: DeepFork, a supervised machine learning based approach that aims to predict information diffusion in complex social networks; considering node as well as topological features. In our empirical studies, we observed that information diffusion can be detected by link prediction using supervised learning. DeepFork outperforms other machine learning models as it better learns the discriminative patterns from the input features. DeepFork aids in understanding information spread and evolution through a bipartite network of users and repositories i.e., information flow from a user to repository to user.